文章地址: http://openaccess.thecvf.com/content_ECCV_2018/html/Juncheng_Li_Multi-scale_Residual_Network_ECCV_2018_paper.html
作者的项目地址: MSRN-PyTorch
1 简单介绍
在这篇论文中,作者从重建经典的超分辨率模型开始讲起,包括SRCNN、EDSR和SRResNet这些已知的经典模型。基于这些重建实验,研究人员认为这些模型具有一些共同点:
- 难以重现。可能网络性能的提升不是由于网络本身提高的,而可能是使用某种特殊的训练技巧。
- 特征利用率不足。现在的SR方法只是盲目的提高层数,没有充分的利用特征。
- 可扩展性差,往往对尺寸的鲁棒性比较差。
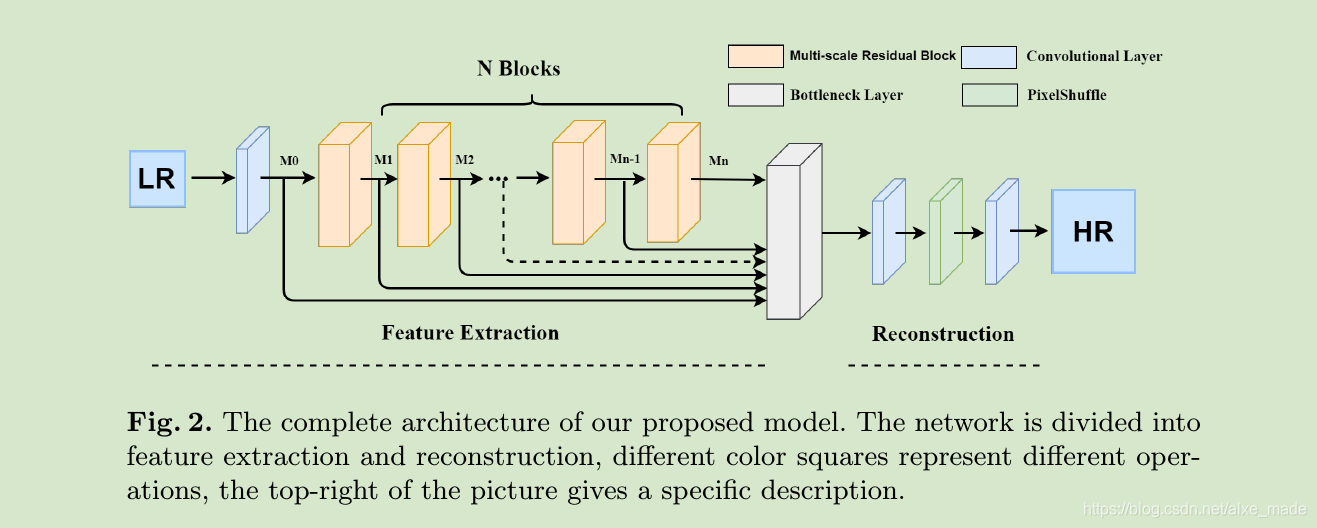
所以,研究人员提出了一种新型的网络架构,并称之为多尺度残差网络(Multi-scale residual network,MSRN)。他是由两个部分组成:特征提取模块和重建模块。其中特征提取模块包含了一个浅层的CNN提取层还有N个(论文中使用8个)级联的MSRB模块。然后将前面(N+1)层concatenate起来,作者称为Hierarchical Feature Fusion Structure(HFFS)。这个操作可以参考我之前的文章深度学习中的concatenate使用。每个多尺度残差网络的输出都被用作全局特征融合的分层特征,最终,所有这些特征都在重建模型中用于修复高分辨率图像。在重建阶段,依次通过conv->pixelshuffle->conv层。
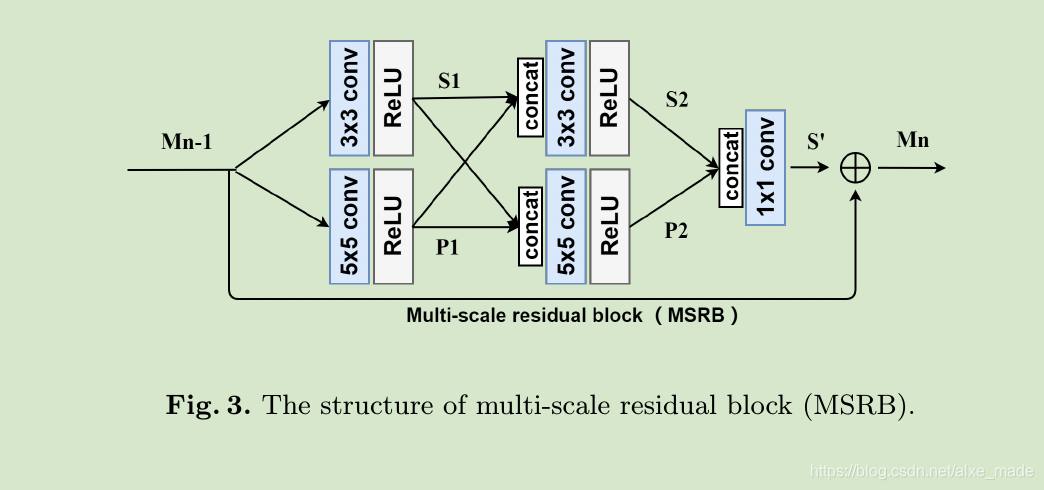
我们的 Multi-scale Residual Block (MSRB)由两部分构成:多尺度特征融合和局部残差学习,可以用不同大小的卷积核来适应性检测不同规模的图像特征。在MSRB中我们使用了1×1的conv,它有两个作用:其一是降低网络的参数,其二就是联合3×3和5×5卷积核帮助我们获取多尺度的信息。采用局部残差学习法可以让神经网络更高效。
另外作者为了证明性能的提升只是由网络带来的,不使用VGG损失、Charbonnier Penalty function(一种L1损失的变种,在LapSRN首次作为损失函数使用)以及L2损失(会导致重建结果过于光滑),而是使用L1的损失函数。也没有使用特别的权重初始化方法以及其他特殊的训练技巧,只是为了对比的公正性。
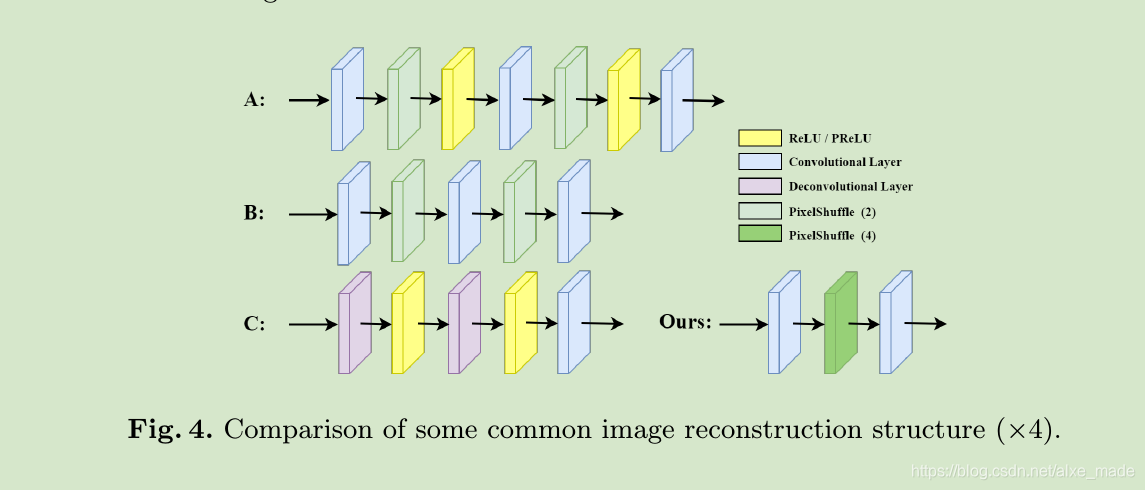
在重建模块中,作者没有使用通用的方法,比如单纯堆叠pixelshuffle层或者使用deconv层,而是直接使用conv->pixelshuffle->conv结构,仅仅使用一个pixelshuffle层,只要微调其中的参数就可以达到任意我们想要达到scale。比如x2,x3,x4,x5等等。
2 重建效果
作者在没有任何初始化或技巧的情况下,用DIV2K数据集训练网络,证明了这可以解决我们上述提到的第一问题:复现性差。
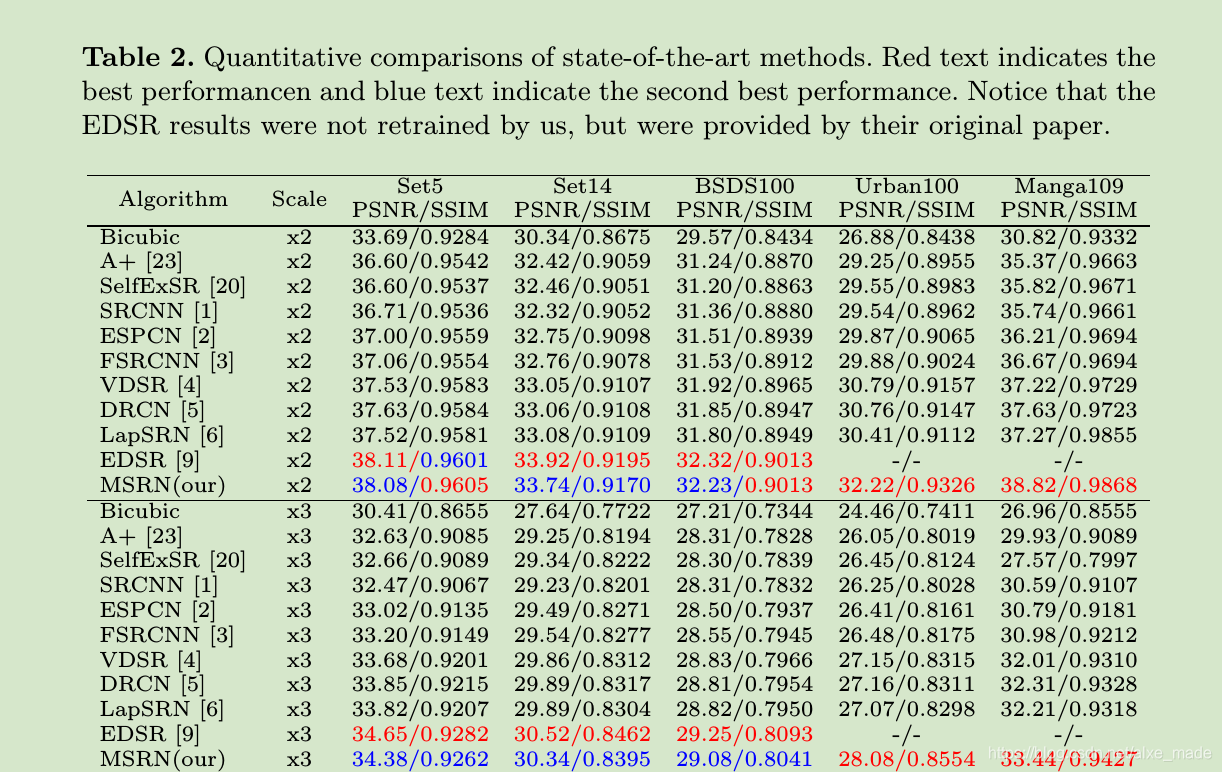
从图中可以看出,我们的MSRN竟然比不过EDSR。作者从两个方面解释原因:我们的MSRN训练过程是使用YCbCr颜色空间的luminance通道(单通道),而EDSR使用RGB通道进行训练。另外就是我们的网络比EDSR小,参数量更小。

另外从视觉效果上也是不错的。但是作者好像没有对比EDSR~
在其他低级计算机视觉的任务中的结果也可以拿来对比,这个方法对作者来说最大的意义就是开创了一个用于图像修复的单个多任务模型。

作者是使用Pytorch框架的,在新发布的代码中是借鉴了RCAN这个代码,而RCAN代码又是借鉴EDSR代码的。
3 感想
个人感觉作者有两点创新:第一点就是使用MSRB模块(核心就是使用不同尺寸的卷积核)融合多尺度的信息,第二点就是使用一个pixelshuffle层可以很方便扩展SR的分辨尺寸。