线性回归一般用来做连续值的预测,预测结果为一个连续值。因训练时学习样本不仅要提供学习的特征向量,而且还要提供样本的实际结果,所以他是一种有监督学习。
当特征向量X中只有一个特征时,需要学习到的函数应该是一个一元线性函数y=a+bx
当情况复杂时,考虑X存在n个特征的情形时,我们往往需要得到更多的系数。我们将X到y的映射记做h(x)=θtX
在通过学习得到的映射函数h(x)中,需要通过训练集得到特征系数向量θ={θ1,θ2,...θn}.那怎样得到所需的特征系数向量。怎样保证得到的特征系数向量足够好,这里会有一个评判标准:损失函数。根据特征向量系数θ,可有损失函数
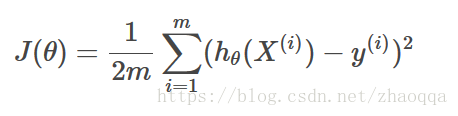
其中h(x)为需要学习的函数,m为训练集样本的个数。xi表示训练集中第i个样本的特征向量,yi表示第i个样本的标签。

梯度下降算法
有了损失函数以后,为了使损失函数最小就会用到梯度下降算法。梯度下降就是一个不断地最小化损失函数的过程。先初始化θ为某一个值,然后让θ沿着j(θ)在θi的偏导方向不断地走,直到走到底部收敛为止,最后就可以得到j(θ)最小时的那个θi的值。


批量随机梯度下降BGD(batch gredient descent),他的具体思路是在更新每一个参数时都使用所有的样本进行更新。

优点:全局最优解;易于并行实现。
缺点:这样训练速度会随着样本数量m的增加而变得缓慢。
随机梯度下降法SGD(stochasyic gradient descent)正是为了解决批量梯度下降随着样本数的加大而变得异常缓慢的弊端而提出的。
随机梯度下降是通过每个样本迭代更新一次。如果样本量很大的情况,那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了。对比于上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现。
小批量梯度下降算法MBGD(Mini-batch gradient descent )
此方法是上面两种方法的折中,使得算法的训练过程比较快,而且也要保证最终参数训练的准确率。
这种方法采用部分小样本进行,每次更新使用固定的样本量。梯度下降要注意特征的归一化处理,这样可以提升模型的收敛速度。
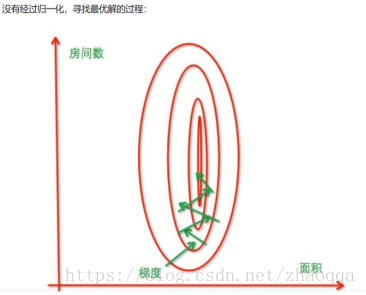
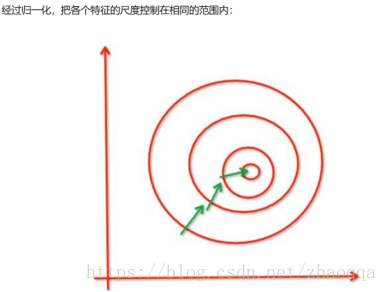
出现左图的原因是因为我们没有同等程度的看待各个特征,即我们没有将各个特征量化到统一的区间。
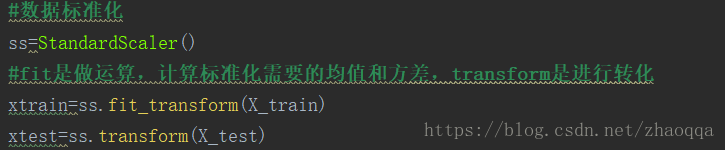
数据标准化(归一化)处理是数据挖掘的一项基本工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。
归一化处理的好处:
加快梯度下降的求解速度,即提升模型的收敛速度。比如上图。有可能提高模型的精度
一些分类器需要计算样本之间的距离,如果一个特征的值域范围非常大,那么距离计算就会主要取决于这个特征。有时会偏离实际情况。
归一化方法:
1)最小-最大规范化
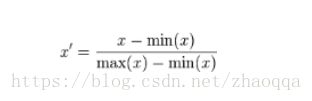
2)零-均值规范化(标准差归一化)

3)小数定标规范化
Log函数: x=lg(x)/lg(max)
反正切函数:x=atan(x)*2/pi


评价一个线性模型的好坏:
决定系数R2(R平方)(coefficient of determination),也称判定系数或者拟合优度。它是表征回归方程在多大程度上解释了因变量的变化,或者说方程对观测值的拟合程度如何。
计算方法:

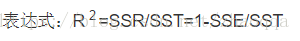

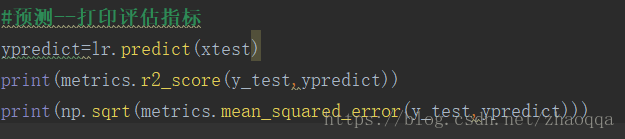
r2越高,说明x对y的解释度越高
均方误差是预测误差平方之和的平均数
