目录
6.2 假设表示(Hypothesis Representation)
6.5 简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)
6.6 高级优化(Advanced Optimization)
6.7 多元分类:一对多(Multiclass Classification: One-Vs-All)
六、逻辑回归(Logistic Regression)
6.1 分类(Classification)
分类问题(Classification problems),也就是你想预测的值是一个离散的值。
我们会使用逻辑回归(Logistic Regression)算法来解决分类问题。
之前,我们讨论的垃圾邮件分类实际上就是一个分类问题。类似的例子还有很多,例如一个在线交易网站判断一次交易是否带有欺诈性。再如,之前判断一个肿瘤是良性的还是恶性的,也是一个分类问题。
在以上的这些例子中,属于二元分类,我们想预测的是一个二值的变量,或者为0,或者为1;或者是一封垃圾邮件,或者不是;或者是带有欺诈性的交易,或者不是;或者是一个恶性肿瘤,或者不是。
我们可以将因变量可能属于的两个类分别称为负向类(Negative Class)和正向类(Positive Class)。可以使用“0”来代表负向类,“1”来代表正向类。现在,我们的分类问题仅仅局限在两类上:0或者1。之后会讨论多分类问题,也就是说,预测的变量可以取多个值,例如0,1,2,3。
那么,我们如何来解决一个分类问题呢?首先从二元分类问题开始讨论,看以下例子:
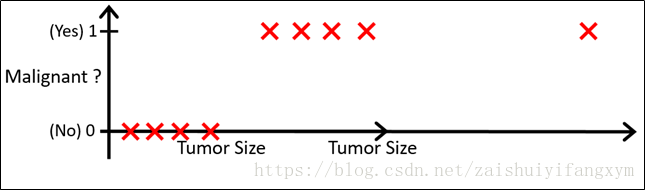
现在有一个分类任务,需要根据肿瘤大小来判断肿瘤的良性与否。训练集如上图所示,横轴代表肿瘤大小,纵轴表示肿瘤的良性与否,注意,纵轴只有两个取值,“1”(代表恶性肿瘤)和“0”(代表良性肿瘤)。
对于以上数据集使用线性回归来处理,实际上就是用一条直线去拟合这些数据。因此,你得到的 直线可能如下图所示:
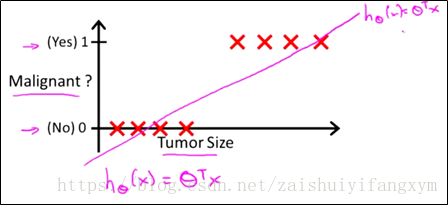
根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们只需要离散值“0”或“1”。我们可以这样预测:

对于上面的数据,我们使用一个线性回归模型做出了预测分类,似乎很好地完成了分类任务。难道真的就这么简单吗? 现在,我们对以上问题稍作一些改动。将横轴向右扩展,并且增加一个训练样本,如下图所示:
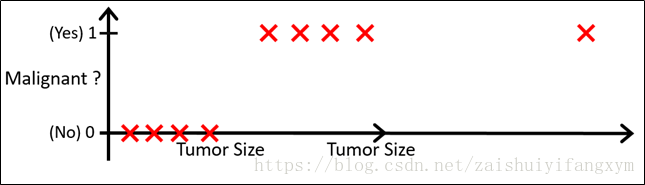
那么,使用刚才的线性回归模型,会得到一条新的直线:
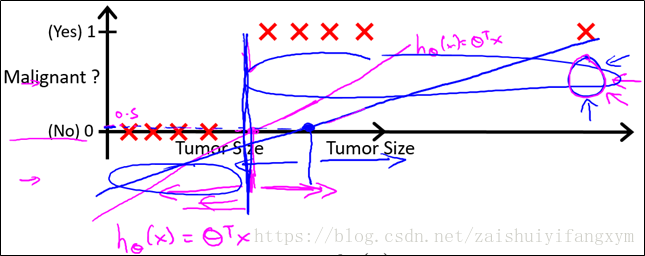
此时,我们再用刚才所用的0.5作为阈值来预测肿瘤的良性还是恶性,就不合适了。可以看出,线性回归模型,因为其预测的值可以超过[0,1]的范围,并不适合解决分类问题。
所以,针对分类问题,我们将使用新的模型:逻辑回归(Logistic Regression)。下一节我们将展开叙述。
6.2 假设表示(Hypothesis Representation)
对于分类问题,我们引入新的模型:逻辑回归(Logistic Regression) 该模型的输出变量范围始终在[0,1]之间。
我们在之前的线性回归模型的假设表示(Hypothesis Representation):
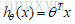
而现在的逻辑回归模型的假设表示(Hypothesis Representation) :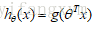
g(.)表示逻辑函数(Logistic function):是一个常用的逻辑函数:S形函数(Sigmoid function),一般逻辑函数就等同于S形函数。
这里的逻辑回归(Logistic function)是一种分类算法,不要与线性回归弄混淆。
S形函数(Sigmoid function)表达式和曲线如下:
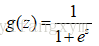
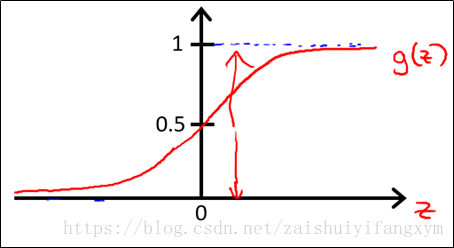
则逻辑回归模型为:
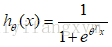
可以看出预测值y的取值范围是[0,1],对于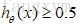
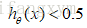
值得注意的是: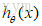
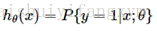
此外由于y只能取“0”或“1”两个值,换句话说,一个数据要么属于0分类要么属于1分类,假设已经知道了属于1分类的概率是p,那么当然其属于0分类的概率则为1-p,这样我们有以下结论:
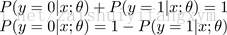
例如:如果对于给定的x,通过已经确定的参数计算得到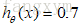
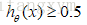
6.3 决策边界(Decision Boundary)
在逻辑回归中,我们预测:
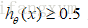
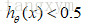
那么:

现在举个例子方便我们理解:
已知下图的数据,现要将其分类,需要用到逻辑回归模型。
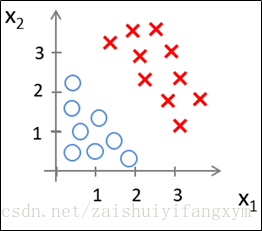
假设现在有一个逻辑回归模型:
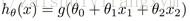
将参数θ带入到假设模型中得到:
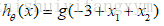
那么,根据上面的式子:
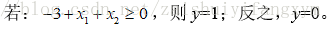
得到上面的参数,现在可以绘制
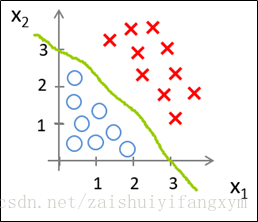
从上图可以看出,合适的参数θ将数据成功的分开,这条绿色线就是模型的分界线,就是决策边界(Decision Boundary),将预测为1的区域和预测为0 的区域分开。
下面再看一个例子:如下图的数据,用逻辑回归模型,参数怎样设置,才能适应决策边界?
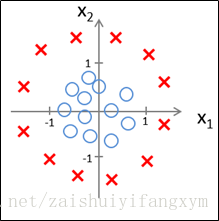
因为要用曲线才能分开y=0的区域和y=1的区域,我们需要借助二次方参数特征:假设参数:
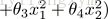
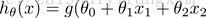
根据以上参数,我们得到决策边界恰好是以原点为中心,半径为1的圆。如下图所示:
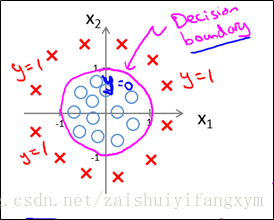
则,这个问题就转化为:

这只是一个例子,恰好可以简单地求出决策边界,并且我们对决策的边界是非常熟悉的曲线方程。
当然,我们参数θ设置越复杂,得到的决策边界会变得复杂。
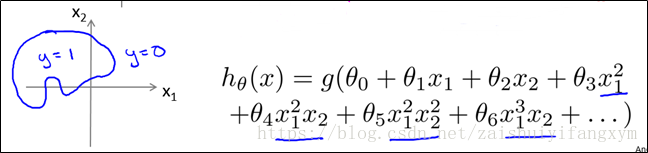
6.4 代价函数(Cost Function)
对于线性回归问题,使用线性回归模型,我么定义代价函数是误差的平方和。同样的,理论上说,我们对分类问题,使用逻辑回归模型的也定义代价函数的误差的平方和,但是这里有个问题出现了。
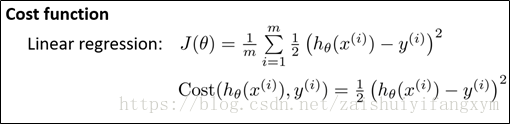
我们将假设(Hypothesis) :
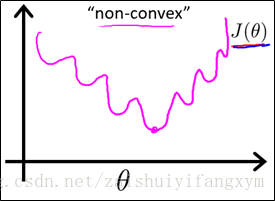
凸函数(convex function),只有一个最小值,也是我们最想要得到的,在梯度下降法中,将很快的寻找到全局最小值,凸函数曲线如下图所示:
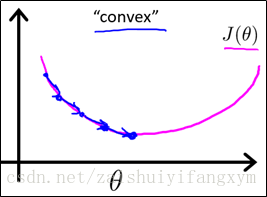
因此,要是能使代价函数转化为凸函数,问题就迎刃而解了。那么问题来了,用什么方法将非凸函数转化为凸函数呢?
现在,我们重新定义逻辑回归模型的代价函数(Cost Function):
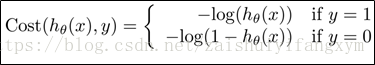
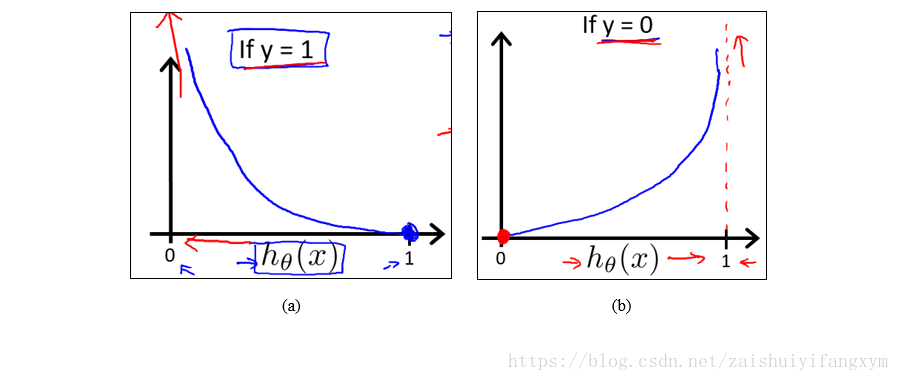
如下图所示,使用对数函数,对数函数是一个单调函数,并且:
可以看到,当y=1,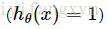
反之,y=0,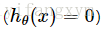
6.5 简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)
前面,我们构建了逻辑回归代价函数,其表达式为:
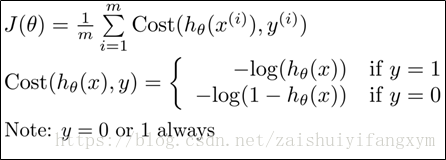
这样构建的代价函数特点是:
当y=1且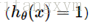
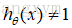
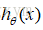
当y=0且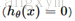
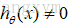
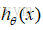
前面的代价函数是分段函数,为了使得计算起来更加方便,可以将分段函数写成一个函数的形式,即:
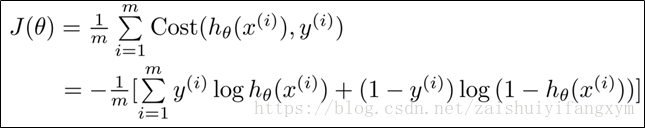
根据代价函数,我们的目的是找到使得代价函数取得全局最小值时的参数θ,最后根据这个参数,在逻辑回归预测模型中,预测得到 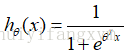
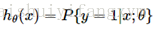
所以,最关键的一步就是如何找到最小值,前面说过,用梯度下降法求最小值。

求导,化简得到:

注意:这里的求解方法和线性回归求解方法看起来类似。其实这里的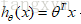
6.6 高级优化(Advanced Optimization)
当然,求出代价函数的最小值的方法有很多,不仅仅只有梯度下降法一个。 除了梯度下降算法,可以采用高级优化算法,例如:共轭梯度(Conjugate Gradient),局部优化法(BFGS),有限内存局部优化法(L-BFGS)等。这些算法优点是不需要手动选择α,比梯度下降算法更快;缺点是算法更加复杂。这些算法Matlab中都有。下面举例进行说明:


6.7 多元分类:一对多(Multiclass Classification: One-Vs-All)
多分类例子,例如:
(1)邮箱自动将邮件进行,分组类别有:同事,朋友,家人,同学等,可以用数字1,2,3,4…分类;
(2)去诊所看病,其分类可以有:正常,感冒,流感等,可以用数字1,2,3,…分类;
(3)预测天气情况,其分类可以有:晴天,多云,下雨,下雪等,可以用数字1,2,3,4…分类;
下图是一个二分类和多分类的数据,多分类可以借助二分类的思想依次做分类。
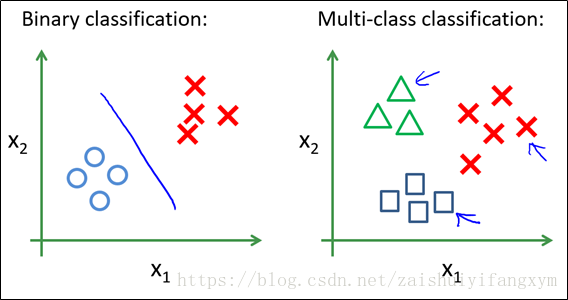
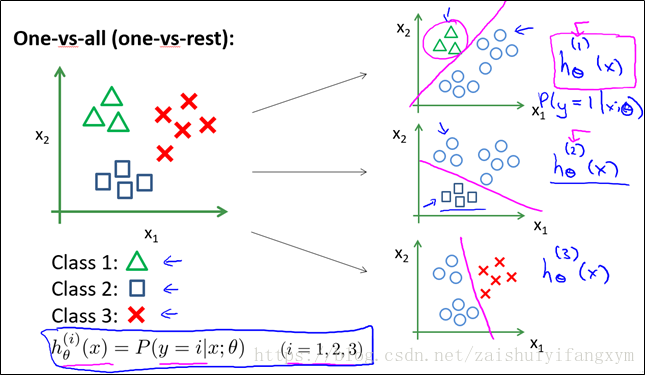

将数据分别进行两两分类,使用二元分类方法得到3个训练好的模型。最后将测试数据输入到模型中去,分别计算其预测值,选择预测值最大的作为其预测分类即可。
一般的:
Logistic回归可以用于多元分类,采用所谓的One-Vs-All方法,具体来说,假设有K个分类{1,2,3,...,K},我们首先训练一个逻辑回归模型将数据分为属于1类的和不属于1类的,接着训练第二个逻辑回归模型,将数据分为属于2类的和不属于2类的,一次类推,直到训练完K个逻辑回归模型。
对于新的数据,我们将其带入K个训练好的模型中,分别其计算其预测值(预测值的大小表示属于某分类的概率),选择预测值最大的那个分类作为其预测分类即可。
参考资料
[1] Andrew Ng Coursera 机器学习 第三周 PPT
[2] https://blog.csdn.net/mydear_11000/article/details/50865094
[3] https://www.cnblogs.com/python27/p/MachineLearningWeek03.html