● 每周一言
是学是玩,和时间赛跑。
导语
在实际生活中,无论是超市货架还是网络社交群体,都体现着归类的相似性,即所谓的“物以类聚,人以群分”。在机器学习中,专门有这么一类针对类别划分的算法,就是接下来要讲的聚类。那么,聚类的数学含义是什么?又有哪些常用算法?
聚类
所谓无监督学习,就是通过学习不带类别标签的样本,得到样本之间内在的规律和联系。而聚类则是无监督学习最常用,也是应用最为广泛的一种实现手段。
顾名思义,聚类就是把相似的样本归为一类。那么,如何度量样本之间的这种相似性?
我们知道,样本由特征组成,而特征又分为连续(有序)特征和离散(无序)特征两种。因此,样本相似性度量,其实就是样本特征之间的相似性度量。
对于连续特征的相似性度量,最常用的是闵可夫斯基距离,公式如下:
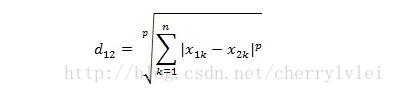
其中k表示特征序号,而p值不同距离含义不同:p = 1计算的是曼哈顿距离,p = 2就是我们最熟悉的欧氏距离,p → ∞时计算的则是切比雪夫距离。
不过,闵可夫斯基距离有两个明显的缺点:一是特征之间的量纲(单位)被等同对待,这通常是不合理的;二是未考虑特征值本身的分布规律,如遇到类似长尾分布,这种距离度量的效果往往大打折扣。第一点可以采用特征加权应对,第二点则可以采用特征值标准化或者分箱来应对。
除开闵可夫斯基距离,常见的连续特征相似性度量方法还有马氏距离、夹角余弦、Pearson相关系数等。

对于 离散特征的相似性度量,最直接的度量方法是01匹配法,即对应位置的特征相同则为1,不同则为0。基于01匹配法,可以用 Jaccard相似系数进一步计算样本之间的相似性。
此外,离散特征的相似性度量还可以采用VDM(Value Difference Metric)值差分度量法。不过VDM的前提必须是带类别标签的聚类,其算法原理是通过考虑不同离散属性值在相同类别标签下占比的关系,得出离散属性值之间的相似度。
以上提到的相似性度量都属于距离度量,而距离度量需要满足以下四个基本性质:
非负性: d(a, b) ≥ 0;
同一性: d(a, b) = 0,当且仅当a = b;
对称性: d(a, b) = d(b, a);
直递性: d(a, b) ≤ d(a, k) + d(k, b)。

然而并不是所有的相似性度量一定要满足以上四个性质,尤其是直递性。比如“人马”、“人”和“马”,“人马”分别与“人”和“马”相近,但是“人”和“马”却截然不同。
再比如,我的朋友之间并不一定是朋友,同样也不满足直递性。这涉及到了知识图谱中实体和关系的概念,在这里不多讲,有兴趣的读者可自行刨根问底。
这里顺便提一下软聚类。常规的聚类结果,样本最终只会归为某一类别,而软聚类则允许样本最终归为多个类别。
聚类的算法实现有很多,大体可以分为划分聚类法、层次聚类法、密度聚类法以及模型聚类法四种。接下来的几周,我将挑选几个常用的聚类算法深入讲解,敬请期待。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
