线性回归算法概述
从一个例子出发:

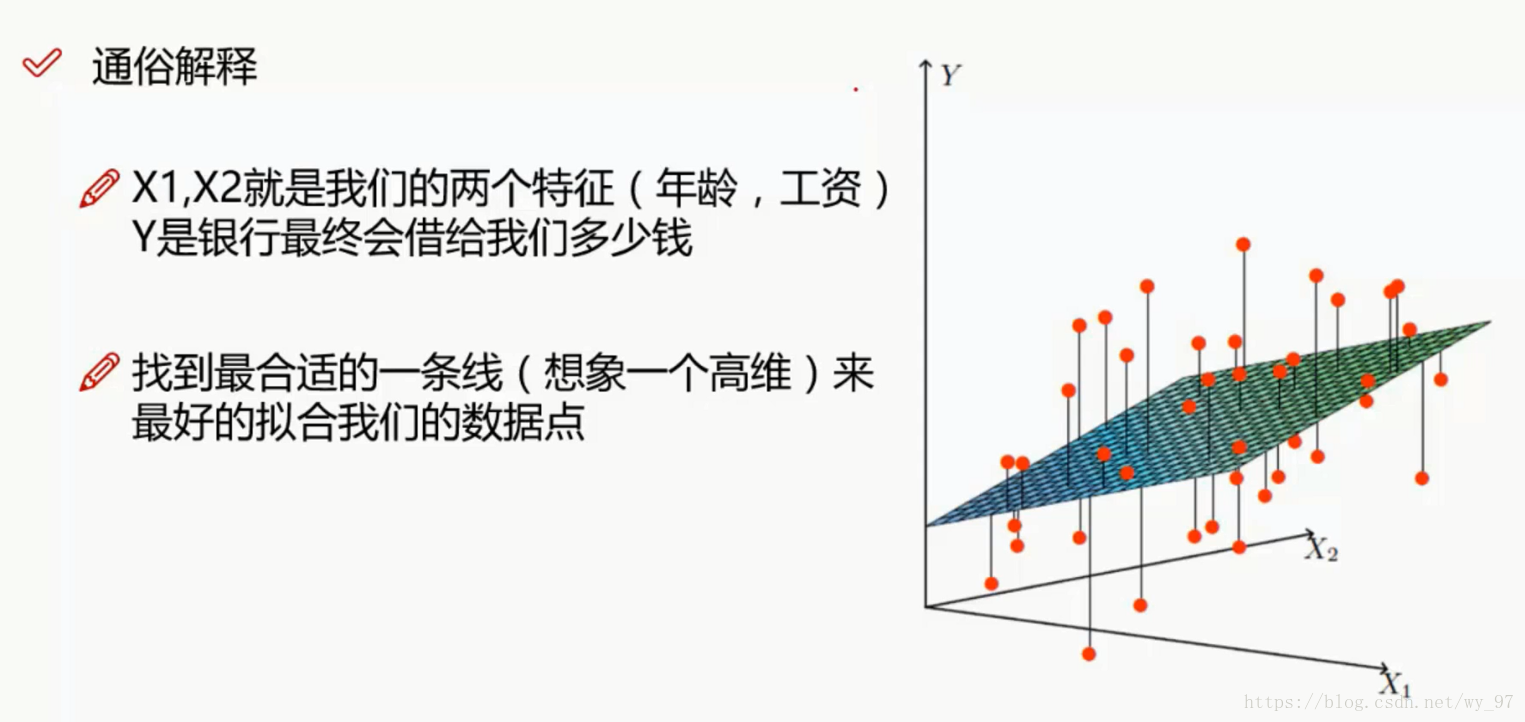
这里假设关系为线性关系:

整合的那个地方将θ_0∗1 ,这样x=1,最终整和成如上形式
PS:为什么要写成这种形式?
运算上矩阵是优于使用for循环进行一行一行的计算,所以机器学习中的数据我们都会将其处理成矩阵形式
误差项分析
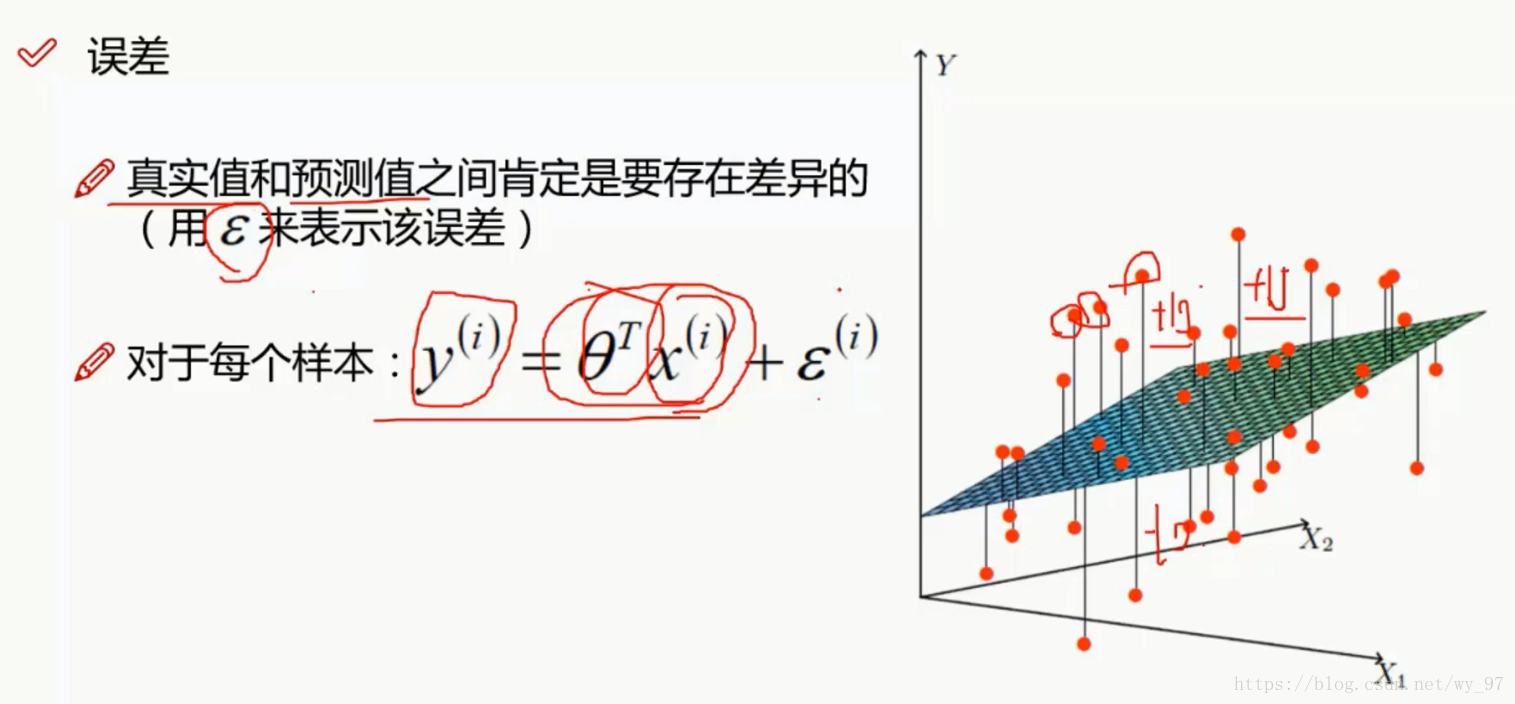
误差定义为ϵ ,解释为对一组x预测出的结果与这组数据真实对应的数据的差值
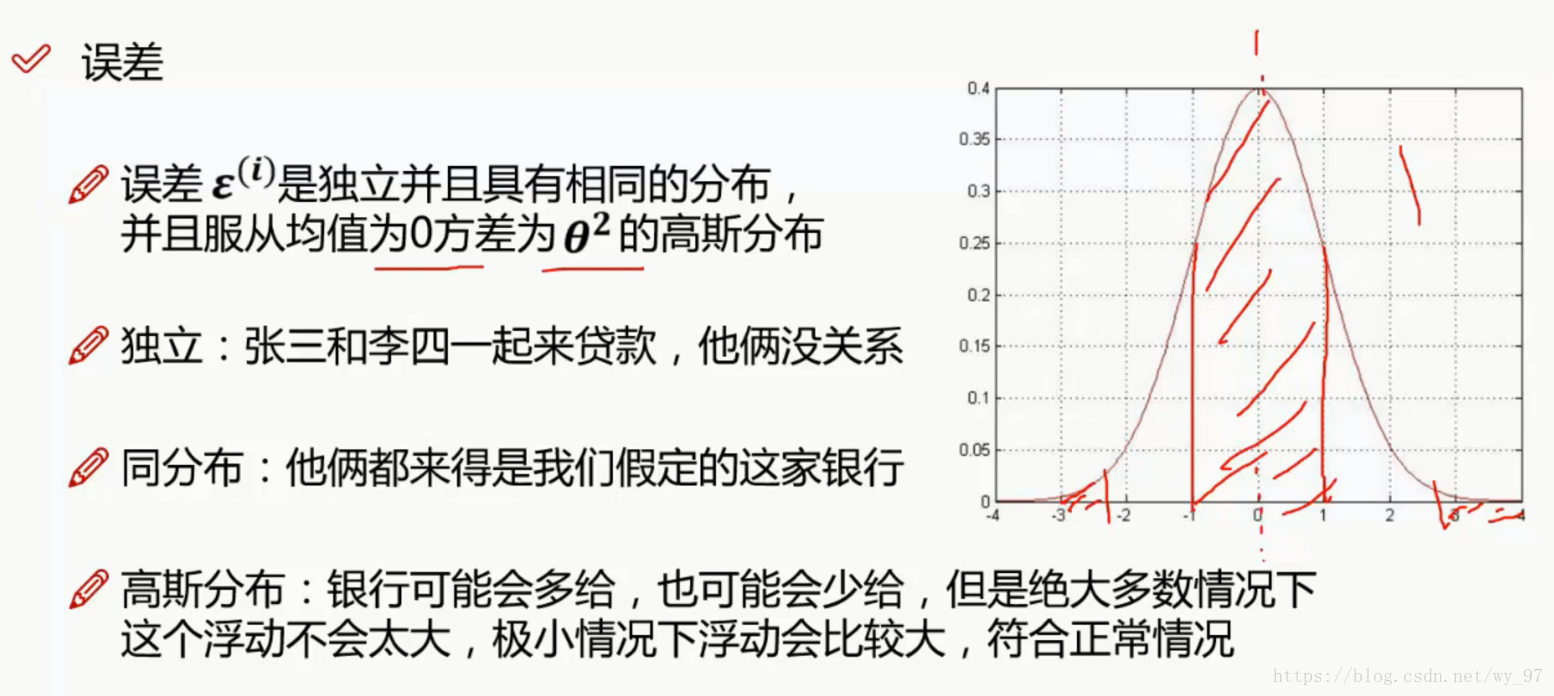
误差的核心,如上所示,有三点:独立,同分布和高斯分布
独立和同分布,是所有机器学习算法的核心前提:
- 独立讲的就是,数据之间不应该有干涉关系,不会因为一组数据的改变,而导致另一组数据的改变
- 同分布是指,数据集针对的要是一个问题的数据,不能说把餐饮时间点人数数据和医院时间点数据放一起,只有数据时针对同一个问题的,才可以放在一起进行分析
高斯分布其实就是正态分布,高中学过的3σ 原则,告诉我们的其实就是数据浮动应该是不大的,越大的偏差的数据应该越少
PS:存在完完全全的独立和同分布么?高斯分布又是如何知道的呢?
当然是不存在完完全全的独立和同分布,收集数据的时候基本无法保证这点,但是,大体上保证即可;高斯分布是我们的一种假设,或许你会说,假设然后去推到结论,这样的结论是否可用,答案是,当然可用,因为结论符合我们预期结果,我们当然可以认为假设是正确的。
似然函数求解

数学不好的自行补习一下正态分布的相关数学知识,百度百科的一维正太分布定义如下:

Exp(a)的意思是e的a次方
回到机器学习部分,(2)式部分μ 我们令为0,其实说白了,这个中心轴是可以调整的
(3)式由(1)式变形带入而来,简写(1)为a =b+c所以c=a-b将这个c也就是ϵ 替换到(2)式即有了(3)式

似然函数的解释可以这样来理解,前面的(3)式是关于误差的正态分布公式(误差使用真实值和估计值的差所代替),我们希望的是误差为零的似然函数尽可能大,为什么说是尽可能大呢?注意似然函数的图像,越大说明误差为零左右的数据越多。这里我们根据(3)式将其进行了一个替换,希望得到关于什么θ 的情况下,似然函数尽可能大。累成的意思则是考虑所有的数据。
目标函数推导
既然拥有累成,这是一个非常大的计算量,我们可以转换成log即对数函数,就可以将乘法转换成一个加法,这就是我们为什么需要对数似然,方便计算,展开化简过程如下:注意下exp(a)=e的a次方就好

故由上述式子,我们得到了目标函数J(θ) ,我们只需要使其最小即可
线性回归求解
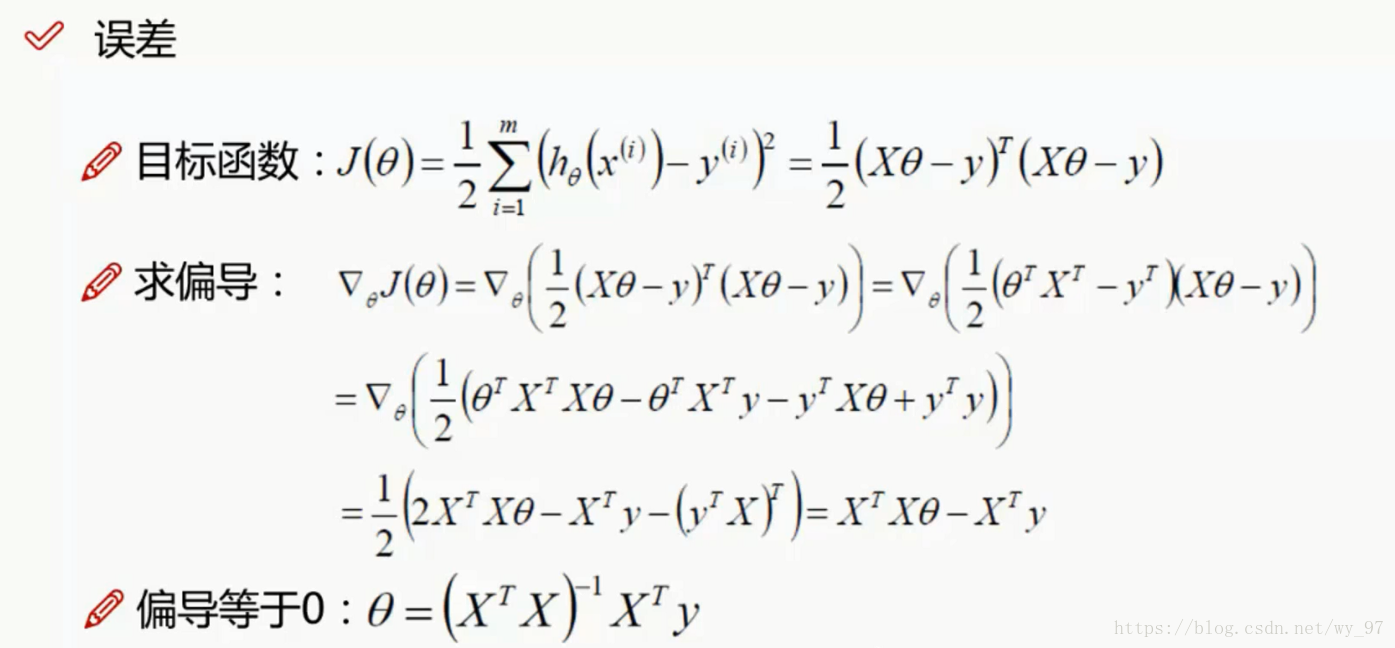
求偏导这里对矩阵进行了偏导计算,参考链接:
https://blog.csdn.net/lirika_777/article/details/79646453
最终我们得到了一个求θ 的表达式,X和Y都是已知的,这样顺利成章便可以得到我们所需要的θ ,注意这是向量,包含了所有θ 。
PS:这样的θ 一定具有意义么?
从大部分的场合来说,是具有意义的,但是这只是数学上的一个巧合,很多时候,根本无法这样去算出θ ,所以我们还得换其他思路。最多的是比如梯度下降算法这样的一个优化的一个思想,而并不是直接求解这样一个思想。
对于θ 我们使用R^2 进行评估:

为什么这样认为呢?
- 当R^2 约等于1,即分子约等于0,也就是说每一项的分子近似0,说明估计值和真实值每一项基本相等,这个结果自然是非常满意的
- 当R^2 约等于0,即分子分母基本相等,分子不等于0,自然是不好的