
论文链接:Deep High-Resolution Representation Learning for Visual Recognition
时间:2019.08 TPAMI2019
作者团队:Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, Bin Xiao
分类:计算机视觉–人体关键点检测–2D top-down
目录:
1.HRNetv2背景
2.HRNetv2姿态识别
3.HRNetv2网络架构图
4.引用
1.主要在于学习记录,如有侵权,私聊我修改
2.水平有限,不足之处感谢指出
1.HRNetv2背景
基于深度学习的特征表示在计算机视觉任务中通常分为两类:低分辨率表示(low-resolution representations)和高分辨率表示(high-resolution representations)。
目前有两种主要的方法来获取高分辨率表示:
- 从网络输出的低分辨率表示或者中间中等分辨率表示恢复高分辨率表示,从down-sampling后获取的feature map中再upsample来获得高分辨表示,如Hourglass,SegNet,DeconvNet,U-Net,encoder- decoder等。
- 通过高分辨率卷积保持高分辨率表示,并通过并行低分辨率卷积加强表示。
在高分辨率卷积保持高分辨率表示的同时,需要设计高低分辨率融合,主要思路有:
(a)对称结构,先下采样再上采样,上下采样过程对称,如U-Net、Hourglass。
(b)级联金字塔,高低分辨率融合时经过卷积处理,如refinenet等。
(c)简单的baseline,用转置卷积进行上采样。
(d)扩张卷积,增大感受野,减少下采样次数,无需跳层连接直接上采样,如deeplab等。
HRNet V1在(b)的基础上改进,保持大的分辨率表示。然而HRNet V1仅是用在姿态估计领域的,HRNet V2在HRNetV2上进行很小的改进使其适用于更广的视觉任务。
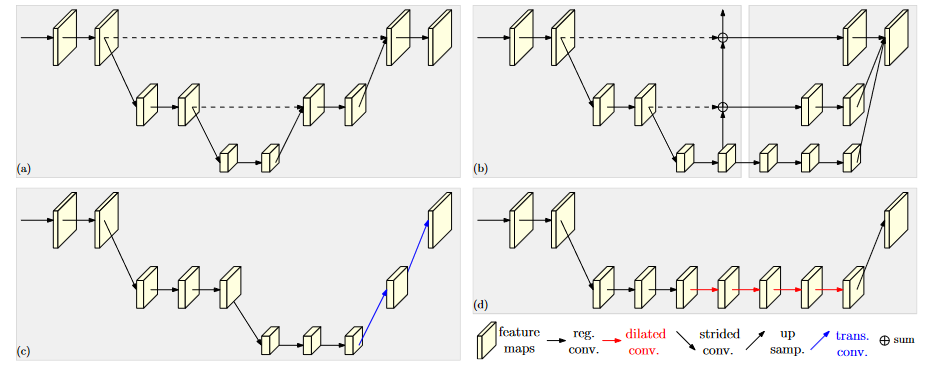
在HRNetV1中通过并行连接高分辨率卷积,在并行卷积中重复进行多尺度融合来维持高分辨率表示。HRNetV1的介绍见:HRNetV1
此篇论文中提出的HRNetv2通过简单修改HRNetV1的模型结构得到更强的高分辨表示,HRNetv2在整个网络过程中保持高分辨率,通过维持一个多分辨率的并行,同时在并行中交换不同分辨率的信息,得到的特征在语义上更加丰富,在空间上更加精准。
2.HRNetv2姿态识别
-
网络结构部分
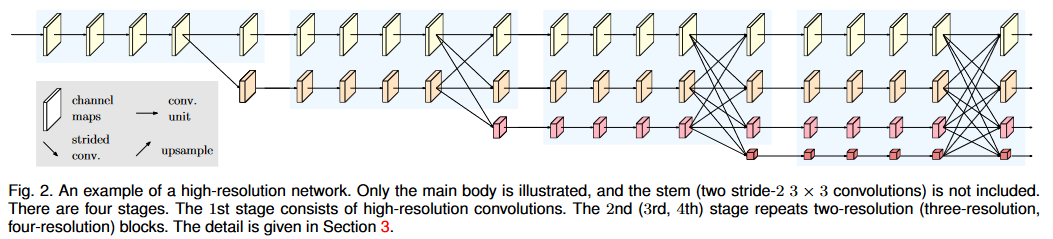
首先图像的输入经过下采样四倍的feature map,横向的conv block指的是残差单元,不同分辨率之间的多交叉线部分是多分辨率组卷积(multi-resolution convolution)。至此HRNet V2和HRNet V1基本一致的。
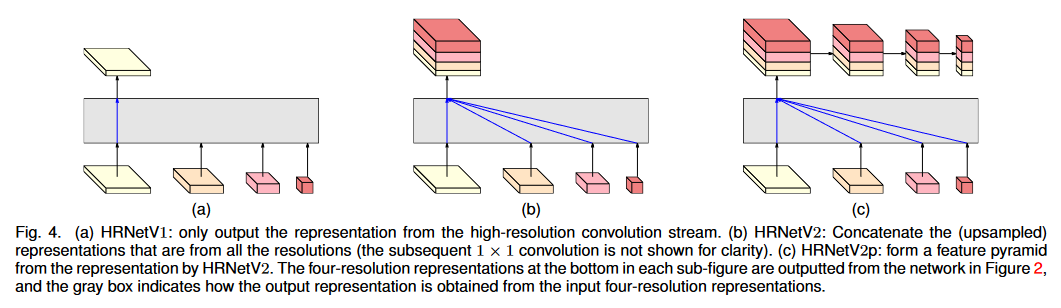
主要区别在网络上加的head:
(a)是只用大分辨率的特征图的HRNet V1,仅输出高分辨率支路中的特征图,而忽略其他三个支路特征图。
(b)HRNet V2将不同分辨率支路的特征图通过 concat 方式进行拼接作为输出,用于语义分割。
(c)在 HRNetV2 的高分辨率表示的基础上通过降采样到多个级别来构建多级特征图,用于目标检测。
用于分类的head
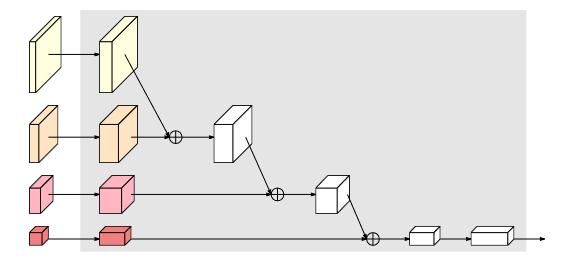
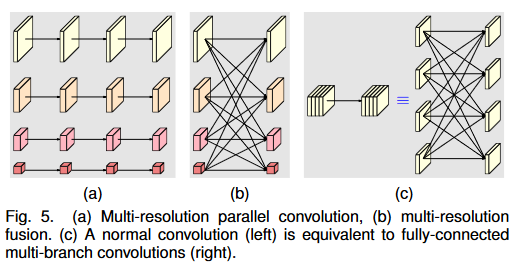
多分辨率并行卷积和多分辨率融合模块
多分辨率并行卷积类似于组卷积(a) 。将输入通道分为通道的几个子集,并分别对不同空间分辨率的每个子集进行卷积操作。但是多分辨率并行卷积的不同子集间的分辨率是不同的,而组卷积的不同子集间的分辨率是相同的。
多分辨率融合模块的输入通道与输出通道分为几个子集,输入和输出子集以完全连接的方式连接,并且每个连接都是普通卷积。输出通道的每个子集都是输入通道的每个子集上的卷积输出的总和,因此HRNetv2融合更多的空间信息。
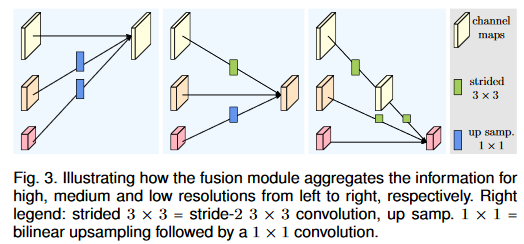
对于多分辨率融合包含上采样,平级,下采样。其中下采样包括跨一层和多层下采样。上采样使用插值法,平级使用卷积,如果支路大于 2,使用多个 stride>1 的卷积进行下采样操作。
总之,在多分辨率卷积中,每个通道的分辨率都不一样。
其次,通道间的连接如果是降分辨率,则用的是3x3的stride=2的卷积,如果是升分辨率,用的是双线性最邻近插值上采样。 -
结果评估
人体姿态估计
HRNetV1 和 HRNetV2 的结果差不多且 HRNetV1 的计算复杂度更低,因此在该实验中使用 HRNetV1 作为选用的模型。训练和测试数据集均使用 COCO 数据集。
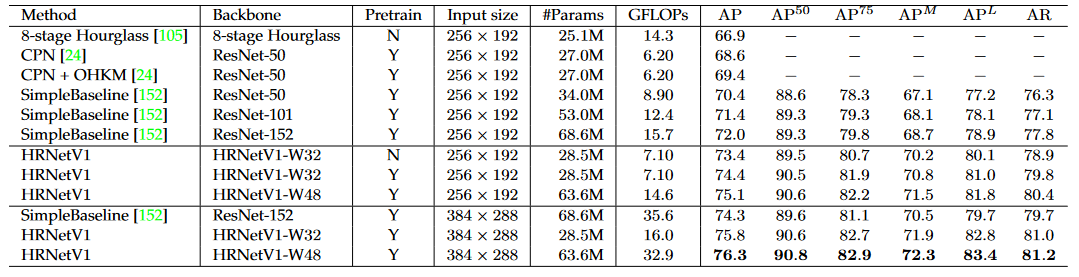
在 COCO test-dev 数据集上,HRNetV1 和现有最方法进行比较,在精度、Params和GFLOP方面有更大的提升。
在语义分割和目标检测的结果评估不作探究。
消融实验
1.不同分辨率的特征图
训练两个 HRNetV1 网络,HRNetV1-W32 进行人体姿势估计,使用 HRNetV2-W48 进行语义分割。网络输出从高到低分辨率的四个特征图,最低分辨率特征图上的热图预测质量太低进而不展示,结果展示其他三个特征图的 AP 分数。
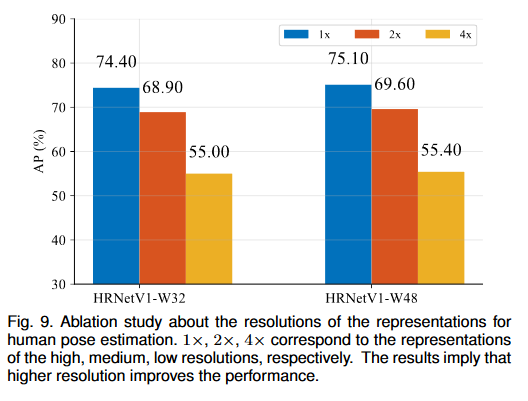
2.重复多分辨率融合
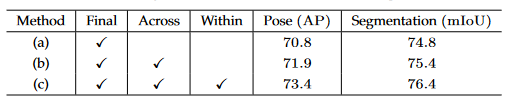
(a)无中间融合模块,只有最终融合模块。
(b)跨阶段融合单元,每个阶段内的相同分辨率支路之间没有融合。
(c)跨阶段阶段和最终融合模块。
3.对最后的低分辨率特征图与高分辨率特征图融合做对比试验,表明 HRNetV2 的低分辨率并行卷积的聚合表示能提高准确度。
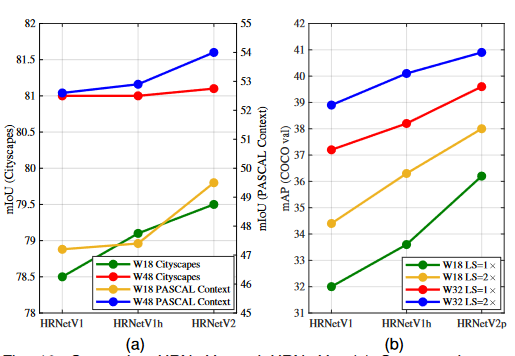
3.HRNetv2网络架构图
