一、普通线性回归
关键词;最小二乘法,线性
1.原理
线性回归就是在求方程,线性方程:y = kx + b
分类的目标变量是标称型数据,而回归将会对连续型的数据做出预测。
应当怎样从一大堆数据里求出回归方程呢?
假定输人数据存放在矩阵X中,而回归系数存放在向量W中。那么对于给定的数据X1, 预测结果将会通过
Y=X*W给出。现在的问题是,手里有一些X和对应的Y,怎样才能找到W呢?
一个常用的方法就是找出使误差最小的W。这里的误差是指预测Y值和真实Y值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消,所以我 们采用平方误差。
2.实例
导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
#线性回归的包
from sklearn.linear_model import LinearRegression
#获取糖尿病数据
import sklearn.datasets as datasets
diabetes = datasets.load_diabetes()
diabetes
data = diabetes.data
target = diabetes.target
feature_names = diabetes.feature_names
samples = DataFrame(data, columns = feature_names)
samples.head()
samples.shape
#抽取训练数据和预测数据
X_train = samples[:400]
y_train = target[:400]
X_test = samples[400:]
y_true = target[400:]
# 创建数学模型,训练
linear = LinearRegression()
linear.fit(X_train,y_train)
# 预测
y_ = linear.predict(X_test)
y_
#绘制图形
plt.plot(y_true, color = "red")
plt.plot(y_)
#给模型评分
linear.score(X_test, y_true)
from sklearn.metrics import r2_score
r2_score(y_true, y_)
#上面做这个案例结束了
#拿出来一个指标(属性)
#拿出来一个血压这个指标
X_train = samples["bp"].values.reshape((-1,1))
X_train
y_train = target
#使用散点图把数据画一下
plt.scatter(X_train, y_train, alpha = 0.6)
#重新训练数据
linear = LinearRegression()
linear.fit(X_train,y_train)
#测试数据
xmin, xmax = X_train.min(), X_train.max()
x_test = np.linspace(xmin, xmax,100).reshape((-1,1))
#预测数据
y_ = linear.predict(x_test)
plt.plot(x_test, y_,color = "r")
plt.scatter(X_train,y_train,alpha= 0.6)
二、岭回归(Ridge)
1.原理
缩减系数来“理解”数据,缩减方法可以去掉不重要的参数,因此能更好地理解数据。此外,与简单的线性回归相比,缩减法能取得更好的预测效果。岭回归是加了二阶正则项(lambda*I)的最小二乘,主要适用于过拟合严重或各变量之间存在多重共线性的时候,岭回归是有bias的,这里的bias是为了让variance更小。

数据的特征比样本点还多如何处理?
如果数据的特征比样本点还多应该怎么办?是否还可以使用线性回归和之前的方法来做预测?
答案是否定的,即不能再使用前面介绍的方法。这是因为输入数据的矩阵X不是满秩矩阵。非满秩矩阵在求逆时会出现问题。为了解决这个问题,统计学家引入了岭回归(ridge regression)的概念
#满秩矩阵:有解的矩阵
x = {x1, x2,x3,...xn}
f(x) = w * x + b
#机器学习其实就是再求方程
x1w1 + x2w2 + x3w3+... + xnwn= y1
1.1*w1 + 2*w2 + 3*w3 = 5
3*w1 + 1.1*w2 + 5*w3 =17
2*w1 + 4*w2 + 6.1*w3 = 10
#2个方程 3个未知数 无解
1 2 3 1 0 0 1.1 2 3
3 1 5===> 0 1 0* 0.1 ===> 3 1.1 5
2 4 6 0 0 1 2 4 6.1
2.过拟合和欠拟合
过拟合:其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。
欠拟合:就是训练样本集过少,或者是属性过少,或者是属性不重要都有可能导致欠拟合的
3.多重共线性
就是属性之间存在线性关系,或者有制约关系
4.归纳总结
(1)岭回归可以解决特征数量比样本量多的问题
(2)岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维的效果
(3)缩减算法可以看作是对一个模型增加偏差的同时减少方差
5.岭回归用于处理下面两类问题:
(1)数据点少于变量个数
(2)变量间存在共线性(最小二乘回归得到的系数不稳定,方差很大)
6.缩减系数
#缩减系数
验证alpha和系数的关系
#针对于训练样本集来说,这个alpha到底怎么取合适?? 答案:看缩减系数
7.实例
岭回归一般用在样本值不够的时候
# 导包
from sklearn.linear_model import Ridge
#样本集小于特征值的
X_train = [[1,1,1,1],[1,2,3,4]]
y_train =[3,1]
#使用普通线性回归
linear = LinearRegression()
linear.fit(X_train,y_train)
#查看模型的系数
linear.coef_
# 使用岭回归
#查看岭回归的系数 alpha 就是lambda
ridge = Ridge(alpha=0.1)
ridge.fit(X_train,y_train)
ridge.coef_
#创建一个假象的训练样本集
X_train = 1/(np.arange(1,11,1)+ np.arange(0,10,1).reshape((-1,1)))
X_train
#10行10列的数据, 基本上可以看成是 数据样本比特征少的一种情况了
y_train = [1,2,3,4,5,6,7,8,9,0]
#创建一个alpha集合,用来验证不同的alpha对预测系数的结果的影响
alphas = np.logspace(-10,-2,100)
alphas
#创建机器学习的模型
ridge = Ridge()
#一个alpha的值会对应 一个整体系数的列表出来[1,2,3,,]
coefs_ = []
for alpha in alphas:
ridge.set_params(alpha = alpha)
ridge.fit(X_train,y_train)
#获取模型的系数
coefs_.append(ridge.coef_)
coefs_
#绘制图形:查看alpha和系数的关系
plt.figure(figsize=(10,10))
axes = plt.subplot(111)
axes.plot(alphas, coefs_)
#s设置x轴单元格
axes.set_xscale("log")
三、lass回归
1.原理:
拉格朗日乘数法
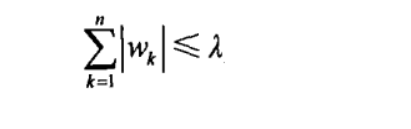
对于参数w增加一个限定条件,能到达和岭回归一样的效果:
在lambda足够小的时候,一些系数会因此被迫缩减到0
比现行回归和岭回归具有更强的缩减系数的能力 w = 0
案例:
使用多种方法对boston数据集进行回归,画出回归图像,并比较多种回归方法的效果
from sklearn.datasets import load_boston
boston = load_boston()
x = boston.data
y = boston.target
from sklearn.linear_model import Ridge, LinearRegression,Lasso
import sklearn.datasets as datasets
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
boston = datasets.load_boston()
boston
data = boston.data
target = boston.target
feature_names = boston.feature_names
samples = DataFrame(data = data, columns= feature_names)
samples.shape
X_train = samples[:450]
y_train = target[:450]
X_test = samples[450:]
y_true = target[450:]
linear = LinearRegression()
ridge = Ridge(alpha = 0)
lasso = Lasso(alpha=13)
linear.fit(X_train,y_train)
ridge.fit(X_train,y_train)
lasso.fit(X_train,y_train)
y_1 = linear.predict(X_test)
y_2 = ridge.predict(X_test)
y_3 = lasso.predict(X_test)
from sklearn.metrics import r2_score
#线性回归
r2_score(y_true, y_1)
#岭回归
r2_score(y_true, y_2)
#alpha = 0 的时候, 此时的岭回归就是线性回归
#lasso回归的
r2_score(y_true, y_3)
#查看一个指标对结果的影响
samples.head()
train = samples["RM"]
X_train = train.values.reshape(-1,1)
y_train = target
linear.fit(X_train,y_train)
ridge.fit(X_train,y_train)
lasso.fit(X_train,y_train)
xmin, xmax = X_train.min(), X_train.max()
X_test = np.linspace(xmin, xmax, 100).reshape((-1,1))
#预测
y_1 = linear.predict(X_test)
y_2 = ridge.predict(X_test)
y_3 = lasso.predict(X_test)
#绘图
plt.plot(X_test, y_1, color = "red",label = 'liner')
plt.plot(X_test, y_2, color = "green", label = "ridge")
plt.plot(X_test, y_3, color = "blue", label = "lasso")
plt.scatter(X_train, y_train)
plt.legend()
#linear和领回归的重合了, alpha = 0
