● 每周一言
别让偶尔的关心打败习惯的温暖。
导语
前面介绍了层次聚类法,在聚类效果上,层次聚类的最大问题是:有可能聚出链状类。本节要讲的 密度聚类法 可以克服这个缺点,其原理也更接近于直观意义上的聚类。那么,密度聚类的思想是什么?又有哪些常用算法?
密度聚类
密度聚类顾名思义,是一种基于样本密度的聚类思想。直观意义上理解,好比在一张地图上做人口密度分布图,密集区域通常会认为是城市所在地。
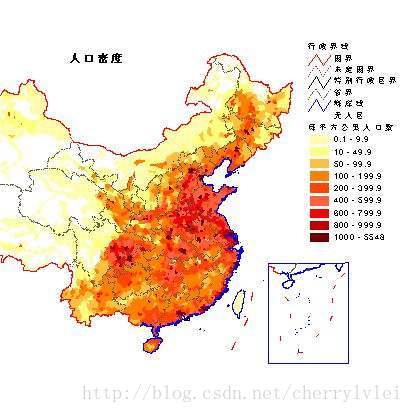
基于密度聚类主要的目标是寻找高密度区域,与基于距离聚类的不同之处在于,后者的结果通常表现为球状簇,而前者可以形成任意形状聚类。且只要参数设置合理,就不会出现链状类,不受噪音和离群数据点影响。
密度聚类最有名的算法叫做DBSCAN(Density-Based Spatial Clustering of Application with Noise)。既然是密度,那么自然就会涉及到范领邻域和数量。DBSCAN算法中用半径R表示邻域大小,用N表示邻域R范围内的样本数据点阈值数量。

根据参数R和N,DBSCAN将样本分为以下三类:
· 核心点 在邻域R内包含点的数量不小于N的样本点;
· 边界点 在邻域R内包含点的数量小于N,但是该样本点落在其他核心点的邻域内;
· 噪音点 既不是核心点也不是边界点的样本点。
如果只采用核心点计算聚类,DBSCAN可以看做k-means算法的变种。因为加上了边界点和噪音点的计算,DBSCAN算法比一般的距离聚类法更为强大。

DBSCAN算法流程如下:
1> 划分所有样本数据点为核心点、边界点或噪音点;
2> 删除所有噪音点;
3> 将距离在R之内的核心点之间连边,形成连通图G;
4> 计算连通G中的连通分量GCCi,形成初步聚类;
5> 把边界点划分到与之关联的核心点所在的类。
以上过程中还涉及到两个比较重要的概念,直接密度可达 和 密度可达。
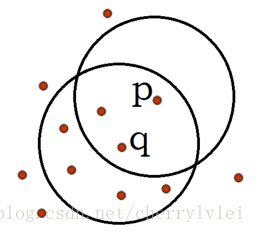
直接密度可达如下图所示,R=1,N=5,q是一个核心点。从对象q出发到对象p就是直接密度可达的。但是,从p到q不是直接密度可达,因为p不是核心点。
密度可达如下图所示,q直接密度可达p1,p1直接密度可达p,则称q到p是密度可达。
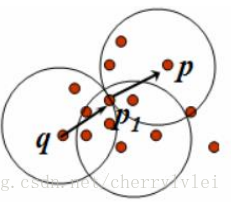
会发现,最后形成的每个类中的任意数据点p,在其所属类中至少存在一个核心点q使其密度可达,我们称之为p和q是密度相连的。
虽然密度聚类法优点很多,但是其时间复杂度也是相当之大,一般通过构建数据索引来降低其密度计算量。
以上便是密度聚类的讲解,敬请期待下节内容。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
