基于密度的聚类算法假设聚类结构能够通过样本分布的紧密程度确定,以数据集在空间分布上的稠密程度为依据进行聚类,即只要一个区域中的样本密度大于某个阈值,就把它划入与之相近的簇中。
密度聚类从样本密度的角度进行考察样本之间的可连接性,并由可连接样本不断扩展直到获得最终的聚类结果。这类算法可以克服K-means、BIRCH等只适用于凸样本集的情况。
常用的密度聚类算法:DBSCAN、MDCA、OPTICS、DENCLUE等。
密度聚类的主要特点是:
(1)发现任意形状的簇
(2)对噪声数据不敏感
(3)一次扫描
(4)需要密度参数作为停止条件
(5)计算量大、复杂度高
一、DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是基于一组邻域参数(ε,MinPts)来描述样本分布的紧密程度,相比于基于划分的聚类方法和层次聚类方法,DBSCAN算法将簇定义为密度相连的样本的最大集合,能够将密度足够高的区域划分为簇,不需要给定簇数量,并可在有噪声的空间数据集中发现任意形状的簇。
1、基本概念(参考西瓜书):
给定的数据集D={x(1),x(2),...,x(m)}
(1)ε-邻域(Eps):对x(j)∈D,其ε-邻域包含D中与x(j)的距离不大于ε的所有样本。
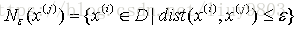
(2)MinPts:ε-邻域内样本个数最小值。
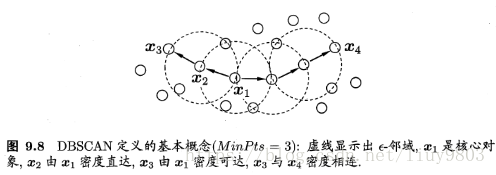
(3)核心对象:若x(j)的ε-邻域至少包含MinPts个样本,|Nε(x(j))|≥MinPts,则x(j)为一个核心对象。
(4)密度直达(directly density-reachable):若x(j)位于x(i)的ε-邻域中,且x(i)是核心对象,则称x(j)由x(i)密度直达。密度直达关系通常不满足对称性,除非x(j)也是核心对象。
(5)密度可达(density-reachable):对x(i)与x(j),若存在样本序列p1,p2,...,pn,其中p1=x(i),pn=x(j),p1,p2,...,pn-1均为核心对象且pi+1从pi密度直达,则称x(j)由x(i)密度可达。密度可达关系满足直递性,但不满足对称性。
(6)密度相连(density-connected):对x(i)与x(j),若存在x(k)使得x(i)与x(j)均由x(k)密度可达,则称x(i)与x(j)密度相连。密度相连关系满足对称性。
(7)基于密度的簇:由密度可达关系导出的最大的密度相连样本集合C,簇C满足以下两个性质:
连接性(connectivity):x(i)∈C,x(j)∈C → x(i)与x(j)密度相连;
最大性(maximality):x(i)∈C,x(j)由x(i)密度可达 → x(j)∈C。
2、DBSCAN算法原理与流程
DBSCAN算法先任选数据集中的一个核心对象作为种子,创建一个簇并找出它所有的核心对象,寻找合并核心对象密度可达的对象,直到所有核心对象均被访问过为止。
DBSCAN的簇中可以少包含一个核心对象:如果只有一个核心对象,则其他非核心对象都落在核心对象的ε-邻域内;如果有多个核心对象,则任意一个核心对象的ε-邻域内至少有一个其他核心对象,否则这两个核心对象无法密度可达;包含过少对象的簇可以被认为是噪音。

3、DBSCAN算法的优缺点
优点:
不需要事先给定簇的数目k;
适于稠密的非凸数据集,可以发现任意形状的簇;
可以在聚类时发现噪音点、对数据集中的异常点不敏感;
对样本输入顺序不敏感。
缺点:
对于高维数据效果不好;
不适于数据集中样本密度差异很小的情况;
调参复杂,给定eps选择过大的MinPts会导致核心对象数量减少,使得一些包含对象较少的自然簇被丢弃;
选择过小的MinPts会导致大量对象被标记为核心对象,从而将噪声归入簇;
给定MinPts选择过小的eps会导致大量的对象被误标为噪声,一个自然簇被误拆为多个簇;
选择过大的eps则可能有很多噪声被归入簇,而本应分离的若干自然簇也被合并为一个簇;
数据量很大时算法收敛的时间较长,可对搜索最近邻时建立的KD-tree或Ball-tree进行规模限制。
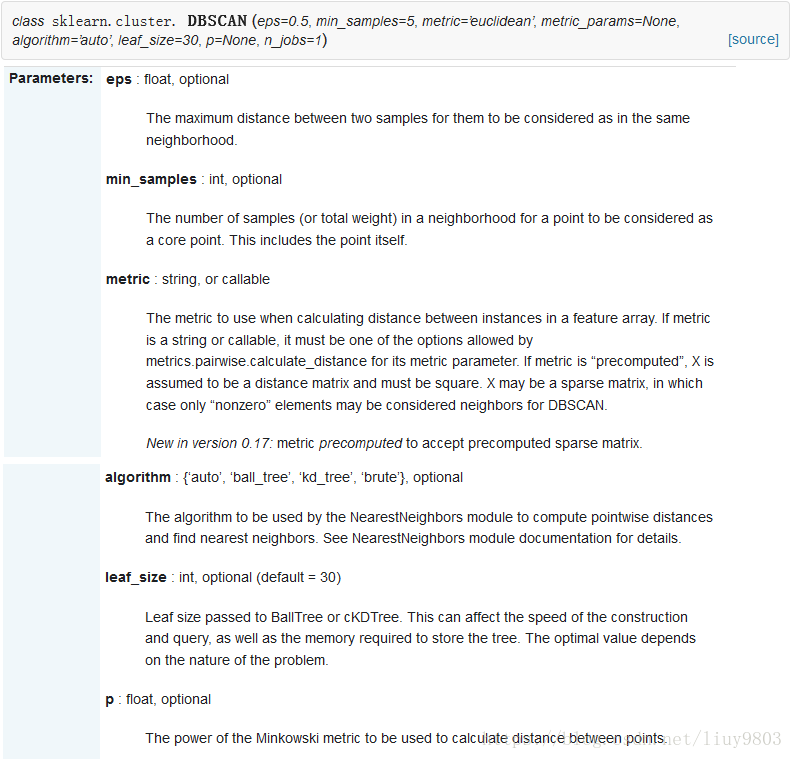
4、DBSCAN算法的scikit-learn API
二、密度最大值聚类算法(MDCA)
参考https://wenku.baidu.com/view/8c2abb00b52acfc789ebc9e8.html?qq-pf-to=pcqq.c2c
MDCA(Maximum Density Clustering Algorithm)算法将基于密度的思想引入到划分聚类中,使用密度而不是初始质心作为考察簇归属情况的依据,能够自动确定簇数量并发现任意形状的簇。MDCA一般不保留噪声,因此也避免了由于阈值选择不当而造成大量对象丢弃情况。
MDCA算法的基本思路是寻找最高密度的对象和它所在的稠密区域,在原理上MDCA和密度的定义无关,采用任意一种密度定义公式均可,一般采用DBSCAN算法中的密度定义方式。
1、基本概念:
给定数据集D,density(p) 表示对象p的密度,
(1)最大密度点:
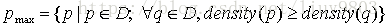
(2)密度阈值density0:
当对象的密度值大于密度阈值时,认为该对象属于一个比较固定的簇。在第一次构建基本簇的时候,就将这些对象添加到对应的簇中,如果小于阈值的时候,暂时认为该对象为噪声。
(3)Spmax序列的对象密度曲线:
根据所有对象与pmax的欧式距离对数据集重新排序
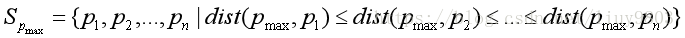

图像横轴为对象与pmax的欧式距离,纵轴为该对象所处位置的密度。
第一个波谷表明左侧的对象与pmax距离较近、处在同一个基本簇内,波谷的密度较低;
波谷右侧的密度又开始升高,说明对象属于其他的簇。
从数据集中移除已经划归为第一个基本簇的所有对象,从剩余对象中再次计算最大密度点并绘制对象密度曲线(b)。
(4)簇间距离阈值dist0:
对于两个基本簇Ci和Cj,采用二者最近两个成员之间的邻近度作为簇间距离
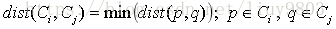
当两个基本簇的簇间距离小于给定阈值的时候,合并这两个基本簇。
(5)M值:基本簇中最多样本总数。
2、算法步骤:
(1)将数据集划分为基本簇
对数据集选取最大密度点pmax,按照距离排序得到Spmax;
对序列前M个样本数据进行判断,如果对象密度大于等于density0,那么将当前对象添加到基本簇Ci中;
从数据集中删除Ci中包含的所有对象,处理余下的数据集,选择最大密度点pmax’,并构建基本簇Ci+1;
循环操作直到数据集剩余对象的密度均小于density0。
(2)使用凝聚层次聚类的思想,合并较近的基本簇,得到最终的簇划分
在所有簇中选择距离最近的两个簇进行合并;
合并要求是:簇间距小于等于dist0;
如果所有簇中没有簇间距小于dist0的时候,结束合并操作。
(3)处理剩余点
如果保留噪声:则扫描所有剩余对象,将其中与某些簇距离小于或等于dist0的对象归入相应的最近的簇;
与任何簇的距离都大于的dist0的对象视为噪声。
如果不保留噪声:则把每个剩余对象划给最近的簇。