首先生成数据样本如下:
#!usr/bin/env python
#_*_ coding:utf-8 _*_
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X1, y1=datasets.make_circles(n_samples=5000, factor=.6,noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]],random_state=9)
print("{},{},{},{}".format(X1.shape,y1.shape,X2.shape,y2.shape))
X = np.concatenate((X1, X2))
print(X.shape)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()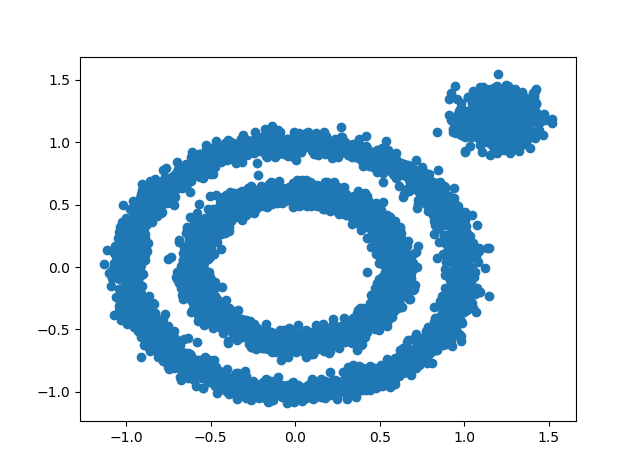
关于sklearn生成数据的形式参考直通车:
关于bdSCAN可先参考:直通车