一,什么是线性回归。
回归问题和分类问题是机器学习的两大类问题。回归问题是根据训练集,学习到一个算法来预测一个连续的值,比如说预测房价。而分类问题则是学习一个算法来预测一个离散的值,比如说预测是否是恶性肿瘤,预测的结果只有是或否。线性回归就属于一种回归问题。
在线性回归中,事先给出的每一条训练条目都会有n个特征值,还有一个实际结果。我们期望的是通过训练,学习到这样的一条表达式 :
其中每一个
二,一些符号。
| 符号 | 意义 |
|---|---|
| m | 用来训练的训练集的个数 |
| n | 特征的数目 |
|
|
第i个训练样本 |
|
|
第i个训练样本的第j个特征 |
|
|
一个n+1维的向量,表示多有特征值的参数 |
三,线性回归原理。
首先,我们需要定义一个代价函数,用来衡量我们训练得到的表达式预测的结果与实际训练集中结果 y 之间的误差。我们称其为 J(
上式等号右边每一个相加项表示用我们现有的预测表达式
我们的目标就是求得一组
求最优
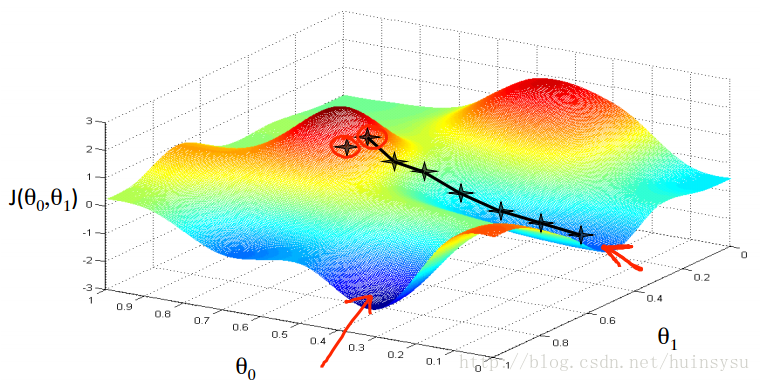
梯度下降法有一个问题就是选择不同的迭代起点,结果可能不相同,如上图,选择不同的起点,结果就会不相同。
但好在我们定义的代价函数
四,梯度下降法。
这里先介绍一种成为批梯度下降的梯度下降方法。就是每一次迭代更新
我们在迭代更新
计算一下得到以下表达式:
每一次对