1. 概述
这篇文章提出了一种基于LASSO回归的通道选择和最小二乘重构的迭代两步算法,有效地对每一层进行修剪。并进一步将其推广到多层和多分枝的场景下。论文中的方法能够减少累积误差并且提升对于不同结构的适应性。该方法在VGG-16数据集上实现了5倍加速并且只有0.3%误差提升。更重要的是文章中的方法可以用于加速像ResNet和Inception,在加速两倍的情况下只牺牲了1.4%和1.0%的准确率。基于caffe的代码开源:channel-pruning
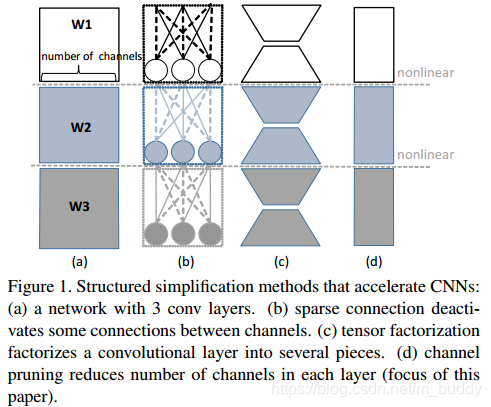
图中(a)代表原始的网络结构,接下来就要对其进行剪裁,可以分为如下几种情况:
1)sparse connection,也就是是的网络中的神经元或是channel连接稀疏;
2)tensor factorization,采用类似GoogleNet之类的结果来降低参数量。
3)channel pruning,就是裁剪channel来使得网络减小。
在这篇文章中提出了一种利用通道内部荣誉实现一种时间推理的通道剪枝方法。这个方法的灵感来自于张量因式分解的启发,而不是依靠分析滤波器的权重大小。这是通过使剪枝之后的网络在剪枝之处特征图的重构错误最小化实现的。
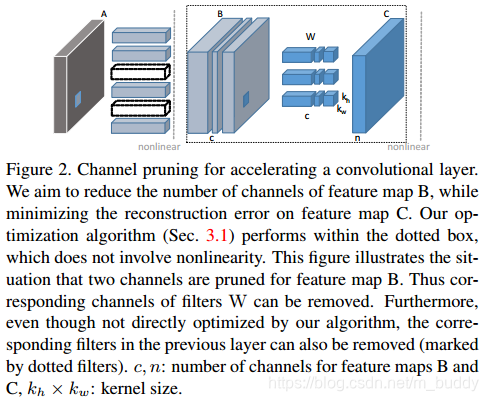
上图展示了通道剪裁加速网络的示意图。我们减少feature map B的数量,同时使得由剪裁之后的B得到feature map C的重构误差最小。上图中B前面的两个channel被剪裁掉了,对应在B中的feature map也会被剪裁掉。
通道剪裁分为两步:
1)通过LASSO回归选择重要的channel,剪除不重要的channel;
2)使用最小二乘法去减小剩余feature map重构下一层feature map的误差。
在VGG-16网络上实现了4倍加速,而且只增加了1%的top 5错误率,与张量分解结合可以使其实现5被加速且只增加0.3%错误率。在ResNet-50与Xception-50上实现2倍加速,只损失了1.4%与1.0%的准确率。
2. 剪枝
2.1 基本结构
通道剪裁涉及到两点:选择需要剪裁的通道;使用剩下的通道去重建下一层的feature map,然后使得这个重建的误差最小化。
那么接下来就是需要解决如何确定剪裁的通道(规定了必须剪裁掉的数量)并且使得重构的误差最小化。这就是一个组合优化问题,那么论文中是怎么做的呢?那就是将这个问题转换为一个最优化问题,如下形式:
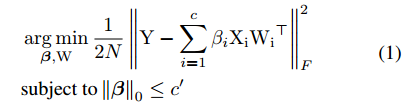
其中
的矩阵,然后再通道维度上进行采样;
是滤波器的权重;
是二值选择标量,为0就表该通道被删除掉了;至于
可以理解成为,当前裁剪层的下一层的feature map。本人这里对其这样做的具体实现无法想出,还是后面乖乖去看看它的代码怎么写的吧,要是最这个知道的朋友可以深入交流一下。
直接撸上面的最优化目标是很难的,论中对问题进行了转化,得到
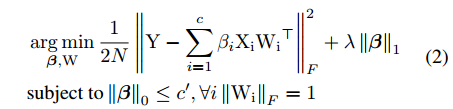
然后就是在这样的给定条件下去寻找最优的channel组合,不重要的channel也就是在这个过程中被删除掉的。这个思路类似于
范数的最优化求解过程(稀疏表达),也就是系数为0的那就删除掉。至于后面就是对该问题进行变形然后固定参数迭代求解了,跟GMM模型求解的套路一样的。
step 1: 固定参数
求取
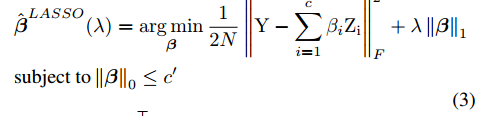
step 2: 固定参数
求取
,
固定了,那就求取下面的目标函数
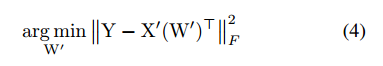
多层的pruning和单层的pruning是一样的,论文中是按照layer by layer的形式去计算的。
2.2 分支结构剪枝
在文章之前的内容里面讨论了如何在一层中实现剪枝,并且也推广到了整个模型(layer by layer),但是这些都是类似于VGG的网络结构,那么对于具有分支的结构,要怎么进行剪枝呢?
看下图中ResNet的剪枝,主要在两个方面:一个是残差块shortcut包围的内部feature map;第二个是残差块的输出与输入feature map。对于第一个可以使用上面提到的方案进行剪枝。对于第二个论文中说是不去拟合
而是直接去拟合
。
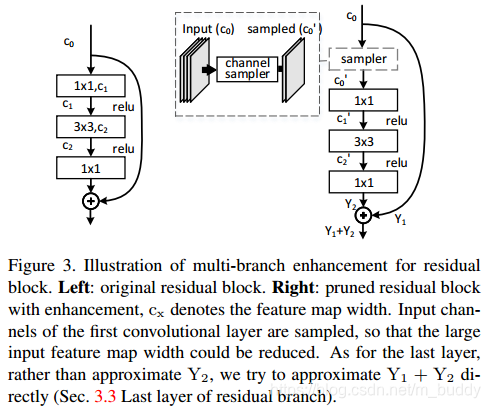
残差网络的最后一层: ResNet的输出是由两个部分组成的
,论文中指出在该处拟合得到是
,其中
是之前剪裁之后生成的feature map。在剪裁的时候因为有shortcut的存在,与此相连的对应部分变化是一致的。
残差网络的第一层: 在上面图中的展示的残差网络的输入层是不能进行剪裁的,但是可以在第一个卷积的前面使用上文中的方法,有点不同是在共享的feature map上做操作,上图中右半部分。
3. 实验结果
论文首先将自己提出来的使用最优化组合出来的channel选择与按照权重大小排序的方法进行对比,得到
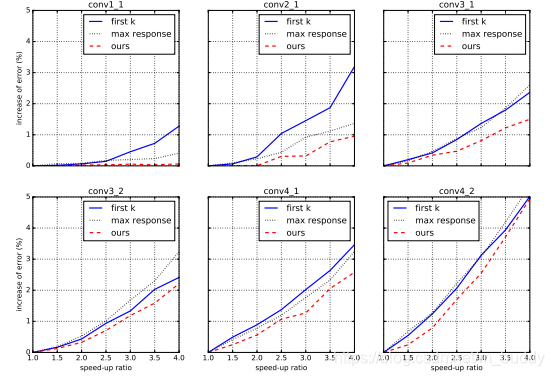
从图中可以看出,与在论文《Pruning Filters for Effective ConvNets》中的结果进行对比,可以看到这篇文章给出的结果好于它的。

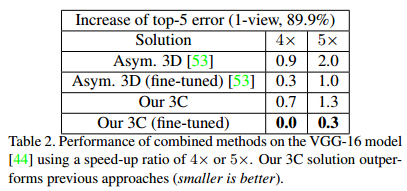
在此之外,论文还对剪枝进行了优化提出了3C算法。论文最后给出了3C(spatial、channel factorization,and channel pruning)的加速方法,其结果见表2。
4. 个人总结
这篇论文给出了较为科学地channel选择办法,而不是以大欺小似的选取top k之类的,至少有了一个较为数学的解释。这篇文章所涉及到的代码也是开源的,做模型压缩不接触代码是不行的,论文中的看得也是一半一半,具体怎么整的还是撸撸它的代码实现吧。关于ResNet的剪枝,有兴趣的可以交流一下。