题目:Image Super-Resolution Using Very DeepResidual Channel Attention Networks
中文:使用深度残差通道注意网络的图像超分辨率

摘要:
背景:卷积网络越深,效果越好,但是同时带来一个问题就是难以训练。并且低分辨输入包含的丰富的低频信息被平等处理,阻碍了超分辨过程,
目的:
方法:加深网络,提出残差块,使用跳跃链接。提出通道注意力机制。我们试图尽可能多地恢复高频信息。LR图像包含的大部分低频信息可以直接转发。无区别对待每个通道,限制了网络的表达能力,提出CA方法(后面会讲到)
结论:我们的RCAN相对于最新方法具有更好的准确性和视觉效果。
- 卷积神经网络(CNN)的深度对于图像超分辨率(SR)至关重要。但是,我们观察到用于图像SR的更深层网络更难训练。
低分辨率输入和特征包含丰富的低频信息,该信息在通道之间均受到平等对待,因此阻碍了CNN的重现能力。为了解决这些问题,我们提出了非常深的残差通道注意力网络(RCAN)。具体而言,我们提出了残差残差(RIR)结构以形成非常深的网络,该网络由几个具有较长跳过连接的残差组组成。每个残差组都包含一些具有短跳跃连接的残差块。同时,RIR允许通过多个跳过连接来绕过丰富的低频信息,从而使主网络专注于学习高频信息。此外,我们提出了一种通道注意机制,通过考虑通道之间的相互依赖性来自适应地重新调整通道方式的特征。广泛的实验表明,我们的RCAN相对于最新方法具有更好的准确性和视觉效果。
引言
引出单一图像超分辨,且此问题是不适定问题。
- 给定低分辨率(LR)图像,我们解决了重建准确的高分辨率(HR)图像的问题,通常称为单图像超分辨率(SR)[8]。图像SR用于各种计算机视觉应用,范围从安全和监视成像[45],医学成像[33]到物体识别[31]。然而,图像SR是一个不适定的问题,**因为对于任何LR输入都存在多种解决方案。**为了解决这种逆问题,已经提出了许多基于学习的方法来学习LR图像和HR图像对之间的映射。
深度学习的方法很好,并且网络深度对于SR至关重要,但是仅仅靠堆叠残差块改善很小,需要探索更加好的方法去构建深层网络。
- 近年来,基于深度卷积神经网络(CNN)的方法[5,6,10,16,19,20,23,31,34,35,39,42-44]相对于常规SR方法已取得了显着改进。其中,Dong等。 [4]提出了SRCNN,它首先引入了用于图像SR的三层CNN。 Kim等。在VDSR [16]和DRCN [17]中将网络深度增加到20,实现了SRCNN的显着改进。网络深度被证明对于任何视觉识别任务都是至关重要的,尤其是当他等人。 [11]提出了残差网(ResNet)。然后,在许多其他基于CNN的图像SR方法中引入了这种有效的残差学习策[21,23,31,34,35]。 Lim等。 [23]通过使用简化的残差块,建立了一个非常宽的网络EDSR和一个很深的MDSR。
EDSR和MDSR性能的巨大提高表明表示深度对于图像SR至关重要。但是,据我们所知,仅堆叠残差块来构建更深的网络几乎无法获得更好的改善。更深层的网络能否进一步促进图像SR以及如何构建非常深层的网络仍有待探索。
最近CNN方法平等对待所有通道的特征,效果差。
- 另一方面,最近的基于CNN的方法[5,6,16,19,20,23,31,34,35,39,43]
均等地对待通道特征,而对于不同类型的方法缺乏灵活性信息。可以将图像SR视为一个过程,在此过程中,我们尝试恢复尽可能多的高频信息。 LR包含大多数低频信息,这些信息可以直接转发到最终的HR输出。同时,基于CNN的领先方法会同等对待每个通道特征,缺乏跨功能通道的判别性学习能力,并阻碍了深度网络的表示能力。
提出解决方案,使用残差通道注意网络
- 为了切实解决这些问题,我们提出了一种残差通道注意网络(RCAN),以获得非常深的可训练网络,并同时自适应地学习更多有用的通道方式特征。为了简化非常深的网络(例如,超过400层)的训练,我们提出了残差残差(RIR)结构,其中残差组(RG)作为基本模块,长跳过连接(LSC)允许残差学习在较粗的层次上进行。在每个RG模块中,我们堆叠了几个带有短跳过连接(SSC)的简化残差块[23]。长跳过和短跳过连接以及残差块的捷径允许通过这些基于身份的信息绕过大量低频信息,可以简化信息流。为了进一步采取措施,我们提出了通道注意(CA)机制,通过对跨功能通道的相互依赖性进行建模来自适应地重新调整每个通道的特征。这种CA机制使我们提出的网络能够专注于更多有用的通道并增强判别性学习能力。如图1所示,与最新方法相比,我们的RCAN可获得更好的视觉SR结果。
贡献
- 总体而言,我们的贡献可分为三方面:(1)我们提出了非常深的残留通道注意网络(RCAN),以实现高精度的图像SR。 (2)我们提出了残差(RIR)结构来构建非常深的可训练网络。 (3)我们提出了通道注意(CA)机制,通过考虑特征通道之间的相互依赖性来自适应地重新缩放功能
相关工作
注意力机制一般用于高级视觉任务,不常用于低级视觉任务中。
- 在计算机视觉界已经研究了许多图像SR方法[5,6,13,16,19,20,23,31,34,35,39,43]。注意机制在高级视觉任务中很流行,但很少在低级视觉应用中研究[12]。由于篇幅所限,我们在此重点介绍与基于CNN的方法和注意力机制相关的作品。
先将LR插值到目标尺寸大小,会丢失大量细节。且增加计算量。
- Deep CNN for SR.Dong等人完成了开创性工作。 [4]为图像SR提出了SRCNN并取得了优于先前作品的出色性能。 SRCNN在VDSR [16]和DRCN [17]中得到了进一步的改进。这些方法首先将LR输入插值到目标大小,这不可避免地**会丢失一些细节并大大增加计算量。**从原始的LR输入中提取特征并在网络尾端提升空间分辨率成为了深度架构的主要选择。为了加快SRCNN的训练和测试速度,提出了一种更快的网络结构FSR-CNN [6]。 Lediget al。 [21]引入ResNet [11]以建立具有感官损失的更深网络[15]和生成对抗网络(GAN)[9]来实现真实感SR。但是,这些方法大多数都限制了网络深度,这证明了在视觉识别任务中非常重要[11]。此外,大多数这些方法均等地对待通道特征,从而阻碍了对不同特征更好的判别能力。
- 注意力机制。通常,
注意可以看作是将可用处理资源的分配偏向输入中最具信息性的组成部分的指导[12]。最近,已提出尝试性工作以将注意力投入到深度神经网络[12,22,38],范围从图像的定位和理解[3,14]到基于序列的网络[2,26]。它通常与选通功能(例如S型)结合使用以重新缩放功能图。 Wang等。文献[38]提出了一种带有躯干和面具注意机制的用于图像分类的剩余注意力网络。 Hu等。 [12]提出了挤压和激励(SE)块来模拟通道之间的关系,以获得显着的图像分类性能改善。然而,很少有人研究注意力对低级视觉任务(例如图像SR)的影响。

3、残差通道注意网络(RCAN)
3.1网络结构
- 如图2所示,我们的RCAN主要包括四个部分:浅层特征提取,残差(RIR)深层特征提取,高级模块和重建部分。LR和HR分别表示输入和输出。正如在[21,23]中研究的那样,我们仅使用一个卷积层(Conv)从LR输入中提取浅层特征F0。

- 其中,HSF(·)表示卷积运算。然后,将F0与RIR模块一起用于深度特征提取。所以我们可以进一步拥有

- 其中HRIR(·)表示残差结构中非常深的残差,其中包含残差组(RG)。据我们所知,我们提出的RIR达到了迄今为止最大的深度,并提供了非常大的感受野大小。因此,我们将其输出视为深度特征,然后通过一个上采样模块将其进行放大。

- HUP(·)和FUP分别表示一个上采样模块和一个上采样特征。
- 有多种选择可以用作上采样模块,例如反卷积层(也称为转置卷积)[6],最近邻upsam-pling +卷积[7]和ESPCN [32]。与升级前的SR方法(例如DRRN [34]和Mem-Net [35])相比,这种升级后的策略在计算复杂度和实现更高的性能方面都得到了证明。然后,通过一个Conv层重建放大的特征。
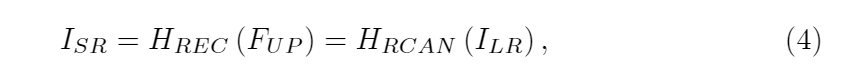
- 其中HREC(·)和HRCAN(·)分别表示重构层和RCAN的功能。
- 然后用损失函数优化RCAN。已经研究了几种损失函数,例如L2 [5,6,10,16,31,34,35,39,43],L1 [19,20,23,44],感知损失和对抗损失[21,31] 。为了展示我们的RCAN的有效性,我们选择优化与先前工作相同的损失函数(例如,L1损失函数)。给定训练集{IiLR,IiHR} Ni = 1,其中包含NLR输入及其HR对应物。训练RCAN的目标是最大程度地降低L1损失功能

- 其中Θ表示我们网络的参数集。通过使用随机梯度下降来优化损失函数。有关培训的更多详细信息,请参见第4.1节。由于我们选择浅层特征提取HSF(·),上采样模块HUP(·)和重构模块HUP(·)的方式与以前的工作类似(例如EDSR [23]和RDN [44]),因此我们更加关注我们提出的RIR, CA和基本模块RCAB。
3.2残差结构RIR
- 现在,我们提供RIR结构(请参见图2)的更多详细信息,该结构包含残差组(RG)和跳跃连接(LSC)。每个RG还包含带有短跳过连接(SSC)的残差通道注意块(RCAB)。这种残差结构中的残差允许训练非常深的CNN(超过400层)以实现具有高性能的图像SR。
- 在[23]中,已经证明可以使用堆叠的残差块和LSC(长跳跃连接)来构建深层的CNN。在视觉识别中,可以将残余块[11]堆叠起来以实现1000多个可训练网络。但是,以这种方式构建的非常深的网络在SR会遭受训练困难,并且几乎无法获得更多的性能提升。受SRRestNet [21]和EDSR [23]以前工作的启发,我们提出了残差组(RG)作为更深层网络的基本模块。第g组中的RG表示为
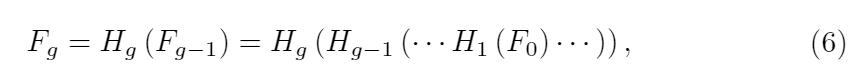
- 其中Hg表示第g个RG函数。Fg-1和Fg是输入和输出第RG个函数。我们观察到,简单地堆叠许多RG将无法实现更好的性能。为了解决该问题,RIR中进一步引入了长跳连接(LSC),以稳定非常深层网络的训练。 LSC还可以通过残差学习使更好的性能成为可能
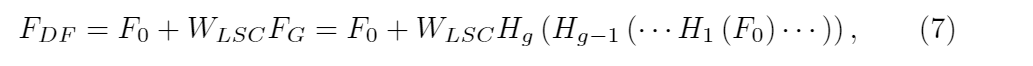
- 其中WLSC是设置为RIR尾部的Conv层的权重。为简单起见,省略了偏见项。 LSC不仅可以缓解RG中的信息流,而且使RIR可以粗略地学习残差信息。
- 如第1节所述,LR输入和特征中有大量丰富的信息,而SR网络的目标是恢复更多有用的信息。可以通过基于身份的跳过连接来绕过大量的低频信息。为了进一步迈向残差学习,我们在每个RG中堆叠了残差通道注意块。可以将第b个剩余信道注意块(RCAB)和第RG公式表示为

- 其中Fg,b-1和Fg,b是第RCAB和第RG的输入和输出。相应的功能用Hg,b表示。为了使主网络更加关注更多信息功能,引入了短跳过连接(SSC)以通过以下方式获取块输出

- 其中,权重设置为第g个RG尾部的Conv层。 SSC还允许网络的主要部分学习残差信息。借助LSC和SSC,在训练过程中更容易绕过更丰富的低频信息。为了朝着更具判别力的学习迈出进一步的一步,我们更加关注通过渠道关注而对渠道方式的特征缩放。
3.3 通道注意力
- 以前的基于CNN的SR方法均等地对待LR通道特征,这对于实际情况而言并不灵活。为了使网络专注于更具信息性的功能,我们利用了功能通道之间的相互依赖性,从而形成了通道注意(CA)机制(请参见图3)。

class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
# x就是 HxWxC 通道 y是权重
# y权重通过上面方式求出,然后 和x求乘积
#使得重要通道权重更大,不重要通道权重减小
————————————————
版权声明:本文为CSDN博主「唯我视你为青山」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/aaa958099161/article/details/82836846

- 如何为每个通道生成不同的注意力是关键步骤。这里我们主要有两个问题:首先,LR空间中的信息具有丰富的低频成分和有价值的高频成分,低频成分似乎更加笼统。高频分量通常将是区域,充满边缘,纹理和其他细节。另一方面,Conv层中的每个滤波器都以局部感受野运行。因此,卷积后的输出无法利用本地区域以外的上下文信息。
- 基于这些分析,我们通过使用全局平均池化将信道方式的全局空间信息带入信道描述符。如图3所示,letX = [x1,···,xc,···,xC]是一个输入,具有C个大小为H×W的特征图。可以通过将X缩小到空间尺寸H×W来获得通道统计量z∈RC。然后z的第c个元素由下面公式定义:

- 其中xc(i,j)是第c个特征xc在位置(i,j)的值。HGP(·)表示全局池化函数。这样的信道统计可以看作是局部描述符的集合,它们的统计有助于表达整个图像[12]。除了全局平均池之外,这里还可以引入更复杂的聚合技术。
- 为了
通过全局平均池化从聚合信息中完全捕获通道方式的依赖性,我们引入了门控机制。如[12]中讨论的,门控机制应满足两个条件:首先,它必须能够学习通道之间的非线性相互作用。其次,由于可以强调多个通道方式的特征,而不是一键激活,因此它必须学习一种非相互排斥的关系。在这里,我们选择利用具有S形函数的简单门控机制为了通过全局平均池从聚合信息中完全捕获通道方式的依赖性,我们引入了门控机制。
- 其中,f(·)和δ(·)分别表示S型门控和ReLU [27]函数。在被ReLU激活后,低维信号随比例r通过通道放大层(其权重设置为WU)增加。然后,我们获得最终的通道统计信息,该统计信息用于重新缩放输入xc

- 其中sc和xc关心第c个通道中的比例因子和特征图。在注意力机制下,RCAB中的残差组件会自适应调整比例。
结论
- 我们提出了非常深的残留通道注意网络(RCAN),以实现高精度的图像SR。具体而言,残差(RIR)结构允许RCAN使用LSC和SSC达到非常大的深度。同时,RIR允许
通过多跳连接来绕过大量的低频信息,从而使主网络专注于学习高频信息。此外,为了提高网络的能力,**我们提出了通道注意(CA)机制来自适应地重新调整通道规模。**通过考虑通道之间的相互依赖性来实现明智的功能。利用BI和BD模型对SR进行的大量实验证明了我们提出的RCAN的有效性。 RCAN还显示了用于对象识别的正确结果。 - 文章的重点部分是引入通道注意力机制,自适应的给各个通道分配权重。