● 每周一言
思考如脚印,踩的越深走的越稳。
导语
前面已经讲完三种聚类方法,剩下的模型聚类法,主要分为基于概率模型聚类和基于神经网络模型聚类两种。
其中基于概率模型的聚类方法较为流行。而在概率模型聚类法中,最典型、也最常用的就是高斯混合模型GMM了。那么,GMM是什么,又是如何聚类的?
GMM聚类
高斯混合模型(GMM,Gaussian Mixture Models),顾名思义由高斯模型组成,而高斯模型就是我们常说的正态分布,因此GMM可以理解为几个正态分布的叠加。

基于GMM的聚类,和K-means聚类有点相似,具体算法流程如下:
1> 随机生成k个高斯分布作为初始的k个类别;
2> 对每一个样本数据点,计算其在各个高斯分布下的概率;
3> 对每一个高斯分布,样本数据点得到的不同概率值作为权重,加权计算并更新其均值和方差;
4> 重复以上步骤2和3,直到每一个高斯分布的均值和方差不再发生变化或已满足迭代次数。
以下展示了一维数据集的GMM聚类执行图例(图片源自互联网)。
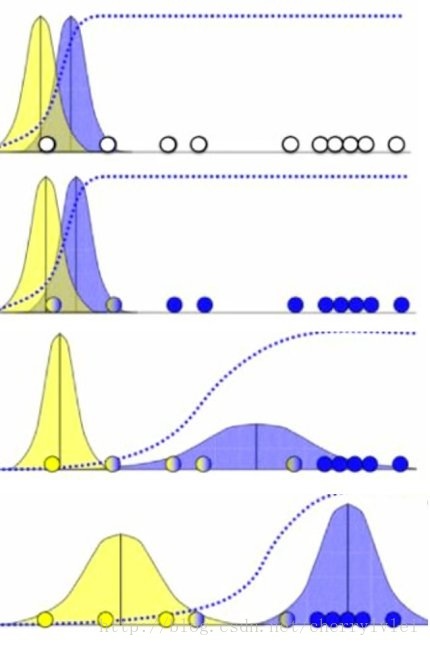
如果样本数据集是多维情况,需要计算协方差把不同维度之间的关联性考虑进来。
GMM聚类和K-means一样,分类受到初始值影响较大。不过GMM聚类完的样本可以同时属于多个类别,这种聚类又称为 软聚类。
其他的模型聚类法还有 基于PageRank的软聚类法,和 基于神经网络模型的SOM聚类法 等,有兴趣的读者可自行查阅文献资料。
以上便是常见的模型聚类法GMM聚类的讲解,敬请期待下节内容。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
