聚类算法
任务:将数据集中的样本划分成若干个通常不相交的子集,对特征空间的一种划分。
性能度量:类内相似度高,类间相似度低。两大类:1.有参考标签,外部指标;2.无参照,内部指标。
距离计算:非负性,同一性(与自身距离为0),对称性,直递性(三角不等式)。包括欧式距离(二范数),曼哈顿距离(一范数)等等。
1、KNN
k近邻(KNN)是一种基本分类与回归方法。
其思路如下:给一个训练数据集和一个新的实例,在训练数据集中找出与这个新实例最近的k 个训练实例,然后统计最近的k 个训练实例中所属类别计数最多的那个类,就是新实例的类。其流程如下所示:
- 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
- 对上面所有的距离值进行排序;
- 选前k 个最小距离的样本;
- 根据这k 个样本的标签进行投票,得到最后的分类类别;
KNN的特殊情况是k =1 的情况,称为最近邻算法。对输入的实例点(特征向量)x ,最近邻法将训练数据集中与x 最近邻点的类作为其类别。
(1)一般k 会取一个较小的值,然后用过交叉验证来确定;
(2)距离度量:一般是欧式距离(二范数),或者曼哈顿距离(一范数)
(3)回归问题:取K个最近样本的平均,或者使用加权平均。
算法的优点:(1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;(2)可用于非线性分类;(3)训练时间复杂度为O(n);(4)准确度高,对数据没有假设,对outlier不敏感。
缺点:计算量大;样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);需要大量的内存;
需要考虑问题:(1)KNN的计算成本很高;(2)所有特征应该标准化数量级,否则数量级大的特征在计算距离上会有偏移;(3)在进行KNN前预处理数据,例如去除异常值,噪音等。
KD树是一个二叉树,表示对K维空间的一个划分,可以进行快速检索(那KNN计算的时候不需要对全样本进行距离的计算了)。KD树更加适用于实例数量远大于空间维度的KNN搜索,如果实例的空间维度与实例个数差不多时,它的效率基于等于线性扫描。
2、K-Means
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。
基本思想:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
算法步骤:1.随机选择k个样本作为初始均值向量;2.计算样本到各均值向量的距离,把它划到距离最小的簇;3.计算新的均值向量;4.迭代,直至均值向量未更新或到达最大次数。
时间复杂度:O(tkmn),其中,t为迭代次数,k为簇的数目,m为记录数,n为维数;
空间复杂度:O((m+k)n),其中,k为簇的数目,m为记录数,n为维数。
优点:原理比较简单,实现也是很容易,收敛速度快;聚类效果较优;算法的可解释度比较强;主要需要调参的参数仅仅是簇数k。
缺点:需要输入k,一般通过交叉验证确定;算法速度依赖于初始化的好坏,初始质点距离不能太近;如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳;对于不是凸的数据集比较难收敛;对噪音和异常点比较的敏感。
3、 层次聚类
步骤:1.先将数据集中的每个样本看作一个初始聚类簇;2.找到距离最近的两个聚类簇进行合并。
优点:无需目标函数,没有局部极小问题或是选择初始点的问题。缺点:计算代价大。
4、密度聚类
DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。找到几个由密度可达关系导出的最大的密度相连样本集合。即为我们最终聚类的一个类别,或者说一个簇。
基本思想:它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
步骤:1、找到任意一个核心点,对该核心点进行扩充;2、扩充方法是寻找从该核心点出发的所有密度相连的数据点;3、遍历该核心的邻域内所有核心点,寻找与这些数据点密度相连的点。
优点:不需要确定要划分的聚类个数,聚类结果没有偏倚;抗噪声,在聚类的同时发现异常点,对数据集中的异常点不敏感;处理任意形状和大小的簇,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
缺点:数据量大时内存消耗大,相比K-Means参数多一些;样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合;
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
面试问题:
1、K-Means与KNN区别
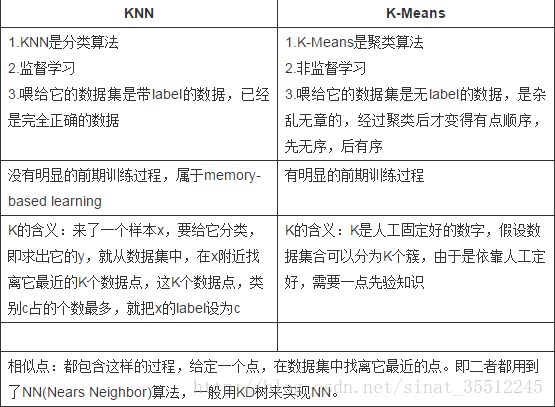
2、Kmeans的k值如何确定?
(1)枚举,由于kmeans一般作为数据预处理,所以k一般不会设置很大,可以通过枚举,令k从2到一个固定的值,计算当前k的所有样本的平均轮廓系数,最后选择轮廓系数最接近于1对应的k作为最终的集群数目;(2)数据先验知识,或者对数据进行简单的分析或可视化得到。
3、初始点选择方法?
初始的聚类中心之间相互距离尽可能远。(1)kmeans++,随机选择一个,对每一个样本计算到他的距离,距离越大的被选中聚类中心的概率也就越大,重复。(2)选用层次聚类进行出初始聚类,然后从k个类别中分别随机选取k个点。
4、kmeans不能处理哪种数据?
(1)非凸(non-convex)数据。可以用kernal k均值聚类解决。
(2)非数值型数据。Kmeans只能处理数值型数据。可以用k-modes。初始化k个聚类中心,计算样本之间相似性是根据两个样本之间所有属性,如属性不同则距离加1,相同则不加,所以距离越大,样本的不相关性越大。更新聚类中心,使用一个类中每个属性出现频率最大的那个属性值作为本类的聚类中心。
(3)噪声和离群值的数据。可以用kmedoids。
(4)不规则形状(有些部分密度很大,有些很小),可以用密度聚类DBSCAN解决。
5、kmeans如何处理大数据,几十亿?
并行计算。MapReduce,假设有H个Mapper,把数据集分为H个子集,分布到H个Mapper上,初始化聚类中心,并同时广播到H个Mapper上。
参考资料:http://www.cnblogs.com/pinard/p/6164214.html
http://www.cnblogs.com/pinard/p/6208966.html
https://blog.csdn.net/sinat_35512245/article/details/55051306