0 摘要
在自然图像上训练的深度神经网络都表现出一种奇怪的现象:模型第一层的参数和Gabor filters的参数非常相似(也就是说模型拥有经典图像算法中具有的优秀性质,Gabor filter是比较通用的滤波器,也就是说模型在一开始也要完成一些常规模式的计算过程,这一点和经典图像算法是一样的)。第一层的特征并不是特定于某一数据集或者某一任务,而是通用的特征,它们适用于许多数据集和普遍的任务。在较深的模型层,特征会从通用的特征逐渐转换为更专业的特征(和任务、数据集紧密相关的特征),这种转换目前尚未有广泛的研究(先用成熟通用的模式解决,随着问题的深入,再加入一些与问题紧密相关的方法,来更好地完成一件事)。本文,我们通过实验量化深度神经网络每层神经元的通用性与特殊性,并展示一些令人惊讶的结果。
1 介绍
现代深度神经网络都表现出一个有趣的现象:模型第一层的参数和Gabor filters的参数非常相似。这些过滤器的看起来非常通用。 这种现象不仅发生在不同的数据集中,甚至还包括不同的训练任务中,包括监督图像分类,无监督密度学习,以及无监督学习稀疏表示。
无论损失函数和图像数据集如何变化,在第一层上发现这些标准特征似乎都会存在,因此,我们称第一层特征是通用的。 另一方面,网络最后一层上计算的特征在很大程度上依赖于所选择的数据集和特定的任务,因此,我们称最后一层特征是特定的。 例如,在已成功训练的,以分类为目标的N维softmax输出层的网络中,每个输出单元将特定于特定类。 这就是一般特征和具体特征的直观概念,我们将在下面提供更严格的定义。 如果第一层特征是通用的,而最后一层特征是具体的,那么在网络中的某个位置一定会发生从一般特征到具体特征的转换。 这会有如下的问题:
1. 我们可以量化模型的某一层的特征到底是通用的还是具体的吗?
2. 转换是在某一层上突然发生,还是在几层上展开?
3. 这种转换发生在网络的什么地方:网络顶端,网络中间,还是网络底端?
我们对这些问题的答案非常感兴趣,因为,如果网络中的特征是通用的,我们能够将它们用于迁移学习。 在迁移学习中,我们首先在基础数据集上训练一个基础网络,然后我们将学习到的特征重新调整,迁移到第二个目标网络,在目标数据集上进行训练。 如果特征是通用的,这意味着此做法将起作用,第二个目标网络会取得不错的效果。(迁移学习:以模型为媒介,将在一个领域中学到的知识应用到另一个领域上,如果两个领域的共性比较大,那么迁移学习的效果会比较好。如果一个网络层比较通用,那么迁移到一个新的问题上也会比较好用。)
当目标数据集明显小于基础数据集时,迁移学习可以成为一种强大的工具,可以在不过拟合的情况下训练大型目标网络。
通常,迁移学习的方法是首先训练基础网络,然后将其前n层的参数复制到目标网络的前n层中。然后,目标网络中剩余的层进行随机初始化,并针对目标任务进行训练。这里有两种选择:a)在目标任务中对目标网络所有的参数进行微调;b)将迁移过来的参数固定,在训练期间不发生更改,仅仅对随机初始化的参数进行训练。是否需要微调目标网络前n层的参数取决于目标数据集的大小和前n层中的参数数量。如果目标数据集很小且参数数量很大,那么微调可能会导致过拟合,因此前n层的这些参数通常会被固定。如果目标数据集很大或参数数量很少,那么过拟合不是问题,可以微调网络的所有参数到新任务上,以提高性能。当然,如果目标数据集非常大,则几乎不需要迁移学习,因为可以在目标数据集上从头开始学习低层次的特征。我们将在以下部分中比较这两种技术:对所有参数(包括前n层的参数)进行微调和固定前n层的参数不变。
本文的贡献如下:
4. 我们定义了一种方法来衡量某一层是通用的或具体的程度,即该层的特征从一个任务迁移到另一个任务的程度(第2节)。 然后,我们在ImageNet数据集上训练卷积神经网络,并描述特征从通用到具体的逐层过渡(第4节),其产生四个结果。
5. 当使用迁移的特征,而没有进行微调时会导致网络性能下降。这一现象,我们认为有两个原因:(i)特征本身的特异性;(ii)在相邻层上的神经元之间存在共适应性,从基础网络中将它们分离会导致难以优化。 (4.1节)
6. 当基本任务和目标任务的差异很大时,我们发现了迁移的特征会降低网络的性能。 (4.2节)
7. 在相对较大的ImageNet数据集中,我们发现,对低层的网络权重进行随机初始化 VS 迁移低层网络的权重 后者的表现更好。(4.3节)
8. 最后,我们发现,用迁移的特征初始化网络,可以在微调后的新数据集上提高泛化性能。即使经过大量微调,基数据集的效果仍然存在。 (第4.1节)
2 通用特征和具体特征迁移性能的测试
我们已经注意到Gabor滤波器的特征会出现在第一层神经网络中。 在本研究中,我们使用的数据集是ImageNet,所做的任务是图片分类任务。将整个数据集随机分成两个子数据集,并以这两个数据集创建两个分类任务A和B。由于两个任务的数据集是从同一个数据集中分离出来的,因此两个任务的相关性非常大。一个任务学到的模型很有可能可以在另一个模型中发挥作用。将在任务A中学习到通用性特征应用到任务B中。
创建A和B数据集时,对ImageNet 1000类的物体随机分成两组,每组包含500类和大约一半的数据,每个类大约645000张图片。。我们在任务A上训练一个八层卷积网络,在B上训练另一个八层卷积网络。这些网络,我们称之为baseA和baseB,如图1的前两行。我们选择前n(
)层的特征并训练几个新的网络。在图1中,我们n=3。首先,我们训练以下两个网络:
1. B3B(图1第3行):前三层的参数从baseB中迁移而来,并且固定不变。第四到第八层的参数随机初始化,然后在数据集B上进行训练。
2. A3B(图1第4行):前三层的参数从baseA中迁移而来,并且固定不变。第四到第八层的参数随机初始化,然后在数据集B上进行训练。在这里,我们从在数据集A上训练的网络复制前3层,然后训练后面几层,学习更高层特征对新目标数据集B进行分类。如果A3B与baseB性能一样好,则证明第三层的特征是通用的特征。如果性能下降,则表明第三层的特征是baseA特有的。
上述的两个网络,迁移的层中参数是固定的。现在创建另外两个网络,在这两个网络中,迁移的层中参数是需要进行微调的。
3. B3B+:同B3B,只不过迁移的参数需要微调。
4. A3B+:同A3B,只不过迁移的参数需要微调。

4 结果和讨论
4.1 随机划分数据集A和B
随机划分数据集A和B,迁移学习的实验结果如图2所示。在以下每个解释中,我们将它们的性能与基准(图2中的白色圆圈和虚线)进行比较。
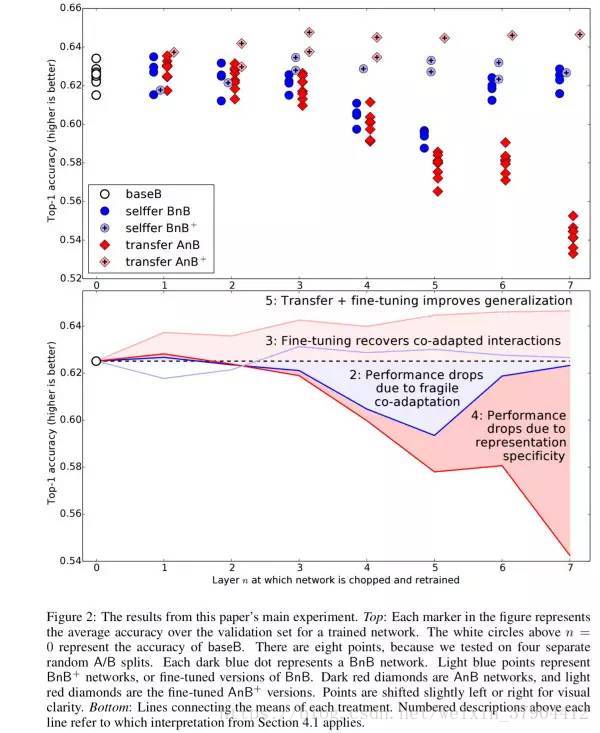
1. 白色圆圈baseB表明,神经网络经过训练,对500个类别进行分类,top1的准确率0.625(37.5%的错误率)。此错误率低于1000分类的网络。1000分类的网络top1的错误率达到42.5%。
2. 深蓝色圆圈BnB表现出一种奇怪的行为。正如所料,网络第一层的表现与baseB相同。也就是说,如果我们学习八层特征,固定第一层学习到的Gabor filter特征,重新初始化整个网络,并将其重新训练,会获得相同的性能。该结果也适用于第二层。然而,第3-6层,特别是第4和第5层,表现出更差的性能。可以说,中间几层的通用性不好。由于他们处于十分关键的位置,中间几层的特征变换还存在着很强的依赖性,这个现象称为fragile co-adapted features。作为一条流水线,相邻层之间的参数存在着很高的耦合性,他们往往是通过协同学习得到的,而不是各自单独学到的。因此将它们拆开学习会得到不好的结果(模型的前几层主要完成通用的特征变换,因此即使固定它们,效果也不会太差;到了最后几层,由于模型的特征已经基本构建完成,这时问题已经从一个复杂的高维非线性问题变成了相对低维的线性问题;最困难的就是中间的步骤,这里是要完成专用特征变换的关键位置)。第六层之后,模型又恢复了正常,因为重新学习的内容越来越少,学习起来足够简单。或者,可以说,第6-8层之间特征的适应性相比前面几层较小。
3. 浅蓝色圆圈BnB+表明,微调复制过来的参数可以防止在BnB网络中观察到的性能下降。
4. 深红色圆圈AnB展示了固定参数的迁移学习实验结果。第一层和第二层几乎完美地从A迁移到B,没有太多影响模型效果。可见,不仅第一层Gabor filter的特征是通用的,而且第二层特征也是通用的。第三层显示有轻微下降,第4-7层显示性能下降很明显。 层与层之间的耦合性也被打破,精度不断降低。
5. 浅红色圆圈AnB+展示了真正的迁移学习实验,可以看出模型的效果基本保持甚至有所提高。这是迁移学习中表现出的正常效果。同单独训练任务B相比,先训练任务A再训练任务B获得了更好的效果,说明训练任务A的数据确实起到了正向的作用。请注意,这种效果提升不应归因于较长的总训练时间(对于AnB+为450k基本迭代+ 450k微调迭代,而对于baseB为450k),因为BnB+网络也在相同的较长时间内训练并且没有表现出来同样的性能提升。因此,效果的优异源自于:数据A和B的相似度很高,此实验相当于接触了更多的训练数据,基础数据集的效果仍然存在,因此更加优异。
4.2 不相似的数据集
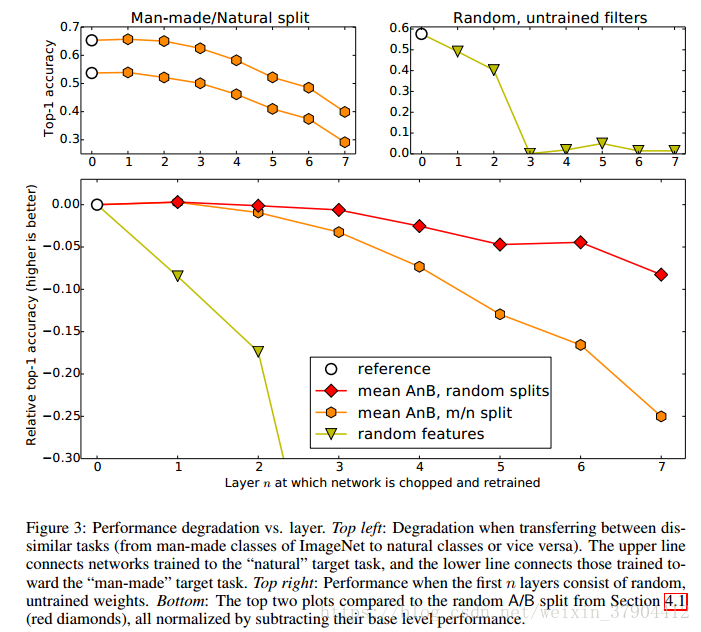
如果基础任务和目标任务变得不相似,特征迁移的有效性就会有所下降。我们在ImageNet中创建两个不相似的数据集A(人造对象类)和B(自然对象类)。与上述随机划分的A和B进行比较。随机划分的A和B是彼此相似的数据集。
图3的左上方子图显示了baseA和baseB网络(白色圆圈)和BnA和AnB网络(橙色六边形)的准确性。
4.3 随机初始化权重
我们还比较了随机初始化权重的情况,因为Jarrett等人论文表明,随机初始化的卷积核参数,ReLU激活函数,池化和LRN正则化的组合也可以有效学习特征。 他们在Caltech-101数据集上,训练了一个两层或三层的网络。那么,他们所认为的随机初始化卷积核参数,ReLU激活函数,池化和LRN正则化的组合能不能延伸到更大的数据集上,训练更深层的网络?
图3的右上子图显示了随机初始化前n层(
)的卷积核参数后,获得的精度。在第1层和第2层,随机初始化卷积核参数,使得性能迅速下降,然后在第3层和第3层以后下降到接近不变的水平,这表明在卷积神经网络中使用随机的权重可能不像在较小的网络规模和更小的网络中那样简单。