Mixed High-Order Attention Network for Person Re-Identification
针对问题:局部特征
新颖点:
- 不同于以往channel-wise和position-wise的注意力机制,作者提出了High-Order Attention module可以利用复杂的高阶统计信息,捕捉细微差别
- 在MHN中作者采用了不同阶数的HOA模块,并引入了对抗约束防止高阶HOA模块坍缩为低阶模块
摘要:
- 作者认为以往的基于通道和空间的注意力机制是粗糙和第一阶的,只能得到一些简单而粗糙的信息,而高阶注意力模块(High-Order Attention), 利用了复杂的高阶统计信息,以捕捉细微差别。具有不同阶数的HOA可以对不同的高阶统计数据进行建模,这样就可以得到全方位的注意力机制,进而有效的对未出现的行人身份进行准确识别。
- 作者在将re-id视为zero-shot learning(ZSL,训练集和测试集之间没有行人身份的交叉)的基础上,提出了Mixed High-Order attention Network(MHN)进一步显式增强注意力机制的区分能力和丰富度。
- 不同于full-shot learning(如基于CIFAR,Imagenet的分类器),在 ZSL中深度模块的基本学习方法会很大程度的影响特征嵌入的效果,例如深度模块更加注重表面统计规律,而非一般的抽象的概念。尽管提出的高阶注意力模块可以捕捉复杂高阶的统计信息,但是由于深度模块的基本学习方法产生的影响,在zero-shot设置下,会出现深度模块坍缩为低阶模块的情况。为了防止此类情况的发生,作者在MHN中还加入了对抗学习的约束。
- MHN是一个普遍适用且与模型无关的框架,可以很容易的应用于IDE和PCB。
问题描述
注意力机制的主要目的是调整卷积输出的权重,从而突出那些重要的部分,减少无用信息的影响,于是问题就可以表述为如下的式子:
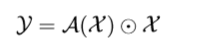
是通过CNN处理得到的三维张量,
是某种注意力模块的结果,中间的是Hadamard Product.
高阶注意力模块
作者首先在高阶统计量 x 上定义了一个线性多项式预测函数,x 是特定空间位置上的局部描述符:
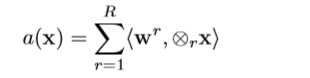
(具体符号解释见论文,中间推导过程见论文)
最终,可以得到一个能够对局部描述符 x 的高阶统计信息建模的预测函数:
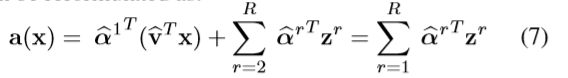
然后套上sigmoid函数,得到一个高阶类向量的注意力图:
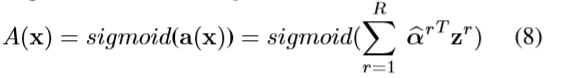
为了增加注意力图的代表力,作者进行了一个非线性处理,即:
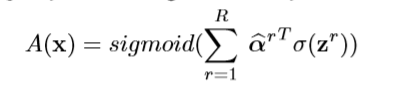
是任意非线性激活函数,作者具体使用的是RELU。由此可以得到
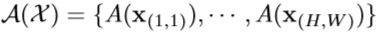
这个就是HOA的高阶注意力图
,其有两个好处(1)在不同空间位置共享权重不会产生过多的参数;(2)易于通过1X1的卷积层实现。

基于通道的注意力模块被称为是第一阶的,因为(1)其GAP层只收集了第一阶的统计信息而忽略嗲了高阶的统计信息;(2)其全连接层可以视为是一个1X1的卷积层,进而两个级联的全连接层就等同于HOA模块取 R=1 的情况。
mixed high-order attention network
在ZSL中,深度模块会选择性地学习有利于区分已经出现的行人的信息,而忽略掉那些可能对区分未出现的行人有利的信息,因此作者提出了 mixed high-order attention network(MHN)通过不同阶数的HOA模块充分利用不同的、互补的高阶信息。
作者将ResNet50分为 P1(conv1 to layer2)和 P2(layer3 to GAP),P1用于将给定图片按照原始像素空间编码至中级特征空间,P2将注意力图编码到可以对数据进行分类的高级特征空间。而具有不同阶数的HOA放在P1和P2的中间,以产生不同的高阶注意力图,同时增强已学习到内容的丰富性。因为P2模块通过不同的注意力流共享权重,所以MHN并不会产生过多的参数。
而由于深度模块部分或有偏向的学习方式,高阶的HOA会坍缩成相对低阶的模块,所以不同阶数的HOA其实都会坍缩成相同的低阶模块,为避免此类情况的发生,作者提出了对抗约束来规范HOA的阶数以使其不同:
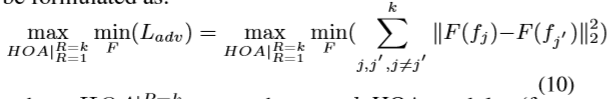
MHN的中的目标函数为:
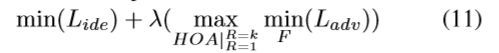
作者通过对编码后的特征量进行约束,而并不是直接对高阶注意力图进行约束,主要是考虑到这些来自高阶统计信息的注意力图和在注意力空间中对HOA不同阶数的定义很难人工实现,因次对特征向量添加了约束。
为了防止阶数坍缩的问题出现,HOA被明确地规范化,以方便对想要的高阶注意分布进行建模,并产生区分度强、信息多样的注意力图,这是有助于识别未出现的行人的。

实验
Market-1501:top1 95.1 mAP 85
DukeMTM:top1 89.1 mAP 77.2
CUHK03-NP:top1 77.2 mAP 65.4
