转自:https://blog.csdn.net/zhongshaoyy/article/details/78551728
作者思路是基于CNN每一层都是稀疏地假设,考虑是否能找到neuron之间的关系,仅留下最具有代表性地neuron。
分为两步解决问题:
- 找出每一层具有代表性地neuron,我们利用lasso regression来进行类似model selection的过程。将剩余的neuron去掉(pruning)。
- 利用剩下的代表性neuron来重构(reconstruction)这一层原本的输出。
1.背景介绍
作者将目前的CNN加速研究分为三类:
- Optimized implementation :比如FFT
- Quantization :代表为BinaryNet
- Structured simplification:本文属于这一类
而Structured simplification作者又分为三类:
- tensor factorization :mobilenet 为代表,作者提出这种方法无法分解1*1的卷积,而1*1的卷积普遍用在GoogleNet ,ResNet 和Xception 上
- sparse connection:以deep compression 为代表,这种方法缺点是被pruning 后的连接和神经元会形成不规则的结构,不容易在硬件上进行配置实现
- channel pruning:本文采用的方法,优点是直接减少不重要的通道数,缺点是会对下游层产生影响,因此要reconstruction
2、方法介绍
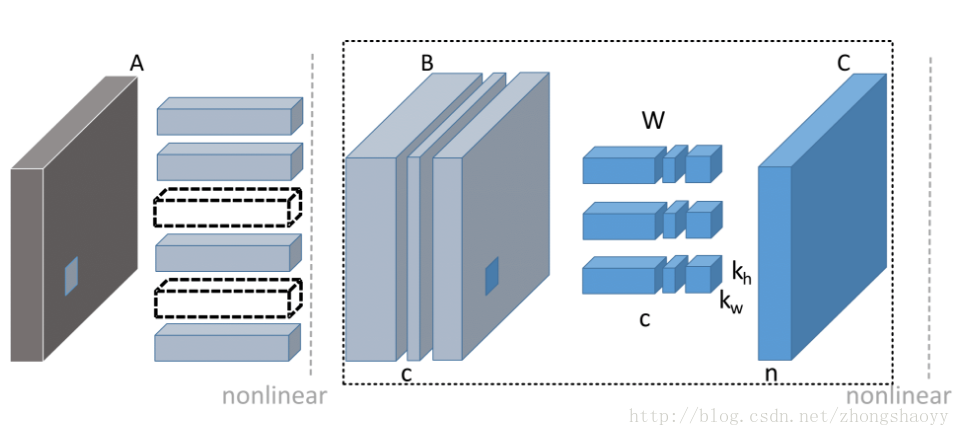
如图所示,目标就是减少B 的feature map, 那么B中的channel被剪掉,会同时使得上游对应的卷积核个数减少,以及下游对应卷积核的通道数减少。关键在于通道选择,如何选择通道而不影响信息的传递很重要
为了进行channel selection ,作者引入了β作为mask ,目标变为 :
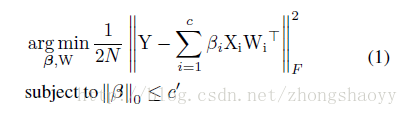
β是一个列向量,如果βi=0 则代表对应的通道被剪除,c ‘代表经过选择后的通道个数 c’<=c
解决这个最小化问题是一个NP-hard问题(貌似很高深,没细研究),因此作者分两步来优化,首先固定W,优化β ;然后固定β,优化W。而且为了增加β的稀疏度,将β的L1正则项加入优化函数;为了防止明显解的出现又加入了W的约束,原优化函数变为:
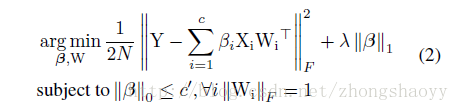
(1)固定W,优化β :
用LASSO回归:
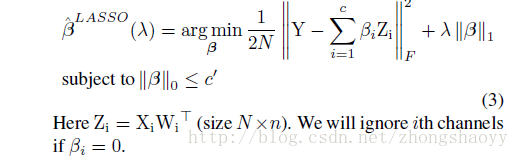
(2)固定β,优化W:
3、实验结果
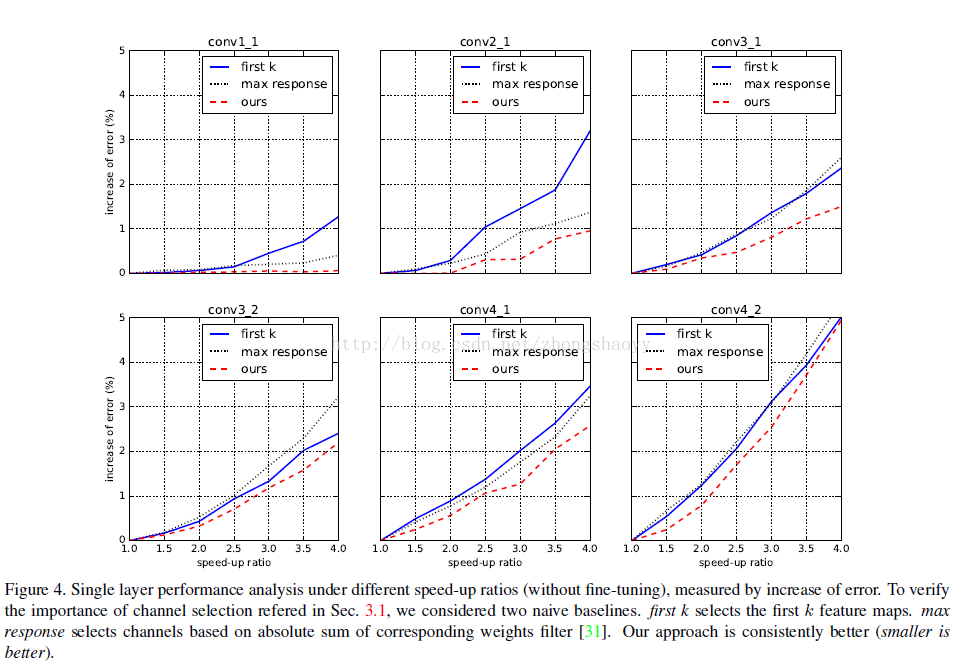
图1

图2
图1可以看出,shadow layer的channel 冗余度更高,更容易被pruning ,可能和低层卷积提取的特征比较具体,高层卷积提取的特征更加抽象有关。
图2可以看出,经过finetune之后效果会好很多,跟我之前的想法符合:做完pruning不做retrain肯定会引入误差,而finetine通过权重矩阵值的调整可以一定程度上消除这种误差。
4、总结
个人觉得这篇文章的主要贡献在于:相较于原来那种暴力的pruning,利用数学方法优化目标函数,使得pruning前后的输出差异最小,取得了一定效果。
缺点在于:我还是觉得人工加入的限定太多,而且这种方法引入了很多调节参数,调整和优化都麻烦,实用性不强。而且文章开头说不需要retrain,其实还是pruning之后再来finetune一下效果比较好。