贝叶斯信念神经网络
bayes belief network (BNN),
朴素贝叶斯分类器需要特征之间相互独立的强条件,制约了模型的适用,
用有向无环图表达变量之间的依赖关系,变量用节点表示,依赖关系用边表示,
祖先,父母和后代节点。贝叶斯网络中的一个节点,如果他的父母节点已知,则它条件独立于他的所有非后代节点
每个节点附带一个条件概率表(CPT),表示该节点和父母节点的联系概率。


分类具有学习能力,
聚类没有学习能力,没有学习集
聚类的依据
1.密度
2距离
根据选定的点距离中心点的距离进行分类,距离较近的一些点倾向于归为同一类,距离交易员的点应归属不同的类,所定义的距离一般满足如下四个条件
d_ij>0,对一切i和j均成立
d_ij=0,当且仅当第i个样本与第j个样本的个变量在相同
d_ij=d_ji
d_ij<=d_ik+d_kj
绝对值距离
d_ij=|x_ik-x_jk|(k从1到p,进行求和)
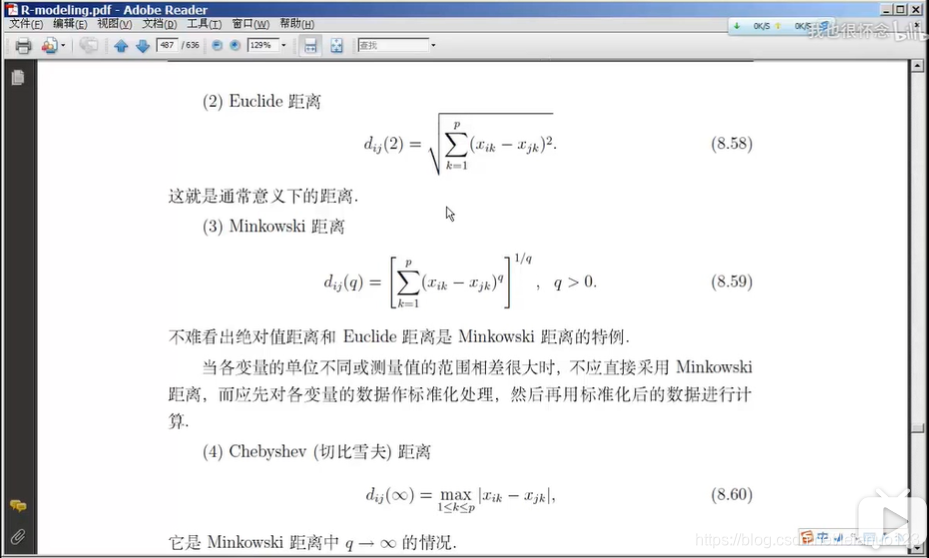
欧氏距离
马科夫斯基距离
切比雪夫距离
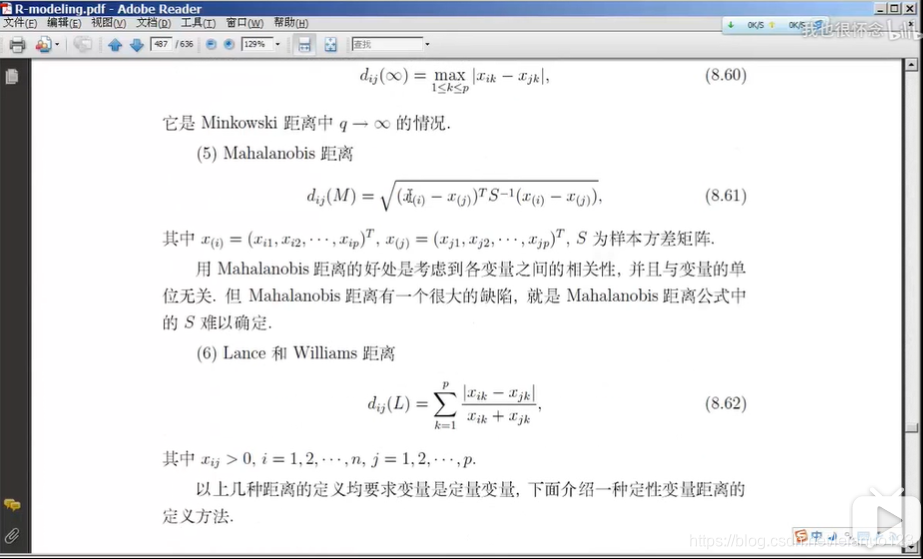
马氏距离
lance距离和Williams距离
离散变量的距离计算
再进行聚类的时候,需要先进行距离计算,再R语言中的距离的计算式dist(),通过距离的计算时,得到的是一个距离的矩阵。
在数据进行距离计算的时候,需要先将数据进行中心化和标准化处理,进行中心化和标准化的目的是将数据处理成统一的形式,从而再进行距离计算的时候,不会因为某一些数据的个体的差异而对整个的数据产生影响。
通常用的中心化处理
如下图中所述

中心化后处理的数据,数据的均值为0,方差阵不变
标准化变换
变换后的数据,每个变量的样本的均值为0,标准差为1,而且比标准化后的数据与变量的量纲无关。在R软件中,使用scale()函数进行标准化或者中心化,其使用格式是scale(x,center=TRUE,scale=TRUE)
极差标准化

极差标准化和标准化的区别是,极差化分母是最大值减最小值的差值。而标准化是标准差。
层次聚类的思想
1.开始时,每个样本各自聚为一类
2.规定某种度量作为样本之间的距离及类与类之间的距离,并计算之
3.将距离最短的两个类合并为一个新类
4.重复2-3,即不断的合并最近的两个类,每次减少一个类。直至所有的样本被合并为一类。
在第3步中,此时的距离时类与类之间的距离
而通常计算类与类的距离的方法有
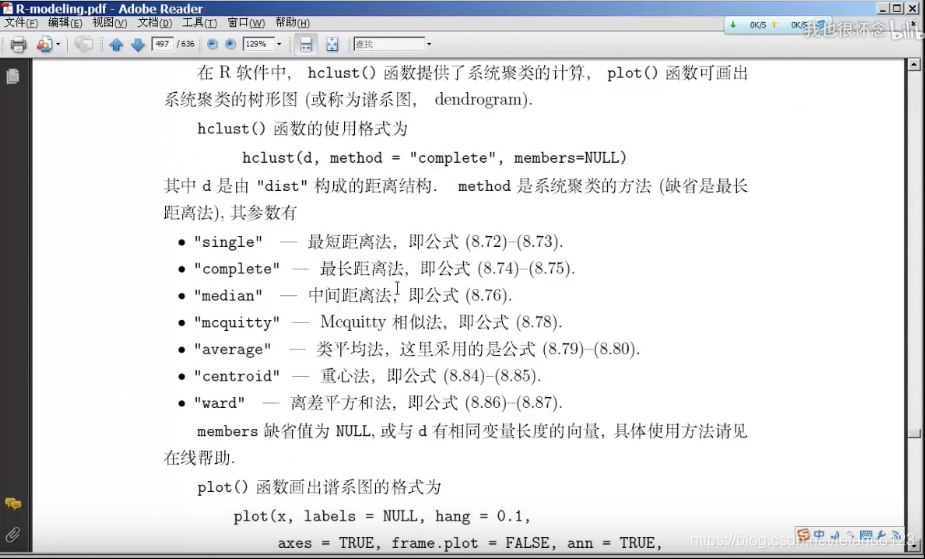
最短距离法
最长距离法
中间距离法
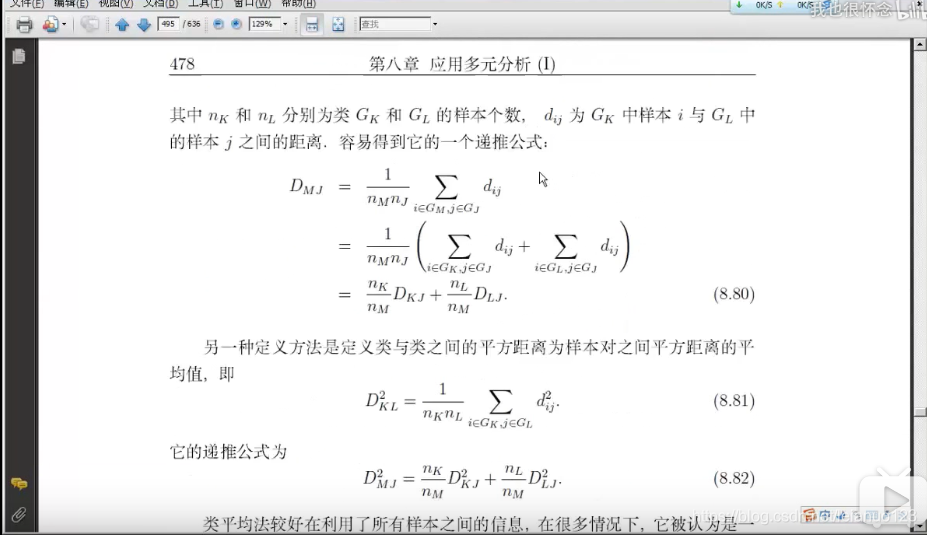
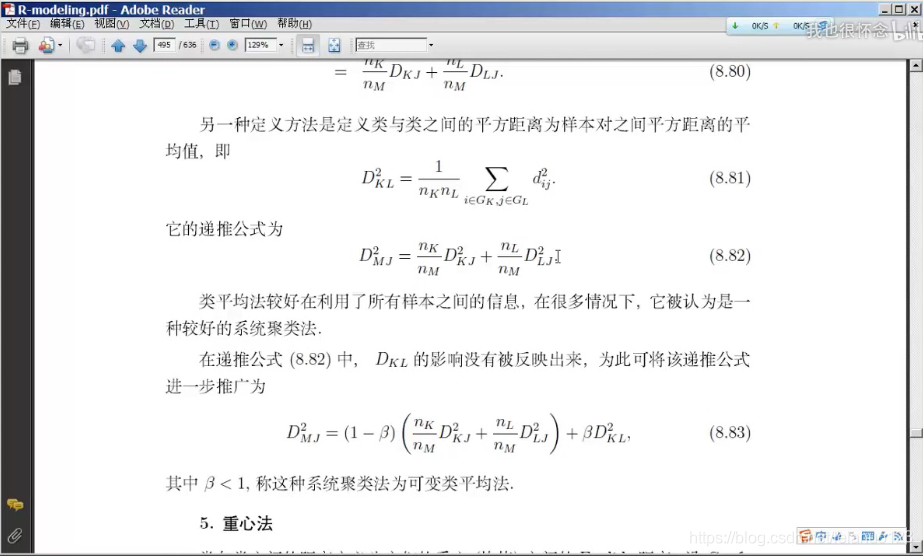
类平均法
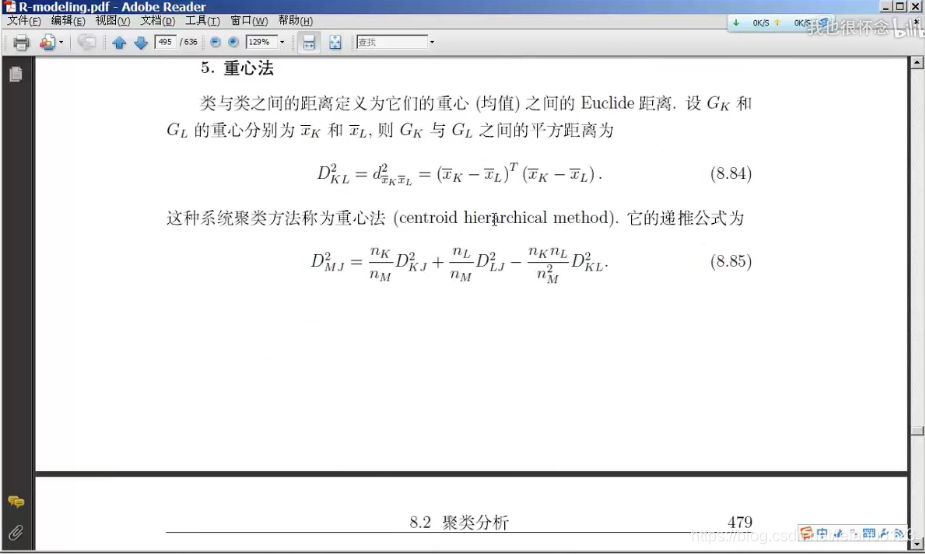
重心法
离差平方和法
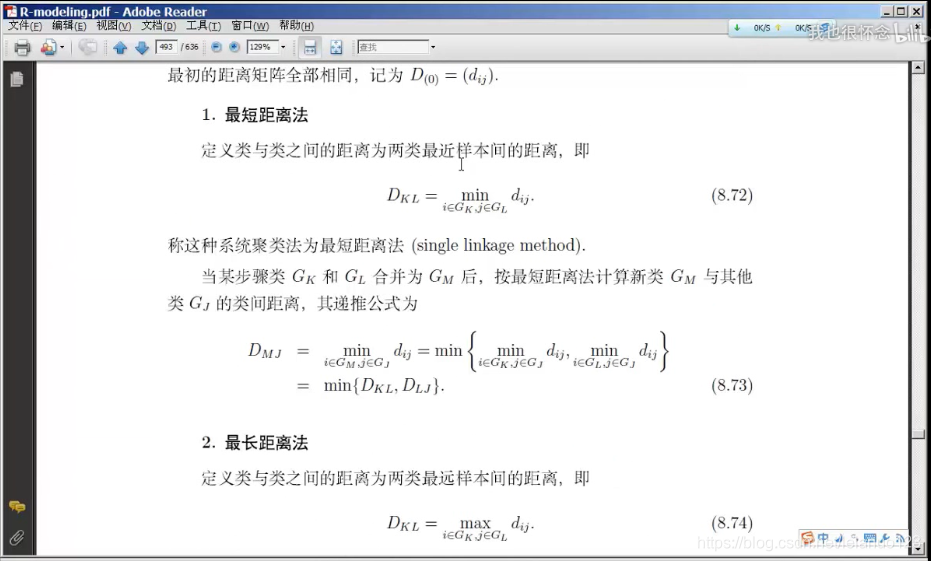
最短距离法中,将原来的两个类G_K,G_J按照最短距离法合并成一个新的类G_L,当再次进行聚类的时候,只需要分别求两个原小类与新类之间的最小距离
最长距离法
定义类与类之间的距离为两类最远样本之间的距离
方法与最短距离相似,只不过是求两个袁磊样本点之间的最远的距离,得到新类后,采用的方法与最短聚类法相似。
中间聚类法
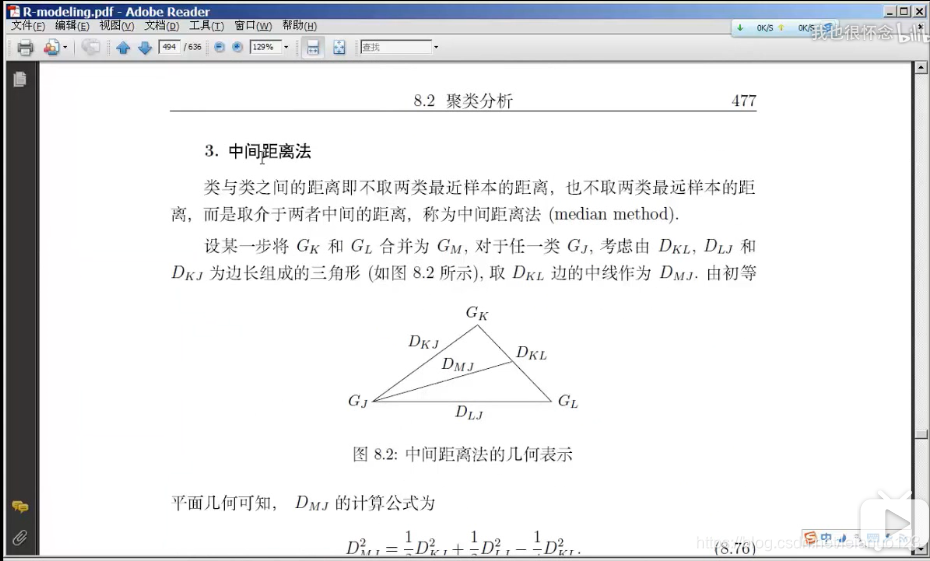

类平均法


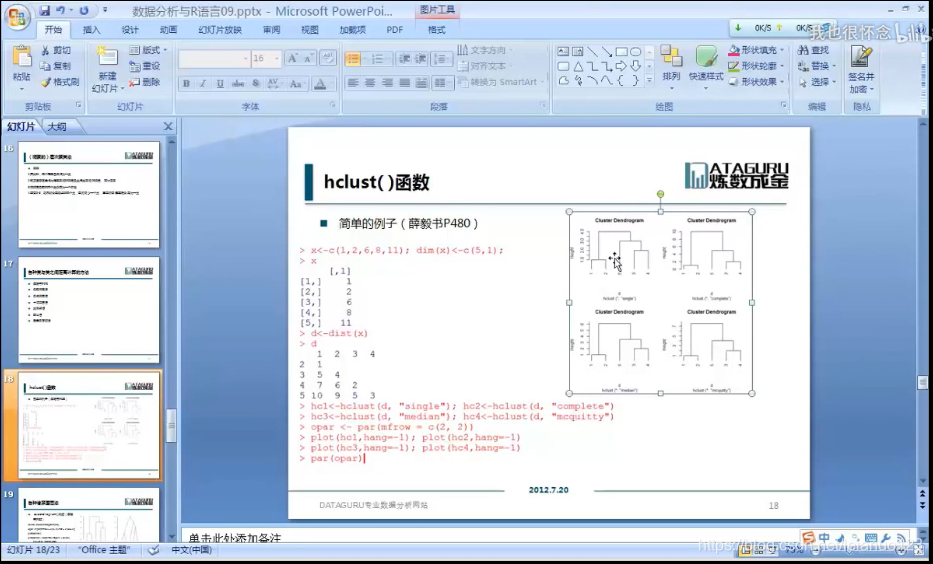
在R语言中,进行层次聚类的方式是
hclust()
其中使用的格式是hclust(d,method=,members=)
在 R语言中,采用rect,hclust()函数进行确定类的个数


聚类的总结
1.先对数据进行标准化
2.然后对数据进行距离计算
3对进行距离计算后的数据进行层次聚类
在聚类的时候,依据数据的特征,采用不同的距离算法进行聚类,结果会不同,
最终的结果应该每一类结果平均
动态与聚类算法
1.K-means方法
1.选择K个点作为初始质心
2.将每个点指派到最近的质心,形成k个簇
3.重新计算每个簇的质心
4.重复2-3直至质心不在发生变化
在R语言中,存在kmens (dataframe,K)
K-means 算法的优缺点
1.难以确定K(一般先用层次聚类,来初步确定K值)
2.有效率,且不容易受初始值的影响
3.不能处理非球型的的簇
4.不能处理不同尺寸,不同密度的簇5.离群值可能有较大的干扰(因此要先剔除)
2.K中心聚类算法
算法步骤
1.随机选择K个点作为中心点
2.计算剩余的点到这K个点的距离,每个点被分配到最近的中心点组成的聚簇
3.随机选择一个非中心点Or,用它来代替某给现有的中心点Oj,计算这个代换的总代价S
4.如果S<0,则用Or代替Oj,形成新的K个中心点集合
5.重复2,直至中心点集合不发生变化。
K中心法的实现:PAM
1.PAM使用离差平方和来计算成本S(类似于ward距离的计算)
2.R语言的的cluster包实现了PAM
3.K中心法的有点:对于"噪音较大和存在离群值的情况下,K中心法更加健壮,不想K-means那样容易受到极端数据的影响
4.K中心法的缺点:执行代价更高
通常在装了cluster包后,使用pam(data,K)
基于密度的算法(DBSCAN)
DBSCAN: Density -Bases Spatital Clustering of Applicattions with Noise
本算法将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类。
概念
1.r-邻域,给定点半径r内的区域
2.核心点,如果一个点的r邻域至少包含最少数目M个点,则称该点为核心点
3.直接密度可达,如果点P在核心点q的r邻域内,则称p是从q出发可以直接密度可达,如果存在点链p1,p2,…pn,p1=q,pn=q,p_i+1是从p_i关于r和M直接密度可达,则称点p是从q关于r和M密度可达的
4.如果样本集D存在点o,使得点p和q,是从o关于r和M密度可达的,那么p,q是关于r和M密度相连的。
算法基本思想
1.指定合适的r和M
2.计算所有的样本点,如果点p的r邻域力有超过M个点,则创建一个以p为核心的新簇
3.反复寻找这些核点直接密度可达(之后可能是密度可达)的点,将其加入到相应的簇,对于核心点发生""密度相连"状况的簇,给予合并
4.当没有新的点可以被添加到任何簇的时候,算法结束
基于网格的聚类方法CLIQUE
基于网格的聚类算法
两个重要的参数
网格的步长,网格的密度阈值
