参考代码:dmcp
1. 概述
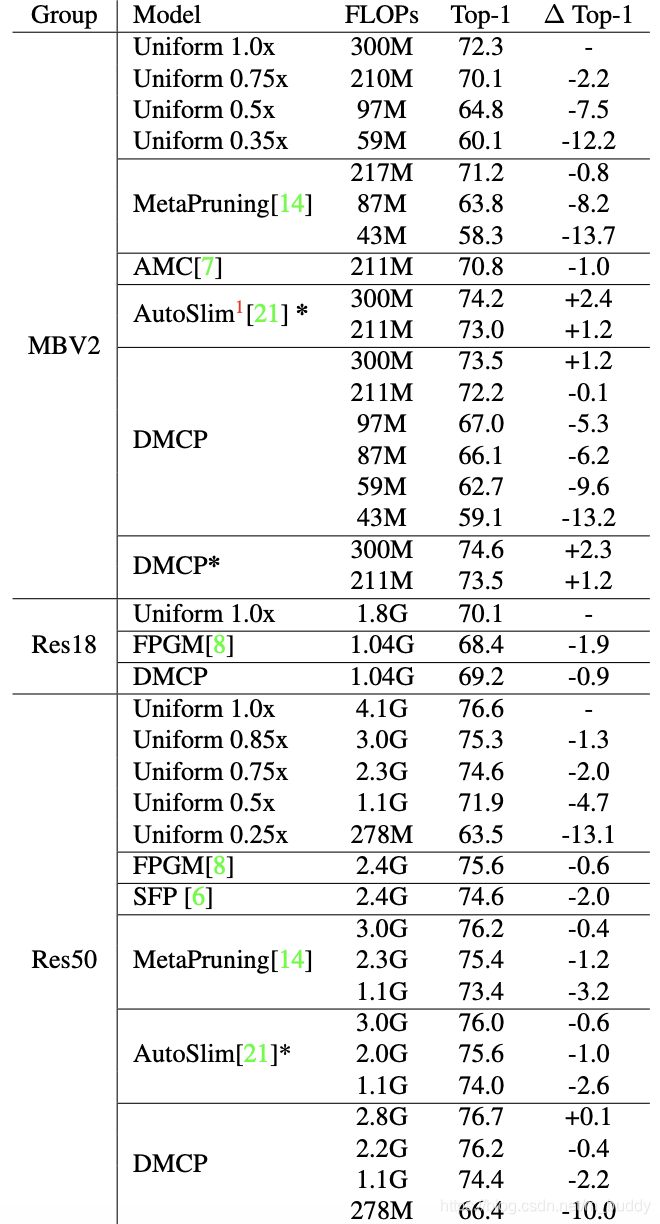
导读:在网络剪枝领域中已经有一些工作将结构搜索的概念引入到剪枝方法中,如AMC使用强化学习的方式使控制器输出每一层的裁剪比例。但是正如NAS的发展过程一样,这些基于强化学习的搜索方法需要大量的训练和验证过程,而最直接的便是使用类似DARTS的直接梯度优化方法。而这篇文章中将网络的channel剪枝建模为一个可微分的马尔可夫过程(Differentiable Markov Channel Pruning,DMCP),通过直接产生的梯度信息进行优化,因而更加高效,整个剪枝的过程也变为了一个马尔可夫决策过程。为了减少额外参数的引入,文章还将卷积层的channel进行分组,组内实行参数共享,从而减少参数量。使用文章的方法在MobileNet-v2上剪裁掉了30%的参数,掉点0.1%;在ResNet-50上剪裁掉了44%的参数,掉点0.4%。
网络剪枝的过程可以看作是在一个现有搜索空间中去搜索一个最小的子结构,但需要保持网络的输出性能相差不大。对于网络搜索,在之前的NAS工作中已经将可微分的概念引入到搜索过程中,如DARTS,但是网络剪枝过程中却无法直接使用,这是因为:
- 1)搜索空间不同:DARTS中的搜索空间是预先定义好的网络结构,而网络剪枝中却是网络每层的channel;
- 2)“元素”之间的关系不同:在DARTS中这些“元素”是相互独立的,而在网络剪枝过程中其却是存在依赖关系的,如要保留第 k + 1 k+1 k+1个channel那么前面的 k k k个channel应该是保留的;
正如上面提到在网络层中channel是前向依赖的,而这一点性质与马尔可夫的决策过程接近,因而文章将网络剪枝的过程抽象为一个马尔可夫决策过程,使用 S k S_k Sk表示保留 k t h k^{th} kth个channel的状态,从状态 S k S_k Sk到 S k + 1 S_{k+1} Sk+1(保留 ( k + 1 ) t h (k+1)^{th} (k+1)th)是存在状态转移的,因而对于每一个channel就可以得到一个状态转移的概率,因而就可以根据这个概率来选择特征图中的channel。在实际操作中会channel与对应的概率相乘从而去控制剪裁。在此基础上通过概率模型构建出来一个带参数的采样空间,从而这个过程便变得可微分,就使得可以使用一个目标FLOPs去约束,从而达到剪枝的目的。
将文章的方法与之前的一些方法进行比较,见下图所示:
2. 方法设计
2.1 整体Pipline
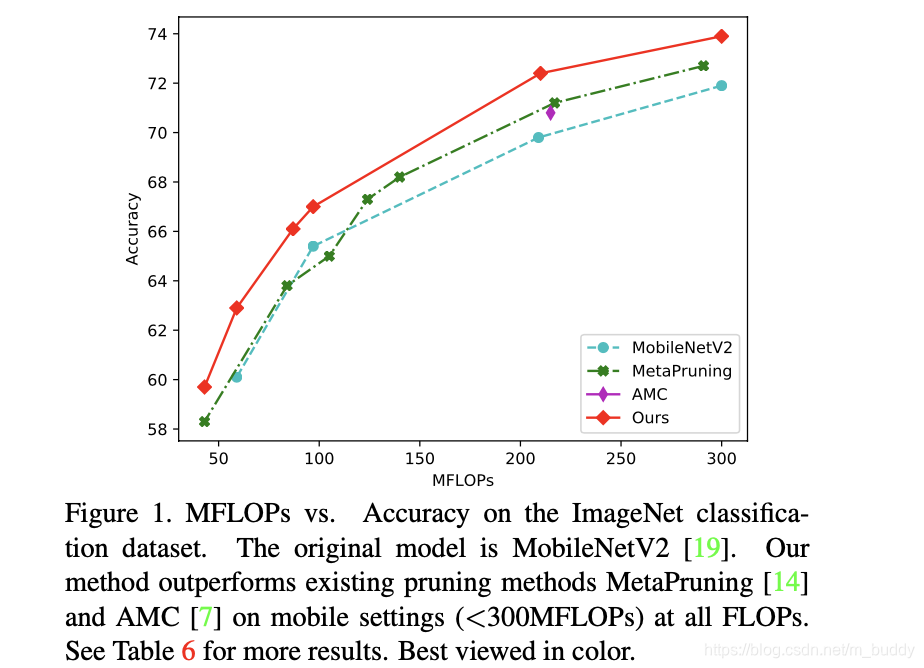
文章的整体网络方法pipline如下图所示:
上图的a部分表示的文章训练的两个stage:
- 1)stage1:固定结构参数,通过参数共享训练4个子网络(最小/最大/两个随机,通过参数共享形式在一个卷积里面选择不同数量channel实现),引入扰动寻找最优的搜索结构;
- 2)stage2:将网络设置为最大,训练网络的结构参数,通过训练约束网络结构使其在channel上“稀疏”;
上图的b部分是数据在一个Conv+BN+ReLU结构中的融合过程。
2.2 基于马尔可夫过程的剪裁
对于一个网络层 L ( i ) L^{(i)} L(i),其输出的channel维度为 C o u t ( i ) C_{out}^{(i)} Cout(i),其输出描述为下面的形式:
O k ( i ) = w k ( i ) ⊙ x , k = 1 , 2 , … , C o u t ( i ) O_k^{(i)}=w_k^{(i)}\odot x,k=1,2,\dots,C_{out}^{(i)} Ok(i)=wk(i)⊙x,k=1,2,…,Cout(i)
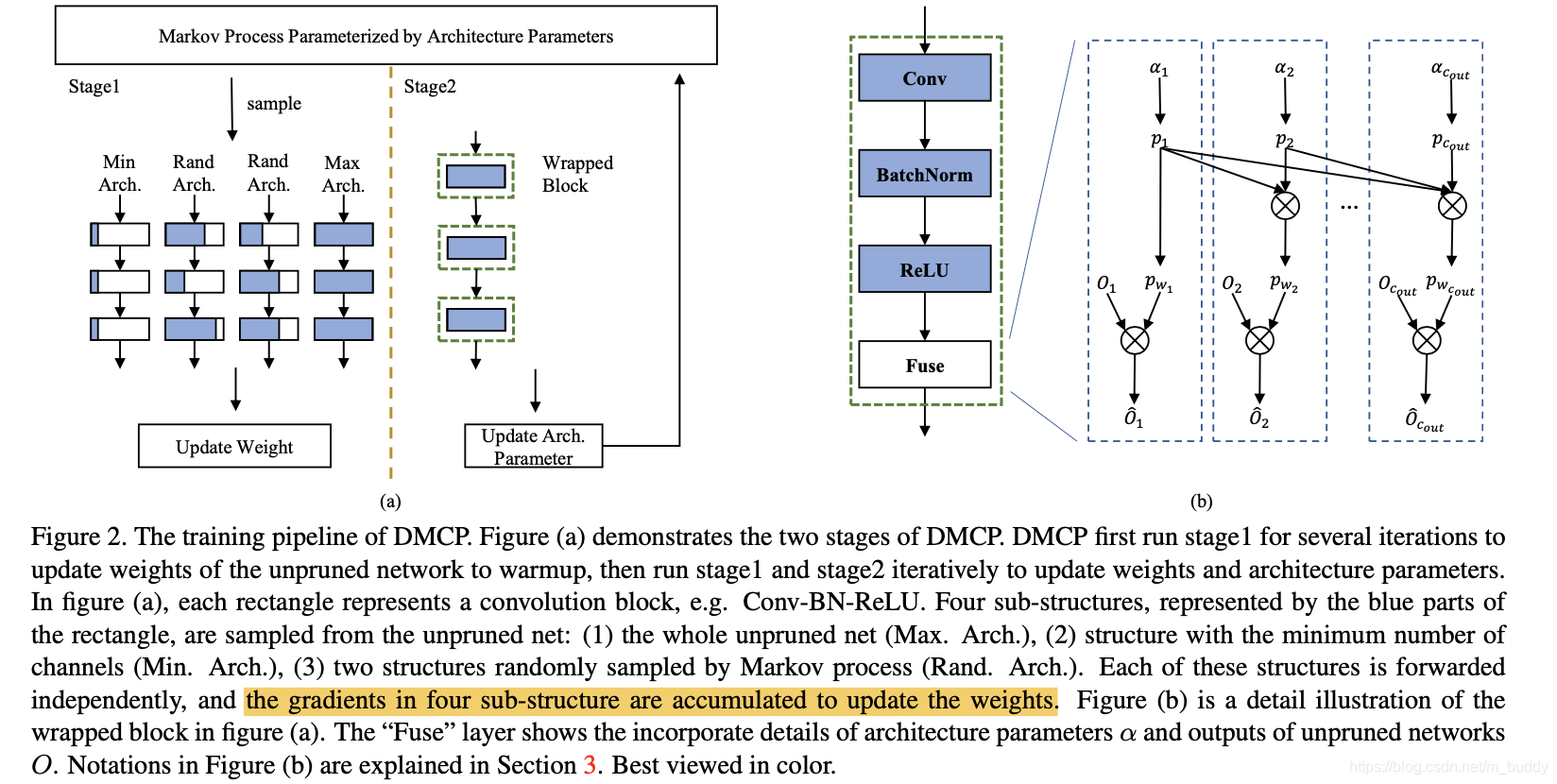
其中, w k ( i ) w_k^{(i)} wk(i)表示参数。由于网络层channel的性质,文章将其在channel维度上进行建模,构建一个马尔可夫过程,描述为下图所示:
当前 k k k的channel与之前的 k − 1 k-1 k−1个channel是相关的,并且之前的 k − 1 k-1 k−1个channel应该是确定存在的。对于前面的 k − 1 k-1 k−1个channel其保留的概率描述为 p ( w 1 , w 2 , … , w k − 1 ) p(w1,w2,\dots,w_{k-1}) p(w1,w2,…,wk−1),那么第 k k k个channel在该条件下被保留下来的概率为:
p ( w 1 , w 2 , … , w k ) = p ( w k ∣ w 1 , w 2 , … , w k − 1 ) p ( w 1 , w 2 , … , w k − 1 ) p(w1,w2,\dots,w_k)=p(w_k|w1,w2,\dots,w_{k-1})p(w1,w2,\dots,w_{k-1}) p(w1,w2,…,wk)=p(wk∣w1,w2,…,wk−1)p(w1,w2,…,wk−1)
其中, p ( w k ∣ w 1 , w 2 , … , w k − 1 ) p(w_k|w1,w2,\dots,w_{k-1}) p(wk∣w1,w2,…,wk−1)是在 ( k − 1 ) (k-1) (k−1)个channel存在的情况下,第 k t h k^{th} kth个channel存在的条件概率,而且 k t h k^{th} kth只与 ( k − 1 ) t h (k-1)^{th} (k−1)th相关,之前的 ( k − 2 ) t h (k-2)^{th} (k−2)th是相互独立的,因而第 k k k个channel保存的概率为:
p k = p ( w k ∣ w 1 , w 2 , … , w k − 1 ) = p ( w k ∣ w k − 1 ) p_k=p(w_k|w1,w2,\dots,w_{k-1})=p(w_k|w_{k-1}) pk=p(wk∣w1,w2,…,wk−1)=p(wk∣wk−1)
在第 ( k − 1 ) t h (k-1)^{th} (k−1)th被抛弃的时候则对应的概率描述为:
p ( w k , ¬ w k − 1 ) = 0 p(w_k,\neg w_{k-1})=0 p(wk,¬wk−1)=0
因而,根据上面的方式便可以得到一个状态转移分布(表示在不同的channel之间) P = { p 1 , p 2 , … , p C o u t } P=\{p_1,p_2,\dots,p_{C_{out}}\} P={
p1,p2,…,pCout}。那么由什么来生成这些概率呢?这里文章是通过网络结构参数 A = { α 1 , α 2 … , α C o u t } A=\{\alpha_1,\alpha_2\dots,\alpha_{C_{out}}\} A={
α1,α2…,αCout}实现的,每个channel上的概率计算描述为(设第一个channel概率肯定是1):
p k = { 1 , k=1 s i g m o i d ( α k ) = 1 1 + e − α k , k = 2 , … , C o u t , α k ∈ A p_k = \begin{cases} 1, & \text{k=1} \\ sigmoid(\alpha_k)=\frac{1}{1+e^{-\alpha_k}}, & k=2,\dots,C_{out},\alpha_k\in A \end{cases} pk={
1,sigmoid(αk)=1+e−αk1,k=1k=2,…,Cout,αk∈A
则对于 k k k个channel进行采样的边际概率可以描述为多个概率相乘的形式:
p ( w k ) = p ( w k ∣ w k − 1 ) p ( w k − 1 ) + p ( w k ∣ ¬ w k − 1 ) p ( ¬ w k − 1 ) = p ( w k ∣ w k − 1 ) p ( w k − 1 ) + 0 = p ( w 1 ) ∏ i = 2 k p ( w i ∣ w i − 1 ) = ∏ i = 1 k p i p(w_k)=p(w_k|w_{k-1})p(w_{k-1})+p(w_k|\neg w_{k-1})p(\neg w_{k-1})\\ =p(w_k|w_{k-1})p(w_{k-1})+0\\ =p(w_1)\prod_{i=2}^kp(w_i|w_{i-1})=\prod_{i=1}^kp_i p(wk)=p(wk∣wk−1)p(wk−1)+p(wk∣¬wk−1)p(¬wk−1)=p(wk∣wk−1)p(wk−1)+0=p(w1)i=2∏kp(wi∣wi−1)=i=1∏kpi
得到边际概率之后与对应channel的特征图得到这个channel的输出:
O k ^ = O k ∗ p ( w k ) \hat{O_k}=O_k*p(w_k) Ok^=Ok∗p(wk)
其融合过程见图2的b图所示。
shortcut连接的处理:
由于shorcut连接需要头尾的channel选择一致,因而文章采用的是头尾部分共享一个结构参数的方式用以维持头尾选择结构的一致性。
裁剪网络的FLOPs:
在之前的计算过程中得到了每个channel的保存的概率,那么对于这些channel求取期望就可以得到剪裁之后剩余的channel个数:
E ( c h a n n e l ) = ∑ i = 1 C o u t p ( w i ) E(channel)=\sum_{i=1}^{C_{out}}p(w_i) E(channel)=i=1∑Coutp(wi)
上面计算得到便是当前层 L L L实际输出的channel个数 E ( o u t ) E(out) E(out),则该层的计算量描述为:
E ( L F L O P s ) = E ( o u t ) ∗ E ( i n ) g r o u p s ∗ c h a n n e l _ o p E(L_{FLOPs})=E(out)*\frac{E(in)}{groups}*channel\_op E(LFLOPs)=E(out)∗groupsE(in)∗channel_op
其中, c h a n n e l _ o p = ( S I + S P − S K s t r i d e + 1 ) ∗ S K ∗ S K channel\_op=(\frac{S_I+S_P-S_K}{stride}+1)*S_K*S_K channel_op=(strideSI+SP−SK+1)∗SK∗SK,则整个网络的计算量就可以计算得到:
E ( N F L O P s ) = ∑ l = 1 N E ( l ) ( L F L O P s ) E(N_{FLOPs})=\sum_{l=1}^NE^{(l)}(L_{FLOPs}) E(NFLOPs)=l=1∑NE(l)(LFLOPs)
从而就得到网络计算量的参数化表达,这个结果可以与设定的计算量目标计算偏差,使用梯度反传了。
损失函数:
对于结构参数的部分的损失函数描述为:
l o s s r e g = l o g ( ∣ E ( N F L O P s ) − F L O P s t a r g e t ∣ ) loss_{reg}=log(|E(N_{FLOPs})-FLOPs_{target}|) lossreg=log(∣E(NFLOPs)−FLOPstarget∣)
再加上网络本身的损失函数 l o s s c l s loss_{cls} losscls(在源码中还引入了蒸馏的概念,添加了对于max模型的KL散度),因而总的损失函数描述为:
L o s s a r c h = l o s s c l s + λ r e g l o s s r e g Loss_{arch}=loss_{cls}+\lambda_{reg}loss_{reg} Lossarch=losscls+λreglossreg
注意,这里没有对结构参数施加weight decay,只是对网络参数添加了,文章指出这样是为了防止结构参数趋向0从而妨碍优化过程。
2.3 训练的Pipline
文章的训练是划分为2个stage的,在开始进行网络剪裁之前会先将网络训练一段时间,使得网络可以排除由于网络未充分训练导致陷入局部最小值中。

之后便开始2个stage的交替训练过程,这个过程在之前内容中有提到,这里不再赘述。
2.4 剪裁之后模型的采样
剪裁之后模型的采样文章给出了两个方案:Direct Sampling(DS)和Expected Sampling(ES)。下面列出其关键部分代码,要弄清楚整体的运行逻辑,还需要读者自行阅读源码。
DS:
def direct_sampling(self):
"""
Direct sampling (DS): sampling independently by Markov process.
"""
if self.num_groups == 0:
return self.min_ch
prob = self.get_condition_prob().detach().cpu() # 获得每个分组的概率
pruned_ch = self.min_ch
for i in range(self.num_groups): # 按照均匀分布对组概率进行判别,最后得到的channel数
if random.uniform(0, 1) > prob[i]: # 不满足保留条件
break
pruned_ch += self.group_size
return pruned_ch
ES:
def expected_channel(self): # 求取最后channel的期望(按组来分的)
if self.num_groups == 0:
return self.min_ch
marginal_prob = self.get_marginal_prob()
return torch.sum(marginal_prob) * self.group_size + self.min_ch
def expected_sampling(self):
"""
Expected sampling (ES): set the number of channels to be expected channels
"""
expected = round(self.expected_channel().item() - 1e-4) # 按照每组的概率和组大小求取期望(未与组id对齐)
candidate = [self.min_ch + self.group_size * i for i in range(self.num_groups + 1)] # 将总的channel按照组划分
idx = np.argmin([abs(ch - expected) for ch in candidate]) # 得到最适宜的采样channel数量(与组id对齐)
return candidate[idx], expected
两种采样方式的性能差异:
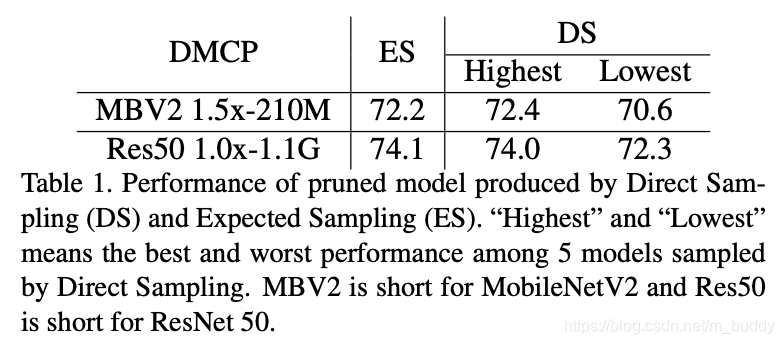
3. 实验结果