目录
7.1 过拟合问题(The Problem of Overfitting)
7.3 正则化线性回归(Regularized Linear Regression)
7.4 正则化的逻辑回归(Regularized Logistic Regression)
七、正则化(Regularization)
7.1 过拟合问题(The Problem of Overfitting)
如果我们有非常多的特征,通过学习得到的模型可能非常好的适应训练集(代价函数几乎为0),但不能很好地对新的数据的进行预测。
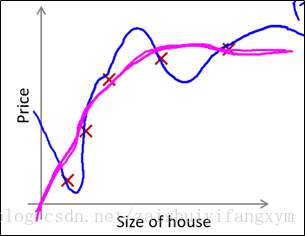
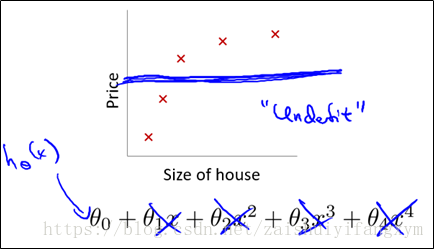
(1)下图是一个回归问题的例子
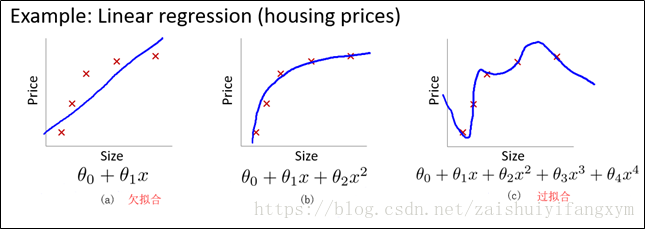

以房屋价格为例:
图(a) 回归模型是一个“欠拟合”(under-fitting)模型,不能很好地适应训练集,更别提对新的数据进行预测。
图(c) 回归模型是一个“过拟合”(overfitting)模型,由于过于强调拟合训练数据,而丢失了算法的本质,在预测新的数据时,其不能够很好地预测。并且从客观角度出发,房屋价格会随着房屋尺寸大小增大而增大,应该是一个整体递增的趋势。
图(b) 回归模型就刚刚好,能很好的适应训练集,并且能反映变化趋势。
(2)下图是一个分类的例子
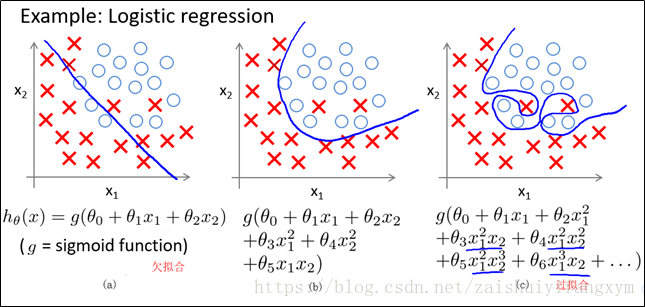
图(a) 分类模型是一个“欠拟合”(under-fitting)模型;
图(c) 分类模型是一个“过拟合”(overfitting)模型;
图(b) 分类模型刚刚好。
过拟合(Overfitting)通常指当模型中的特征太多时,模型对训练集数据能够很好的拟合(此时代价函数J(θ)接近于0),然而当模型泛化(generalize)到新的数据时,模型的预测表现很差。
那么问题来了,如果我们发现了过拟合问题,我应该怎么办?
过拟合(Overfitting)的解决方案
(1)减少特征数量
人工选择重要特征,丢弃不必要的特征;
利用算法进行选择(PCA算法等)。
(2)正则化(Regularization)
保持特征的数量不变,但是减少参数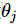
7.2 代价函数(Cost Function)
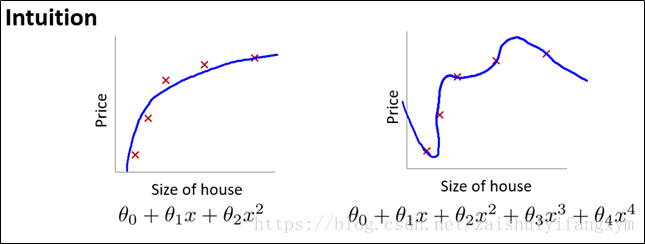
上图是前面过拟合的例子,可以看出,正式那些高次项(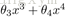
所以我们要做的就是在一定程度上减小参数θ的值,这就是正则化的基本思想。我们要修改代价函数,其中使得
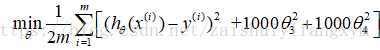
对于上面的例子,只要
但是,上面的代价函数仅仅针对上面的例子,其实在真正的计算中,我们并不知道,惩罚什么参数合适,也不知道什么样的参数才是最佳。
所以针对一般情况,我们加入惩罚项,修改代价函数如下:

注意:惩罚项从j=1开始,因为第0个特征是全为1向量,不需要惩罚。
其中,λ为称为正则化参数(Regularization Parameter) 。
值得注意的是:正则化参数λ过大,会把所有的参数都最小化,导致模型变成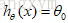
所以取合适的正则化参数λ的值,才能更好地应用正则化,使得数据正确的进行拟合。
7.3 正则化线性回归(Regularized Linear Regression)
线性回归中,我们提到两种方法,梯度下降法和正规方程法。下面将一次介绍正则化后使用梯度下降法和正规方程法。
1 梯度下降法
正则化线性回归的代价函数为:

下图是对于没有正则化,使用梯度下降法的得到的参数
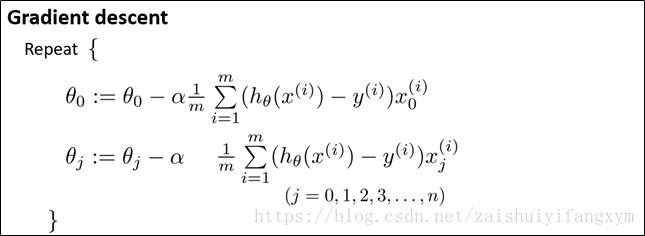
那么正则化后,梯度下降法表达式如下图所示:

对上面算法中的 j=1,2,3,…,n时更新的式子调整得到:
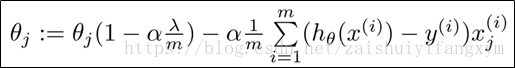
可以看出,正则化线性回归的梯度下降法的变化在于,每次都在原有算法更新规则的基础上,令参数θ值减少了一个额外的值。
同样,也可以利用正规方程来求解正规化线性回归模型。
2 正规方程法

最终求解得到参数θ值如下图所示:

7.4 正则化的逻辑回归(Regularized Logistic Regression)
对于逻辑回归,我们也修改了代价函数,其代价如下:
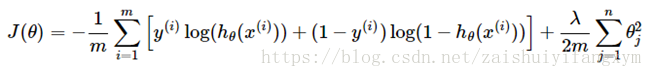
要最小化代价函数,使用梯度下降法得到:

注意:看上去和线性回归类似,其实这里的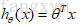
参考资料
[1] Andrew Ng Coursera 机器学习 第三周 PPT
[2] https://blog.csdn.net/mydear_11000/article/details/50865094
[3] https://www.cnblogs.com/python27/p/MachineLearningWeek03.html