这篇博客介绍另一种类型的聚类算法——密度聚类。
密度聚类方法的指导思想:只要样本点的密度大于某个阈值,则将该样本添加到最近的簇中。这类算法可以克服基于距离的算法只能发现凸聚类的缺点,可以发现任意形状的聚类,而且对噪声数据不敏感。但是计算复杂度高,计算量大。
常用算法:
- DBSCAN
- MDCA
DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
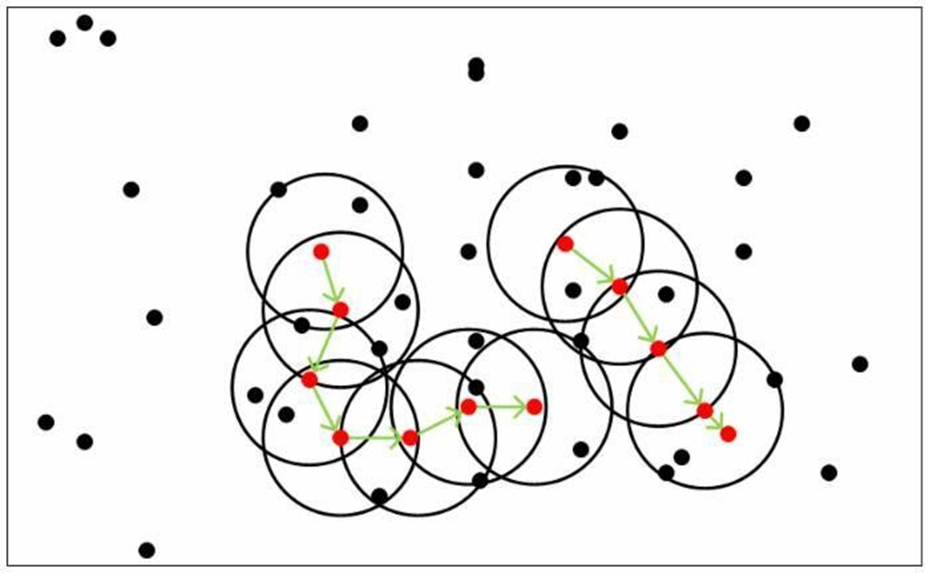
一个比较有代表性的基于密度的聚类算法,相比于基于划分的聚类方法和层次聚类方法,DBSCAN算法将簇定义为密度相连的点的最大集合,能够将足够高密度的区域划分为簇,并且在具有噪声的空间数据上能够发现任意形状的簇。
DBSCAN算法的核心思想是:用一个点的ε邻域内的邻居点数衡量该点所在空间的密度,该算法可以找出形状不规则的cluster,而且聚类的时候事先不需要给定cluster的数量。
概念
ε 邻域(ε neighborhood,也称为Eps):给定对象在半径ε内的区域
密度(density):ε 邻域中 x 的密度,是一个整数值,依赖于半径 ε
MinPts 定义核心点时的阈值,也简记为 M
核心点(core point):如果 ,那么称 x 为 X 的核心点;记由 X 中所有核心点构成的集合为 ,并记 表示由X中所有非核心点构成的集合。直白来讲,核心点对应于稠密区域内部的点。
边界点(border point): 如果非核心点x的ε邻域中存在核心点,那么认为 x 为 X 的边界点。由 X 中所有的边界点构成的集合为
。直白来将,边界点对应稠密区域边缘的点。
x∈X_nc;∃y∈X;y∈N_ϵ (x)∩X_c
噪音点(noise point):集合中除了边界点和核心点之外的点都是噪音点,所有噪音点组成的集合叫做
;直白来讲,噪音点对应稀疏区域的点。

直接密度可达(directly density-reachable):给定一个对象集合 X,如果 y 是在 x 的 ε 邻域内,而且 x 是一个核心对象,可以说对象 y 从对象 x 出发是直接密度可达的
密度可达(density-reachable):如果存在一个对象链
,如果满足
是从 {p_i} 直接密度可达的,那么称 {p_m} 是从 {p_1} 密度可达的。
密度相连(density-connected):在集合 X 中,如果存在一个对象 o ,使得对象 x 和 y 是从 o 关于 ε 和 m 密度可达的,那么对象 x 和 y 是关于 ε 和 m 密度相连的.
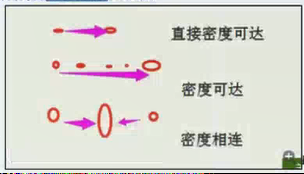
簇(cluster):一个基于密度的簇是最大的密度相连对象的集合C;满足以下两个条件:
- Maximality:若 x 属于 C,而且 y 是从 x 密度可达的,那么 y 也属于 C
- Connectivity:若 x 属于 C,y 也属于C,则 x 和 y 是密度相连的
流程

算法流程:
- 如果一个点 x 的 ε 邻域包含多余 m 个对象,则创建一个 x 作为核心对象的新簇;
- 寻找并合并核心对象直接密度可达的对象;
- 没有新点可以更新簇的时候,算法结束。
算法特征描述: - 每个簇至少包含一个核心对象
- 非核心对象可以是簇的一部分,构成簇的边缘
- 包含过少对象的簇被认为是噪声
优缺点
优点:
- 不需要事先给定cluster的数目
- 可以发现任意形状的cluster
- 能够找出数据中的噪音,且对噪音不敏感
- 算法只需要两个输入参数
- 聚类结果几乎不依赖节点的遍历顺序
缺点:
- DBSCAN算法聚类效果依赖距离公式的选取,最常用的距离公式为欧几里得距离。但是对
- 于高维数据,由于维数太多,距离的度量已变得不是那么重要
- DBSCAN算法不适合数据集中密度差异很小的情况
MDCA
密度最大值聚类算法,MDCA(Maximum Density Clustering Application)算法基于密度的思想引入划分聚类中,使用密度而不是初始点作为考察簇归属情况的依据,能够自动确定簇数量并发现任意形状的簇;另外MDCA一般不保留噪声,因此也避免了阈值选择不当情况下造成的对象丢弃情况。
MDCA算法的基本思路是寻找最高密度的对象和它所在的稠密区域;MDCA算法在原理上来讲,和密度的定义没有关系,采用任意一种密度定义公式均可,一般情况下采用DBSCAN算法中的密度定义方式
概念
最大密度点:
有序序列: 根据所有对象与p max 的距离对数据重新排序
密度阈值 ;当节点的密度值大于密度阈值的时候,认为该节点属于一个比较固定的簇,在第一次构建基本簇的时候,就将这些节点添加到对应簇中,如果小于这个值的时候,暂时认为该节点为噪声节点。
簇间距离:对于两个簇
和
之间的距离,采用两个簇中最近两个节点之间的距离作为簇间距离。
聚簇距离阈值 :当两个簇的簇间距离小于给定阈值的时候,这两个簇的结果数据会进行合并操作。
M值:初始簇中最多数据样本个数
过程步骤
1 . 将数据集划分为基本簇;
- 对数据集X选取最大密度点 ,形成以最大密度点为核心的新簇 ,按照距离排序计算出序列 ,对序列的前 M 个样本数据进行循环判断,如果节点的密度大于等于 ,那么将当前节点添加 中;
- 循环处理剩下的数据集 X,选择最大密度点 ,并构建基本簇 $C_{i+1} $ ,直到X中剩余的样本数据的密度均小于
2 . 使用凝聚层次聚类的思想,合并较近的基本簇,得到最终的簇划分;
- 在所有簇中选择距离最近的两个簇进行合并,合并要求是:簇间距小于等于 ,如果所有簇中没有簇间距小于 的时候,结束合并操作
3 . 处理剩余节点,归入最近的簇
- 最常用、最简单的方式是:将剩余样本对象归入到最近的簇
看一下动态图

