MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
原文地址:MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
这篇文章使用一种data-driven的Curriculum learning策略来解决训练数据受污染或有噪声时深度网络过拟合的问题。
Abstract
最近的深度神经网络可以学习到所有的数据信息,即便数据完全随机,这样的话问题也就出现了,那就是过拟合。为了克服过拟合问题,作者提出了一种学习另一个神经网络(MentorNet)来监督基础深度网络(StudentNet)训练的新技术。在训练期间,MentorNet为StudentNet提供了一个课程(样本加权方案)来关注样本,样本的标签可能是正确的。与通常由人类专家预先定义的现有课程不同,MentorNet使用StudentNet动态学习数据驱动的课程。实验结果表明,该方法能显著提高训练数据的深度网络泛化性能。值得注意的是,作者在WebVision上获得了到目前为止最好的结果,这是一个包含220万张真实世界噪声标签图像的大型基准测试。
1. Introduction
目前深度卷积神经网络有能力记住所有的训练数据,即使数据有些已经被随机标签污染了,这就导致了过拟合的问题。
目前如何提高deep CNNs在受污染数据上训练的泛化能力问题还是很值得研究的。一般来说,目前的一些deep CNNs模型在比较clear的训练数据上表现很优异,但是,一旦数据corrupted,他们的表现马上就不行了。
Curriculum Learning (CL)受人类和动物认知过程的启发,找到了一种解决以上问题的方法,那就是对训练样本进行一个排序,更多地关注最有可能是正确的样本。
然而,对于deep CNNs,我们需要解决现有CL方法的两个局限性。首先,现有的课程通常是预定义的,在培训期间保持固定不变,忽略了学生的反馈。深度网络课程的学习过程是非常复杂的,不能用预先设定的课程来精确建模;其次,交替最小化,通常用于CL和自步学习,需要替换变量更新,这对于通过mini-batch随机梯度下降来训练deep CNNs是很困难的。
为此,作者提出了一种通过名为MentorNet的网络从数据中学习课程的方法。MentorNet学习一个数据驱动的课程来监督基础deep CNN,即StudentNet。可以学习MentorNet来近似现有的预定义课程,或者从数据中发现新的数据驱动课程。学习的数据驱动课程可以根据StudentNet的反馈进行几次更新。当MentorNet被学习或更新时,会固定它的参数并与StudentNet一起使用它来最小化学习目标,MentorNet控制学习每个样本的时间和注意力。在测试期间,StudentNet单独进行预测,而不使用MentorNet。
该方法从两个方面改进了现有的课程学习。首先,作者定义的课程是从数据中学习的,而不是由人类专家预先定义的。它考虑到学生网的反馈,可以在培训过程中动态调整。直觉上,这类似于一种协作学习模式,课程由老师和学生共同决定。其次,在作者的算法中,使用MentorNet和StudentNet通过小批量随机梯度下降法联合最小化学习目标。因此,该算法可以方便地并行化,在大数据上训练deep CNNs。同时该方法展示了收敛性,并在大型基准上进行了实证验证。
贡献点:
- 对于带有受污染数据(损坏标签)的deep CNNs作者提出了一种学习数据驱动课程的新方法。
- 讨论了一种利用小批量随机梯度下降法进行深度网络课程学习的算法。
- 在4个基准测试上验证了我们的方法,并在WebVision基准测试上获得了目前发布的最好的结果。
2. Preliminary on Curriculum Learning
下面是问题的定义,在训练集 上, 是第 个样本, 是有噪声的标签。 是StudentNet的判别函数。另外, 是 个类别的损失。 是潜在权值变量。优化的目标函数:
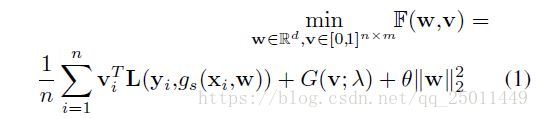
中包含了data augmentation和dropout。 是一个表示第 个样本潜在权重变量的向量。 就是代表课程。这篇文章使用one-hot编码,为了表示方便,使用 表示损失,标量 表示潜在权重变量,整数 标签。
使用交替最小化轮流优化 和 ,在优化 时,固定 ,使用随机梯度下降进行优化;优化 时,先固定最近更新的 ,然后计算:
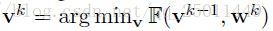
对 进行更新。例如,可令 。当 固定时,最优的 可以通过以下公式得到:
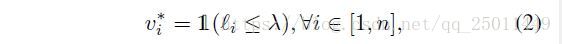
其中 为指示函数(原谅这里打不出空心的数字1)。公式(2)直觉上解释了预定义的课程,被称为自步学习。首先,当固定 更新 时,小于阈值 的样本被称为“easy”样本,且会为选入训练样本( )。否则,就不会被选中( )。然后,当固定 更新 时,分类器只会在“easy”样本中被训练。超参 控制学习的速度和模型的“age”相对应。当 很小时,只有loss很小的样本能被考虑。当 增大时,更多较大损失的样本会被加入训练以便得出一个更为成熟的模型。
函数 指定了一个课程,即在训练中使用的具有相应权重的样本序列。当 固定,它的最优解,例如公式(2),计算了时变的权重,这些权重控制了学习每个样本的时机和attention。最近的研究发现了多个预定义的课程,并在许多实际应用中进行了验证。
本文从数据研究学习课程。第三小节介绍了利用MentorNet学习数据驱动课程的方法。第四小节讨论了一种将MentorNet和StudentNet结合在一起通过mini-batch训练来优化公式(1)的算法。
3. Learning Curriculum from Data
现有的课程要么是预先确定为 的解析表达式,要么是计算样本权重的函数。考虑到学生网路的反馈,这些预定义的课程不能做相应的调整。本节讨论一种新的通过神经网络的方式来学习数据驱动的课程,称为MentorNet。我们学习了MentorNet 来计算每个训练样本的时变权重。假定 是网络 的参数。给定固定的 ,我们的目标是去学习一个最优的 :
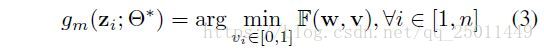
其中 指MentorNet关于第 个样本的特征。
3.1. Learning Curriculum
MentorNet可以通过1)近似存在的课程或2)发现新的课程来习得。
Learning to approximate predefined curriculums.
第一个任务是去近似一个预先定义的课程。最小化以下的目标函数:
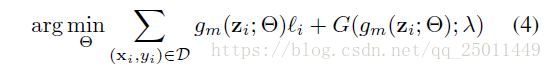
公式(4)同时适用于凸和非凸的 。这篇文章用了下面的课程函数,这个课程函数也和鲁棒的非凸惩罚的有关。
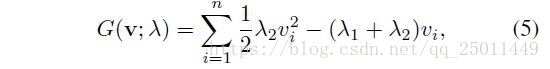
其中, ,由于G是凸函数,因此公式(3)有封闭的最优解,对于固定的 ,定义公式(3)中的 ,那么根据公式(5)可得到:
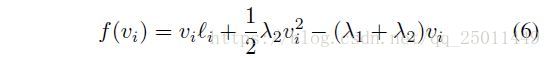
求导并带入公式(3)可得:
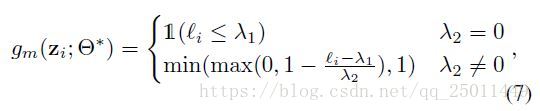
根据作者分析,在上式中,当 时,与自步学习原理相同;当 时,当 ,那么这个样本就会被看作“hard”样本,不会被选入训练;否则样本会按照 进行线性加权进行训练。
Learning data-driven curriculums.
下一个任务就是学习单纯由数据驱动的课程。首先在训练集的一个子集中进行学习,这时的权重很接近最优的。这篇文章里作者用的二值的权重,如果是正确的标签就置1,即保留下来。直觉上,这个过程先打渔模拟测试,课程是有教师和学生共同决定的。
在完整目标数据集中,正确标签上的信息可能并不总是可用的。在这种情况下,我们在一个不同的小数据集中学习课程,其中正确标签是可用的。直觉上,它类似于学生先学习一个主题的教学策略,然后将策略转移到一个相似的主题上。根据经验,第5.1小节证实了CIFAR-10的一小部分的学习课程可以应用于目标CIFAR-100数据集。
这里还介绍了一个burn-in(预热,磨合吧可以翻译成)的过程。那就是固定一个服从Bernoulli分布的潜在权值变量,这就相当于是dropout了。
MentorNet architecture.
关键的来了,如何设计数据驱动的课程。
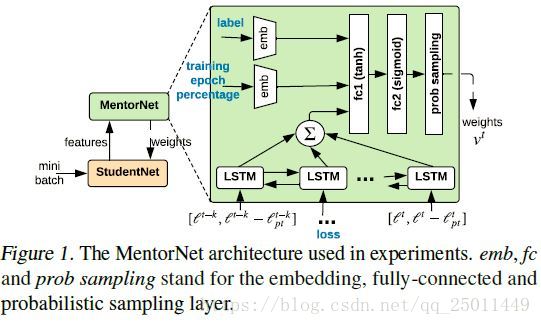
作者发现MentorNet可以有一个简单的架构。附录D显示,即使是基于两层感知器的MentorNet也可以合理的近似现有文献中的课程。然而,作者使用了图1所示的MentorNet体系结构,与传统的网络体系结构相比,它工作得相当好。它接受mini-batch的输入,并输出相应的样本权重。特征 包括(loss, loss difference to the moving average, label and epoch percentage.)用一个双向的步长为1的LSTM编码损失和损失差。
标签和训练epoch percentage由两个独立的嵌入层编码。epoch percentage表示为0到99之间的整数。它表示学生的训练进度,0表示第一阶段,99表示最后一阶段。将LSTM和嵌入层的连接输出送入两个全连通层
,其中
使用sigmoid激活来确保输出权值在0和1之间有界。图1中的最后一层是概率抽样层,用于在已学习的MentorNet上实现在burn-in
过程中的样本dropout。
3.2. Discussion
这里说MentorNet概念上更具一般性,应用起来更有灵活性,可以通过加入不同的MentorNets来改变课程,而不需要改变工作流。因此作者也对于预定义的课程学习了MentorNet。预定义的课程G未知,作者直接对MentorNet的输出和预期的权值误差最小化。
这篇文章希望解决受污染标签的问题,有趣的是StudentNet和MentorNet一同被学习时可以得到一个潜在的和鲁棒M-estimator相关的目标函数。
假设下式是对于损失变量 的最优的样本权重函数:
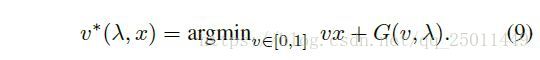
由于MentorNet 是对公式(9)的一个近似,它的性质可以通过公式(9)被研究。给定一个 和一个随 递减的函数 ,潜在的目标函数(公式(1))可以由下式被得到:
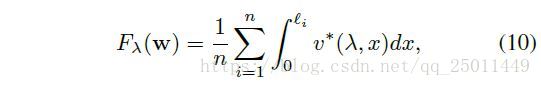
基于以上内容,课程函数(5)的潜在目标函数便可以被得到。
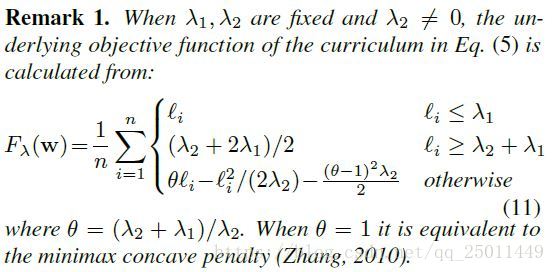
可以看出来根据 的大小来选择目标函数,超参 在这里起着非常重要的作用。当 那么损失就和non-convex robust loss一致。
对于数据驱动的课程,若MentorNet满足一定条件,就有:

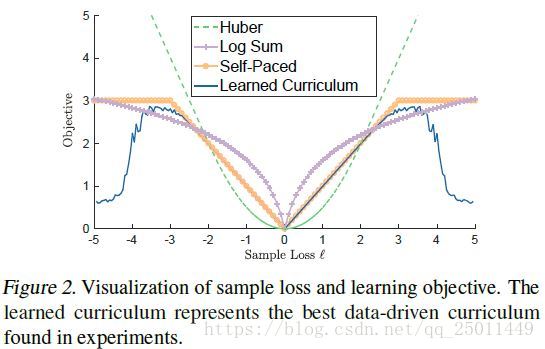
这个命题是说样MentorNet,即本权重函数随着损失函数递减,那么就存在这一个鲁棒的目标函数满足上式,比如Huber、log-sum等。
该命题表明,存在一些与鲁棒M估计相关的MentorNets。图二可以看出,在损失比较小的时候图中各个目标函数表现相近,对于比较大的损失,不同的方法在不同程度上表现出了鲁棒性,但是大的损失意味着标签可能受噪声污染了,作者提出的方法直接把这些样本的权值调到很小,相当于直接剔除了。命题1并不能保证每个MentorNet都有一个潜在的鲁棒的目标函数。相反,它显示了MentorNet学习这种健壮的目标的能力。
4. The Algorithm
在相关工作中使用的交替最小化算法,对于深度CNNs,特别是对于大数据集来说,是非常棘手的,有两个重要原因。首先,在确定 时最小化 的子程序中,随机梯度下降法在收敛前通常要经过很多步。这意味着它可能需要很长时间才能通过这个子步骤。然而,这样的计算通常是浪费,特别是在最初的训练的一部分,第二,最小化 时固定 的子程序通常是困难的,因为固定向量 可能不仅消耗大量的内存,而且还阻碍并行训练多台机器上。因此,利用深度网络优化目标需要在算法层面上进行思考。
由此作者提出了SPADE
(Scholastic gradient PArtial DEscent)。该算法结合给定的MentorNet对StudentNet模型参数w进行优化。它提供了一种简单而优雅的方法,可以在mini-batch上随机地最小化w和v。作为一般方法,它也可以取G的输入。
先上伪代码:

对于 和 的更新都是基于mini-batch中的小部分数据,当G(带权重的样本)被使用了就用随机梯度下降更新 ,否则就先不更新。
在标准假设下,定理1表明算法稳定并收敛于一个固定的点(收敛到全局/局部极小值是不能保证的,除非在特殊结构的非凸目标中)。这个定理描述了模型参数w的稳定性。对于权值参数v,由于它被限制在一个紧集中,收敛到一个固定点并不总是有保证的。由于模型参数更为重要,我们只提供了模型参数的详细描述。
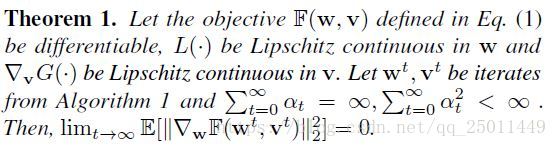
对于手工设计的课程,可能不清楚这种预定义的课程是否会通过mini-batch训练收敛在哪里,甚至是否收敛。定理1表明,所学习到的课程可以收敛并产生一个稳定的StudentNet模型。该算法可以代替在相关工作中交替最小化的方法。
5. Experiments
对于受污染的或有噪声的训练数据,MentorNet的表现还是很出色的,具体的实验结果可以参考原论文。
6. Related Work
作者列举了相关的一些工作,与这些工作相比,作者的这篇文章关注的是用学习到的课程去训练deep CNNs并且在训练数据受污染的情况下。在5.1小节的实验中,使用部分CIFAR-10中的数据训练的MentorNet被用在了CIFAR-100中。
7. Conclusions
本文提出了一种新的deep CNNs在受污染标签上的训练方法。本文的工作建立在课程学习的基础上,并提出了通过名为MentorNet的神经网络学习数据驱动课程的方法。提出了一种利用MentorNet对大规模数据联合优化深CNNs的算法。作者对受控噪声和真实噪声的数据集进行了全面的实验。作者的实证结果表明,通过学习数据驱动课程,可以有效地提高在标签被破坏的基础上训练的深度网络泛化能力。
有关的一些推导和证明在附录里供大家参考。