一:线性回归算法:
1.模型的介绍
在线性回归中,我们建立模型,来拟合多个子变量x(机器学习中成为特征)与一个因变量y之间的关系,y的范围不是离散的,所以这是一个回归问题。
线性回归模型,就是 y=w*x+b
我们的目的就是求得一组权重w,使得它与X的点积与真实的y值更加接近。
2.损失函数
接下来我们想如何让y的真实值与预测值更加接近,或者说怎么表示这个差距,很明显就是差值,但是差值有正有负,如果累加可能会抵消一部分,因此我们想到了用差值的绝对值或者是平方,这就对应了机器学习中的L1范数和L2范数,在这里我们使用L2范数,也就是差值的平方和:
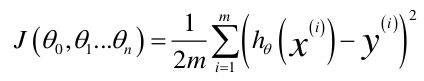
为什么接下来会讲到。注意这里构建的平方和损失函数在机器学习中有一个名字,这一类叫做损失函数或者代价函数,既然这是代价,那么我们要考虑的就是如何最大限度的减少代价。
3.优化函数
观察代价函数,我们如何求得它的最小值,我们可以马上想到最简单的方式便是求导,分别求出函数对w和b的导数,当他们等于0时便求得了代价函数的最小值。注意这里有很多组x和y,因此不可能通过简单的一个公式直接求出导数,我们需要用到一种叫做梯度下降法的优化方式,它的步骤如下:
对每个参数,计算对损失函数的偏导数:
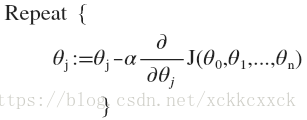
接下来更新权重w和偏置量b:(下面是网上找的图片,不知道为什么右侧有个竖杠,请自动忽略。。。)
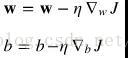
学习率一般初始设置0.2到1,有一些高级的算法可以动态调整学习率,就是在下山的过程中不停的改变步伐。但是这里不先深究。
4,结束语
至此,我们已经了解了线性回归中的一些基本概念,我在jupyter notebook做了一个这个算法的python实现,放到了我的github上,有兴趣的同学可以看一下。