MVS重建:根据输出表示,MVS方法可以分为
1)直接点云重建:基于点云的方法直接对三维点进行操作,通常依靠传播策略逐步强化重构。由于点云的传播是顺序进行的,这些方法很难完全并行化,通常需要较长的处理时间。
2)体积重建:基于体积的方法将三维空间划分为规则网格,然后估计每个体素是否附着在表面上。这种表示的缺点是空间离散化误差和高内存消耗。
3)深度图重建:深度映射是其中最灵活的表示方式。它将复杂的MVS问题解耦为每个视图深度地图估计的小问题,每次只关注一个参考图像和几个源图像。此外,深度地图可以很容易地融合到点云或体积重建。目前最好的MVS算法都是基于深度映射的方法。
论文简介:
一个端到端的深度学习架构,用于从多视图图像进行深度映射推断。在该网络中,首先提取深度视觉图像特征,然后通过可微分单应性翘曲在参考摄像机截锥上建立三维代价体。
MVSNet:MVSNet是一种监督学习的方法,以一个参考影像和多张原始影像为输入,而得到参考影像深度图的一种端到端的深度学习框架。网络首先提取图像的深度特征,然后通过可微分投影变换构造3D的代价体,再通过正则化输出一个3D的概率体,再通过soft argMin层,沿深度方向求取深度期望,获得参考影像的深度图。

步骤:深度特征提取,构造匹配代价,代价累计,深度估计,深度图优化。
1、深度特征提取:深度特征指通过神经网络提取的影像特征,相比传统SIFT、SURF的特征有更好的匹配精度和效率。经过视角选择之后,输入已经配对的N张影像,即参考影像和候选集。首先利用一个八层的二维卷积神经网络提取立体像对的深度特征 Fi,输出32通道的特征图.
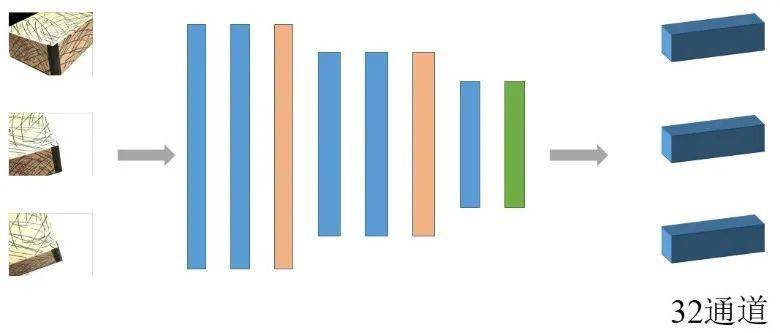
2、构造匹配代价:为防止输入的像片被降采样后语义信息的丢失,像素的临近像素之间的语义信息已经被编码到这个32通道的特征中,并且各个图像提取过程的网络是权值共享的。
3、代价累计:MVSNet的代价累积通过构造代价体实现的。代价体是一个由长、宽与参考影像长宽一样的代价图在深度方向连接而成的三维结构,在深度维度,每一个单位表示一个深度值。其中,某一深度的代价图上面的像素表示参考影像同样的像素在相同深度处,与候选集影像的匹配代价。
计算概率图来测量深度估计质量。在我实验中,将概率小于0.8的像素作为异常值。几何约束度量多个视图之间的深度一致性。与立体图像的左右视差检查类似,通过深度d1将参考像素p1投影到另一个视图中的像素pi1,然后通过pi的深度估计di将pi重新投影回参考图像。
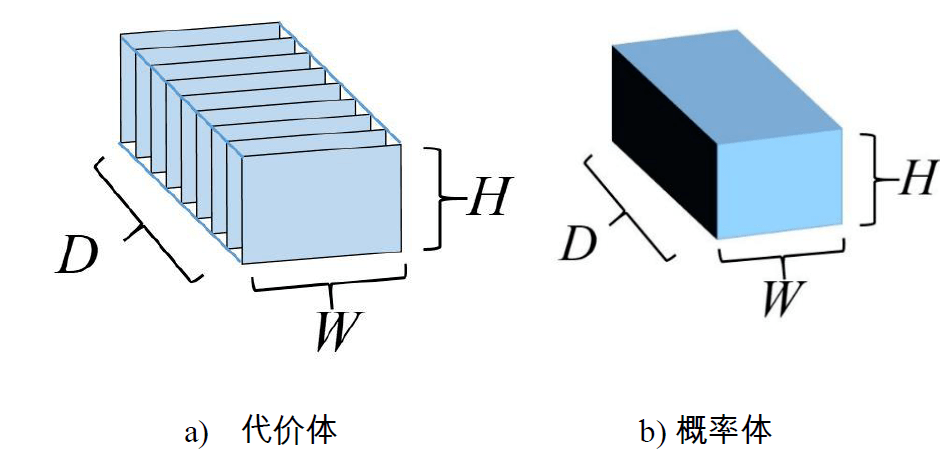
4、深度估计:MVSNet的深度估计是通过神经网络直接学习的。网络训练方法是,输入代价体V和对应深度图真值,利用SoftMax回归每一个像素在深度θ处的概率,得到一个表示参考影像每个影像沿深度方向置信度的概率体P,以此完成从代价到深度值的学习过程。
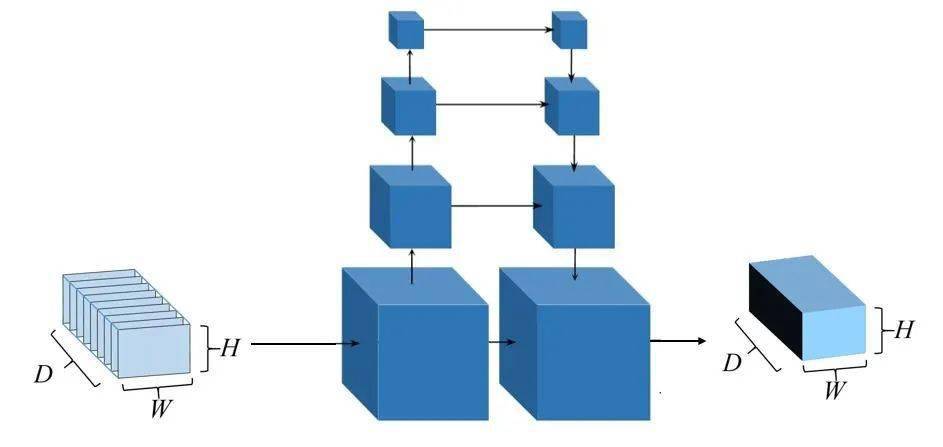
5、深度图优化:原始代价体往往是含有噪声污染的,因此,为防止噪声使得网络过度拟合,MVSNet中使用基于多尺度的三维卷积神经网络进行代价体正则化,利用U-Net网络,对代价体进行降采样,并提取不同尺度中的上下文信息和临近像素信息,对代价体进行过滤。
其他
DTU数据集:DTU数据集是一个包含100多个不同光照条件的场景的大型MVS数据集。

深度图:

cost volume:cost-volume在计算机视觉中特指计算机视觉中的立体匹配stereo matching问题中的一种左右视差搜索空间(详见:https://www.zhihu.com/question/297481800)