——python线性回归,机器学习线性回归,sklearn.linear_model.LinearRegression
用python进行线性回归分析非常方便,如果看代码长度你会发现真的太简单。但是要灵活运用就需要很清楚的知道线性回归原理及应用场景。现在我来总结一下用python来做线性回归的思路及原理。
线性回归介绍
- ——线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
- ——回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析
- 定义:线性回归在假设特证满足线性关系,根据给定的训练数据训练一个模型,并用此模型进行预测。为了了解这个定义,我们先举个简单的例子;我们假设一个线性方程 Y=2x+1, x变量为商品的大小,y代表为销售量;当月份x =5时,我们就能根据线性模型预测出 y =11销量;对于上面的简单的例子来说,我们可以粗略把 y =2x+1看到回归的模型;对于给予的每个商品大小都能预测出销量;当然这个模型怎么获取到就是我们下面要考虑的线性回归内容;
机器学习中的线性回归
在scikit_learn库中线性模型有很多,引入sklearn.linear_model广义线性模型,本章所用的是sklearn.linear_model.LinearRegression普通最小二乘线性回归官方帮助文档查看详细原文。
sklearn.linear_model.LinearRegression参数
sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
fit_intercept :(截距)默认为True,可选False
normalize:(标准化) 默认为True,可选False
copy_X:(复制X数据)默认为True,可选False。如果选False会覆盖原数
n_jobs:(计算性能)默认为1,可选int,工作使用的数量计算。sklearn.linear_model.LinearRegression属性
coef_ :估计系数,数组,形状(n_features)或(n_targets n_features)
intercept_:截图数,数组sklearn.linear_model.LinearRegression使用方法
fit(X, y[, sample_weight]):符合线性模型进行拟合X:numpy数组或稀疏矩阵的形状(n_samples,n_features),训练数据
y:numpy一系列形状(n_samples,n_targets),目标数据
sample_weight:numpy一系列形状(n_samples),样本权重get_params([deep]):得到参数估计量,默认为True
如果这是真的,将返回的参数估计量的估计量,包含子对象
predict(X):使用线性模型预测
根据自变量按数组形式输入
score(X, y, sample_weight=None):返回确定系数R ^ 2的预测
系数R ^ 2定义为(1-u / v),其中u是残差平方和((y_true-y_pred)* 2).sum()和v是平方和的总和((y_true - y_true.mean())* 2).sum()。最好的分数是1.0,它可能是负的(因为模型可以任意更差)。总是预测y的期望值的常数模型,忽略输入特征,将得到R ^ 2得分为0.0。
一元线性回归算法实例
我手中有一个关于房屋面积与价格的数据,我想通过线性回归去用面积预测价格。先导入相应的库及创建房屋面积与价格的数据,这类属于一元线性回归。
import pandas as pd #导入pandas库
import numpy as np #导入numpy库
from sklearn.linear_model import LinearRegression #导入机器学习库中的线性回归模块
data=pd.DataFrame({'square_feet':[150,200,250,300,350,400,600],
'price':[5450,6850,8750,9650,10450,13450,16450]})
#创建一组7行2列的数据,square_feet为房屋面积,price为对应价格对数据进行预处理分出训练集与测试集或者理解为用X于预测Y,(data_train为X,data_test为Y)
data_train=np.array(data['square_feet']).reshape(data['square_feet'].shape[0],1)#这里是将数据转化为一个1维矩阵
data_test=data['price']
#创建线性回归模型,拟合面积与价格并通过面积预测价格
regr=LinearRegression() #创建线性回归模型,参数默认
regr.fit(data_train,data_test)#拟合数据,square_feet将房屋面积作为x,price价格作为y;也可以理解用面积去预测价格
a=regr.predict(268.5)
print(a)#查看预测结果
print(regr.score(data_train,data_test))#查看拟合准确率情况,这里的检验是 R^2 ,趋近于1模型拟合越好
#预测的结果:268.5平的房子价格为8833.54, R^2 =0.967
#我们来画个图看一下数据最后是什么样的
plt.scatter(data['square_feet'],data['price']) #画散点图看实际面积和价格的分布情况
plt.plot(data['square_feet'],regr.predict(np.array(data['square_feet']).reshape(data['square_feet'].shape[0],1)),color='red') #画拟合面积与价格的线型图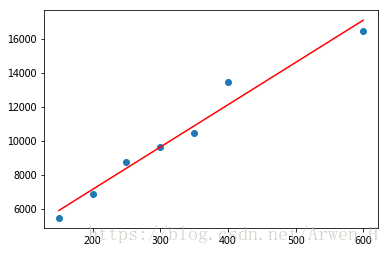
二元线性回归及多元实例
刚才拿房屋面积与价格组成了一个自变量和一个因变量的一元线性回归模型,二元及多元就是增加自变量,下面还是拿房屋预测价格举例。增加一列数据为房屋卧室数量(bedrooms)
import pandas as pd #导入pandas库
import numpy as np #导入numpy库
from sklearn.linear_model import LinearRegression #导入机器学习库中的线性回归模块
data=pd.DataFrame({'square_feet':[150,200,250,300,350,400,600],
'price':[5450,6850,8750,9650,10450,13450,16450],
'bedrooms':[2,2,3,4,4,5,6]})
data_train=np.array(data[['square_feet','bedrooms']]).reshape(len(data),2)#不管什么方法将list或DataFrame或Series转化成矩阵就行
data_test=np.array(data['price']).reshape(len(data),1)regr=LinearRegression() #创建线性回归模型,参数默认
regr.fit(data_train,data_test)#拟合数据,square_feet将房屋面积作为x,price价格作为y;也可以理解用面积去预测价格
a=regr.predict([[268.5,3]])#预测多增加一个卧室数量3
print(a)
#预测的结果:268.5平的房子价格为8594, R^2 =0.983官网线性回归实例
此示例仅使用糖尿病数据集的第一个特征,以说明此回归技术的二维图。在图中可以看到直线,显示线性回归如何尝试绘制直线,这将最好地最小化数据集中观察到的响应之间的残差平方和线性近似预测的响应。无原始数据
还计算系数,残差平方和和方差分数。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
#加载糖尿病数据集
diabetes = datasets.load_diabetes()
#只使用一个特性
diabetes_X = diabetes.data[:, np.newaxis, 2]
# 将数据分为训练diabetes_X_train /测试集diabetes_X_test
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# 把目标分成训练diabetes_y_train /测试集diabetes_y_test
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
#创建线性回归对象
regr = linear_model.LinearRegression()
#使用训练集训练模型
regr.fit(diabetes_X_train, diabetes_y_train)
#使用测试集进行预测
diabetes_y_pred = regr.predict(diabetes_X_test)
# 查看系数
print('Coefficients: \n', regr.coef_)
# 查看均方误差
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# 解释方差分数:1是完美的预测
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
#图输出
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()