1. 概述
这篇文章中给出了一种叫作SFP(Soft Filter Pruning),它具有如下两点优点:
1)Larger model capacity。相比直接剪裁掉网络中的filters,再在这个基础上finetune,这篇论文中的方法将其保留,这为优化网络的表达以及任务能力提供了更多空间。
2)Less dependence on the pretrained model,采用上述的方法可使网络连续剪枝和重新练,可以从网络的训练开始就进行剪枝,不需要再训练好一个模型之后再剪枝,节省了很多时间。
使用论文中的方法使得ResNet-101节省了42%的计算量,而且top-5的错误率还获得了2%的提升!
论文地址:Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks
代码地址:soft-filter-pruning
在下面一幅图中比较了论文中给出的SFP算法与传统剪枝算法(Hard Filter Pruning)的比较。
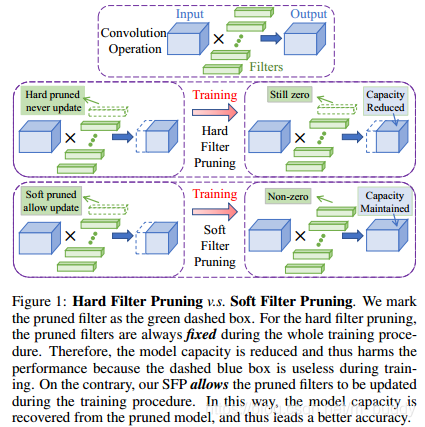
传统减值方法中filters被删除掉了就不会继续回到网络中参与训练,需要预训练模型,剪枝之后再fintune去逼近原来的状态。这样的结构限制了网络的表达能力。相反论文中提出的方法是在训练的时候边剪枝边训练,一个epoch之后对模型剪枝,剪除的filters其内部权值全部被置为0,然后下一个epoch训练。如此往复得到最后的模型。这样做的好处是剪枝不是不可恢复的操作,网络的表达能力并没有被减小且精度得到了保障,同时网络被剪裁。
2. SFP算法
2.1 算法整体流程
下图是算法的整体流程:
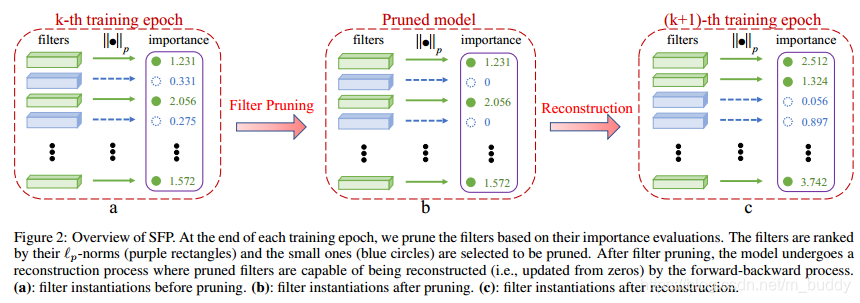
在上图中对
次epoch进行剪枝,检测的策略是根据
进行度量,之后剪除比较小的权重(也就是filters置为0)。之后再在下一个epoch中进行迭代。
2.2 算法具体步骤
对于CNN网络中的卷积参数可以使用
来表示,其为
,代表第
个卷积层的卷积参数矩阵,
代表第
个卷积的feature map数量,
代表卷积核的尺寸。那么对应的第
层的feature map为
,空间尺度为
,下一层的feature map尺度为
,因而卷积操作就可以被描述为:
其中,
代表对
层的feature map做卷积运算的第
个filter。这里开始引入剪裁,假设对第
层的剪裁比例是
,那么该层输出的feature map就会从
减少到
,也就是输出的feature map会变为
。
论文中使用的剪枝度量是
,也就是下面的形式:
有了度量指标之后就是在每个epoch之后对网络进行剪枝了,其算法可以被描述为:

论文指出:在剪枝步骤中使用相同的剪枝策略同时剪除所有层中的filter,而且都是使用同一个裁剪比例
。至于论文中关于网络剪裁之后的计算复杂度计算部分也就是根据你剪裁的力度来的,这里就不多说了。
3. 论文实验结果
3.1 实验结果
首先,来看一下论文中的方法与之前写到的方法之间的比较吧
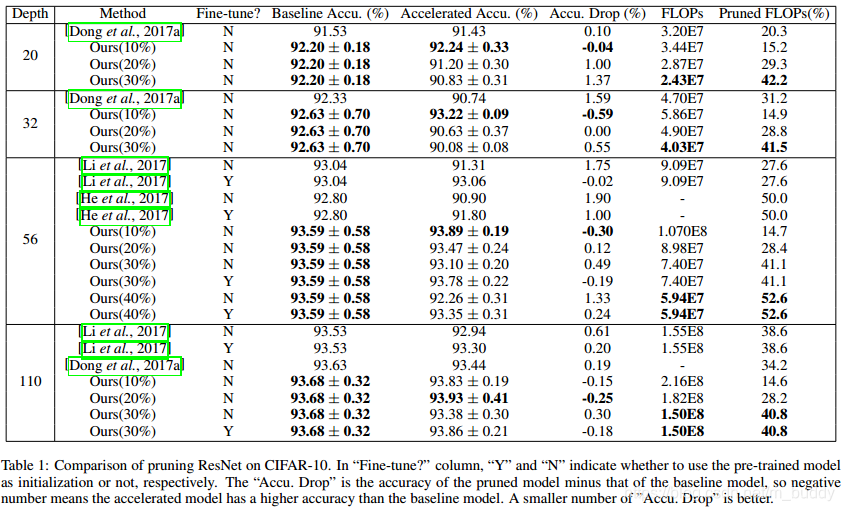
上面给出了之前将filter pruning时候给出的方法,这些方法是在filters的选择上做文章,之前的文章中有写,有兴趣的可以往回找找。从上面的结果中可以看到这篇论文中的方法比之前的方法都是要好的。
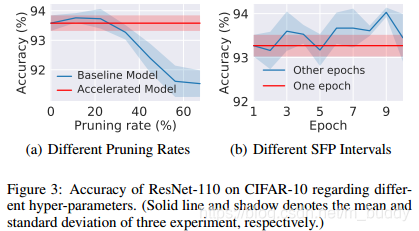
下图给出了剪裁的比例与baseline的关系,a图;在裁剪为30%情况下的baseline与迭代的轮数的关系,b图。
3.2 与 的选择问题
在之前的论文中有说 与 之间的谁好谁差,总的来说这两个差不太多,这篇论文中经过实验给出的结论指出L2-norm比L1-norm具有更好的表现,这是因为L2-norm对于权值较大的数相比L2-norm具有横好的区别能力。
3.3 对不同网络结构的处理
对于直通类型的网络结构(VGG)这里就不作讨论了,主要是看下对其论文中提到的ResNet网络结构是怎么剪枝的进行分析。但是在论文中没有具体给出作者是怎么做的,只有去它给出的代码里面去找了。