论文下载地址:https://arxiv.org/abs/1902.09212
官方源码地址:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1bB4y1y7qP
HRNet团队工作小结_Patricia_daye的博客-CSDN博客
代码分析解读:PRTR论文代码解读_不学污术的小Z的博客-CSDN博客
摘要
本文:
本文关注人体姿态估计问题,重点是学习可靠的高分辨率表征。现有的大多数方法都是从由高到低分辨率网络产生的低分辨率表征中恢复高分辨率表征。相反本文提出的网络在整个过程中保持高分辨率表征:
(1)从一个高分辨率的子网开始,作为第一阶段,将高分辨率到低分辨率的子网逐个添加,形成更多的阶段,并将多分辨率的子网并行连接。
(2)执行重复的多尺度融合,这样每一个高到低分辨率的表征都能从其它平行表征中反复接收信息,从而得到丰富的高分辨率表征。因此,预测的关键点热图可能更准确、空间上更精确。
实验:
(1)通过两个基准数据集(COCO关键点检测数据集和MPII人体姿态数据集)上优越的姿态估计结果,证明了本文网络的有效性。
(2)网络在PoseTrack数据集的姿态跟踪方面也有优越性。
1 介绍
二维人体姿态估计:
一直是计算机视觉中一个重要而又具有挑战性的问题,目标是定位人体解剖关键点(如肘部,手腕等)或部分。它有许多应用,包括人体动作识别、人机交互、动画等。本文关注单人姿态估计,它是其他相关问题的基础,如多人姿态估计、视频姿态估计和跟踪等。
深度卷积神经网络:
最近的发展表明,深度卷积神经网络已经达到了最先进的性能。现有的大多数方法都是将输入通过一个网络,这个网络通常由一系列高分辨率到低分辨率的子网连接而成,然后提高分辨率——如 Hourglass通过一个对称的低到高的过程恢复高分辨率;SimpleBaseline采用几个转置的卷积层来生成高分辨率表征;某些工作,使用膨胀卷积放大高分辨率到低分辨率网络的后几层。
高分辨率网络(HRNet):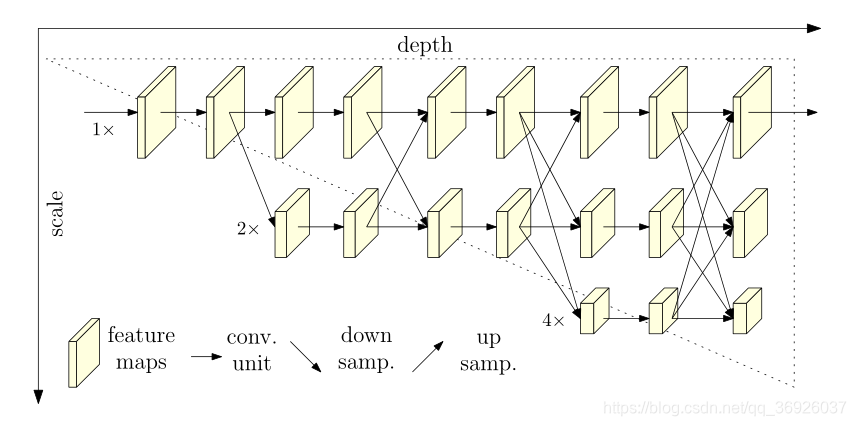
(图1:HRNet的架构。它由并行的高—低分辨率子网组成,并在多分辨率子网之间进行重复的信息交换(多尺度融合)。水平方向和垂直方向分别对应网络的深度和特征图的尺度)(斜向下为下采样,斜向上为上采样)
本文提出了一种新的结构——高分辨率网络(HRNet),能够在整个过程中保持高分辨率表征。第一阶段从一个高分辨率子网开始,逐步增加高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率子网并行连接。在整个融合过程中,通过在并行多分辨率子网中反复交换信息来进行重复的多尺度融合。(如图1)通过网络输出的高分辨率表征来估计关键点
HRNet网络优势:
(1)本文方法以并行方式连接高到低分辨率子网,而不是像现有大多数解决方案那样以串行方式连接。因此HRNet能够保持高分辨率,而不是通过从低分辨率到高分辨率的过程恢复分辨率,因此预测的热图在空间上更精确——parallel high-to-low resolution subnetworks
(2)现有的大多数融合方案都将低级和高级表征进行聚合。相反,HRNet通过在相同深度和相似级别的低分辨率表征的帮助下,重复进行多尺度融合来提升高分辨率的表征,反之亦然,这导致了高分辨率的表征也可以用于姿态估计。结果预测的热图更准确——multi-resolution subnetworks
实验结果:
(1)该算法的关键点检测性能优于两个基准数据集:COCO关键点检测数据集和MPII人体姿态数据集。
(2)在PoseTrack数据集上展示了我们的网络在视频姿态跟踪方面的优越性。
2 相关工作
2.1 单人姿态估计:
(1)传统
单人姿态估计的传统解决方案采用概率图模型或图结构模型。
(2)基于深度学习:
最近通过利用深度学习更好地建模unary (一元)和 pair-wise (成对)energies 或模仿迭代推理过程改进了传统模型。现在深度卷积神经网络提供了主要的解决方案,主要有两种方法:
①回归关键点位置
②估计关键点热图,然后选择热值最高的位置作为关键点。
大多数用于关键热图估计的卷积神经网络都包含:
1)一个茎(stem)子网络。与分类网络相似,降低分辨率);
2)一个主体(body)。产生与输入有相同分辨率的表征);
3)回归器。估计热图(关键点位置),然后将关键点转换为全分辨率下的表示。
主体采用由高到低和由低到高的框架,并可能增加多尺度融合和中(深)监督。
2.2 分辨率由低到高和由高到低(High-to-low and low-to-high)
high-to-low process 目标是生成低分辨率和高分辨率的表征,而low-to-high process目标是生成高分辨率的表征。为了提高性能,这两个过程可能会重复多次。
代表性的网络设计模式包括:
(1)Symmetric high-to-low and low-to-high processes(对称的从高到低和从低到高的过程):沙漏网络(Hourglass)及其后续研究将从低到高的过程设计为从高到低的过程的镜像。
(2)Heavy high-to-low and light low-to-high(重从高到低和轻从低到高):由高到低的过程是基于ImageNet分类网络,由低到高的过程是简单的几个双线性上采样( bilinear-upsampling )或转置卷积层(transpose convolution layers)。
(3)Combination with dilated convolutions(结合膨胀卷积):为了消除空间分辨率的损失,在ResNet或VGGNet的最后两个阶段采用膨胀卷积(dilated convolution),之后通过一个 light low-to-high(轻量从低到高过程)来进一步提高分辨率,避免了仅使用膨胀卷积带来的昂贵的计算成本。
图2描述四个代表性的姿态估计网络。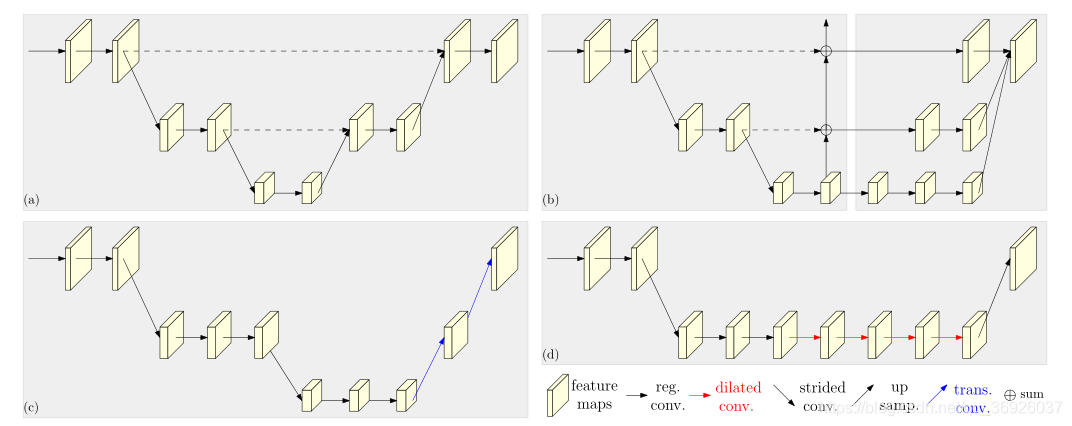
(图2: 基于由高到低和由低到高框架的代表性姿态估计网络的说明。(a)沙漏网络(b)级联金字塔网络( c ) SimpleBaseline:由低到高处理的转置卷积。(d)结合膨胀卷积。右下角标注说明:reg.常规卷积,dilated. 扩张卷积,trans. 转置卷积,strided. 跨步卷积,concat. 拼接。(a)中由高到低和由低到高过程是对称的。(b)、©和(d)中由高到低过程——分类网络(ResNet或VGGNet)的一部分,是重的,而低到高过程是轻的。在(a)和(b)中,由高到低和由低到高流程的相同分辨率层之间的跳跃连接(虚线)主要用于融合低级和高级特性。在(b)中,右边的部分结合了通过卷积处理的低级和高级特征)
2.3多尺度融合
(1)最直接的方法是将多分辨率的图像分别输入到多个网络中,并将输出响应图聚合在一起。
(2)沙漏网络及其扩展:通过跳跃连接,将由高到低流程中的低级特征逐步组合到由低到高流程中的同分辨率高级特征。
(3)级联金字塔网络:globalnet将从高到低过程中的从低到高分辨率特征逐步结合到由低到高的过程中,再由refinenet将通过卷积处理的从低到高的特征结合起来。
(4)HRNet:重复多尺度融合,部分受到深度融合及其扩展的启发。
2.4 中间的监督
中间监督或深度监督,早期为图像分类而开发,后来也用来帮助深度网络训练和提高热图估计质量。
沙漏方法和卷积姿态机器方法将中间热图处理为剩余子网络的输入或部分输入。
2.5 本文方法
HRNet网络以并行方式连接由高-低子网络;在整个处理过程中,保持高分辨率表征,以实现空间上精确的热图估计;通过反复融合由高-低子网产生的表征,产生可靠的高分辨率表征。本文方法不同于大多数现有工作(需要一个单独的从低到高的上采样过程,并聚合低级和高级表征),在不使用中间热图监督的情况下,具有较好的关键点检测精度、计算复杂度和较高的参数效率。
有相关的多尺度网络用于分类和分割,本文工作部分地受到了其中一些方法的启发(因为存在明显的差异,所以不适用于我们的问题):
1.卷积神经网络和互联CNN由于缺乏对每个子网络(深度、批处理归一化)和多尺度融合的合理设计,无法产生高质量的分割结果;
2.网格网络(grid network)是许多权重共享的 U-Net的组合,由两个独立的跨分辨率融合过程组成:第一阶段,信息只从高分辨率发送到低分辨率;第二阶段,信息只从低分辨率发送到高分辨率,因此竞争力较低。
3.多尺度密集网络(Multi-scale densenets):不针对也不能生成可靠的高分辨率表征。
3 方法
3.1人体姿态估计
(1)定义:又称关键点检测,旨在从尺寸为W × H × 3的图像 I 中检测出K个关键点或部件(如肘部、手腕等)的位置。最先进的方法将这一问题转化为估算K个大小为W’×H’的热图,既 {H1,H2,…,HK},其中每个热图Hk表示第k个关键点的位置置信度。
(2)方法:利用卷积网络来预测人体关键点。卷积网络由①一个包含两个降低分辨率的跨步卷积组成的茎(stem)(垂直方向),②一个输出与输入特征图分辨率相同的主体( body)(水平方向),③一个估计热图的回归器(regressor),其中关键点位置被选择和转换为全分辨率。
3.2 高分辨率网络(HRNet)
本文将重点放在主体(body)的设计上,并介绍我们的高分辨率网络(HRNet)(如图1)。
(图1:HRNet的架构。它由并行的高—低分辨率子网组成,并在多分辨率子网之间进行重复的信息交换(多尺度融合)。水平方向和垂直方向分别对应网络的深度和特征图的尺度)
3.2.1 连续多分辨率子网
现有的姿态估计网络是通过串联从高-低分辨率的子网络来建立的,每个子网络由一系列卷积组成形成一个阶段,在相邻的子网络上有一个下采样层将分辨率减半。
为第s阶段的子网,r为分辨率索引(分辨率为第一个子网分辨率的1/2r−1)。具有S阶段(如4)的高-低网络可以表示为:
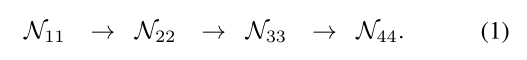
3.2.2 并行多分辨率子网
从一个高分辨率子网开始,作为第一阶段,逐步增加高分辨率到低分辨率的子网,形成新的阶段,并将多分辨率子网并行连接。因此,并行子网后一阶段的分辨率由前一阶段的分辨率和一个额外的较低的分辨率组成。
一个包含4个并行子网的网络结构示例如下:(Nsr,代其中s代表阶段,r代表分辨率索引)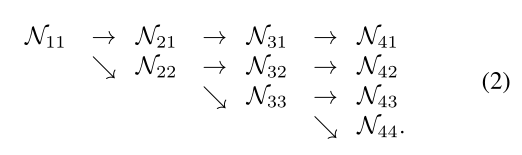
3.2.3 重复多尺度融合
引入跨并行子网的交换单元,使每个子网重复地从其他并行子网接收信息。 下面展示信息交换方案的例子,将第三阶段分为几个(如3个)交换块,每个交换块由3个并行卷积单元和一个跨并行单元的交换单元组成,具体如下: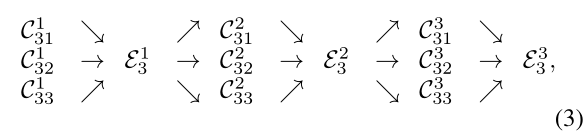
其中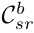 是s阶段b交换块的r分辨率的卷积单元,
是s阶段b交换块的r分辨率的卷积单元,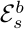 是对应的交换单元,如图3(为了方便去掉了下标s和上标b)。
是对应的交换单元,如图3(为了方便去掉了下标s和上标b)。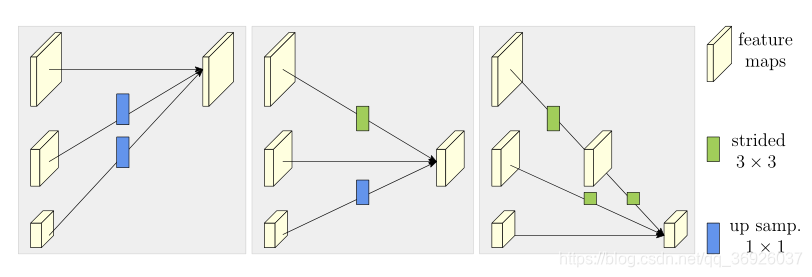
(图3: 交换单元如何从左到右为高分辨率、中分辨率和低分辨率聚合信息。strided 3×3=步长为3×3的卷积 =大步3×3卷积,up samp. 1× 1=最近邻采样后跟1X1卷积)
- 输入是s个响应映射:{X1,X2,…, Xs}。
- 输出是s响应映射:{Y1,Y2,…,Ys},其分辨率和宽度与输入相同。
- 每个输出是输入映射的聚合
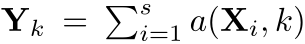
- 跨阶段的交换单元有一个额外的输出映射Ys+1:
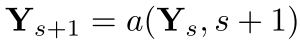
函数![]() 由分辨率i到分辨率k的上采样或下采样Xi组成:
由分辨率i到分辨率k的上采样或下采样Xi组成:
1)下采样,采用跨步3× 3卷积。(如一个stride 2的跨步3×3卷积用于2× 下采样,两个连续stride 2的跨步3×3卷积用于4×下采样);
2)上采样,采用最近邻采样,紧跟1 × 1卷积对齐通道数量。如果i = k, a(.,.)只是一个标识( identify)连接:a(Xi, k) = Xi。
3.2.4 热图估计
简单地从最后一个交换单元输出的高分辨率表征回归热图,这在经验上工作得很好。
损失函数定义为均方误差,用于比较预测的热图和GT热图。GT热图是以每个关键点的GT位置为中心,采用标准差为1的二维高斯函数生成。
3.3 HRNet网络实例化
遵循ResNet的设计规则,将深度分配到每个阶段,并将通道数量分配到每个分辨率,来实例化网络用于关键热图估计。
HRNet,由四个并行子网构成的四个阶段组成,子网分辨率逐渐降低到一半,相应的宽度(通道数)增加到两倍:
(1)第一阶段:包含4个残差单元,每个单元与ResNet-50一样,由一个宽度为64的瓶颈,紧随其后的是一个3×3卷积,将特征图的宽度减少到C;
(2)第2,3,4阶段:分别包含1、4、3个交换块。一个交换块包含4个残差单元,每个单元在每个分辨率中包含2个3 × 3卷积以及一个跨分辨率的交换单元。综上所述,总共有8个交换单元,即进行了8次多尺度融合。
实验中,研究了一个小网和一个大网:HRNet-W32和HRNet-W48,其中32和48分别代表高分辨率子网在最后三个阶段的宽度(C,通道数)。其他三个并行子网的宽度为64、128、 256(HRNet-W32), 96、192、384(HRNet-W48)。
3.4 HRNet网络结构
参见:HRNet网络简介_太阳花的小绿豆的博客-CSDN博客_hrnet网络
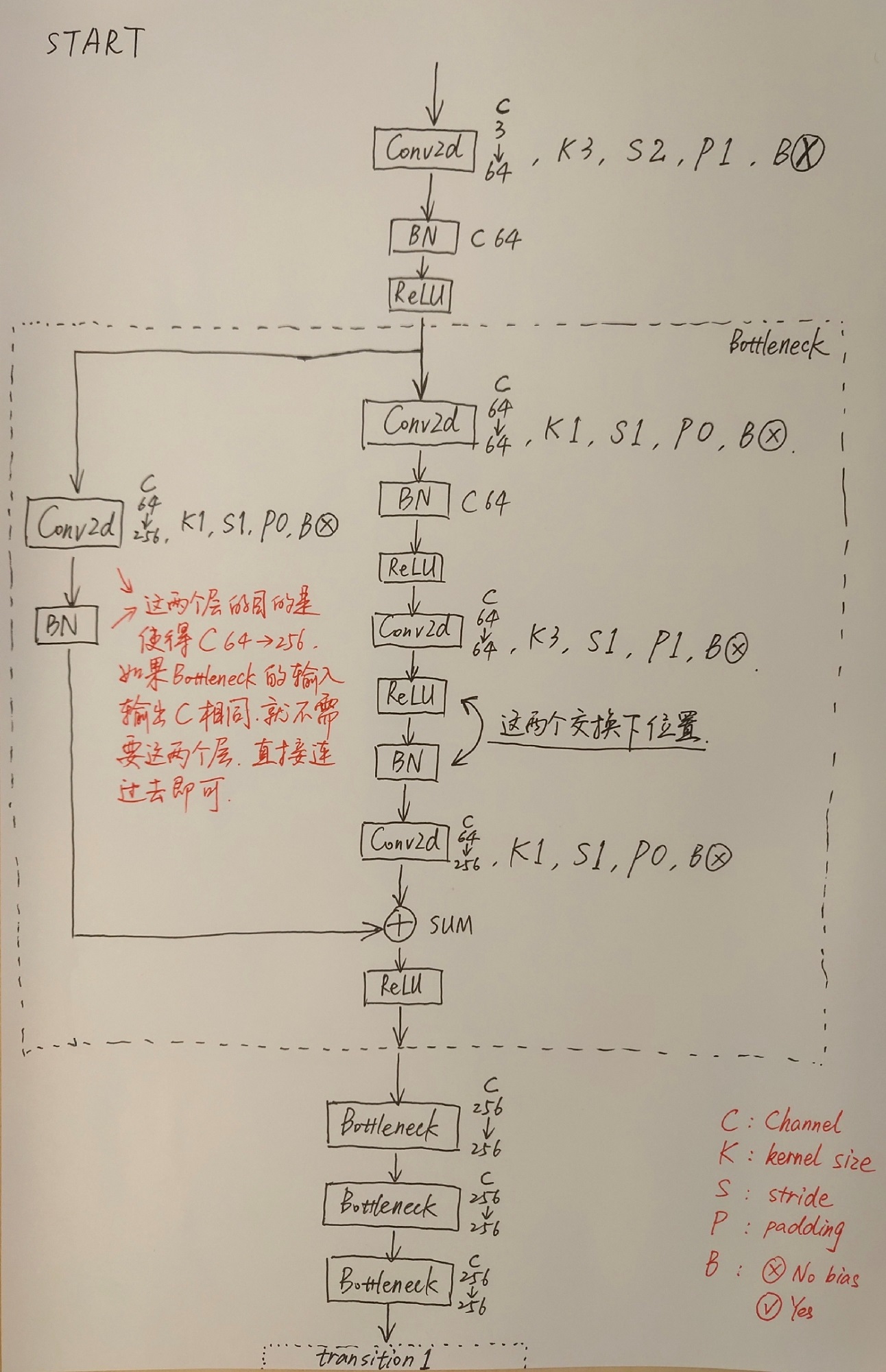
下图是根据阅读项目源码绘制的关于HRNet-W32的模型结构简图,在论文中除了提出HRNet-W32外还有一个HRNet-W48的版本,两者区别仅仅在每个模块所采用的通道个数不同,网络的整体结构都是一样的。而该论文的核心思想就是不断地去融合不同尺度上的信息,也就是论文中所说的Exchange Blocks。

通过上图可以看出,HRNet首先通过两个卷积核大小为3x3步距为2的卷积层(后面都跟有BN以及ReLU)共下采样了4倍。然后通过Layer1模块,这里的Layer1其实和之前讲的ResNet中的Layer1类似,就是重复堆叠Bottleneck,注意这里的Layer1只会调整通道个数,并不会改变特征层大小。下面是实现Layer1时所使用的代码。
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
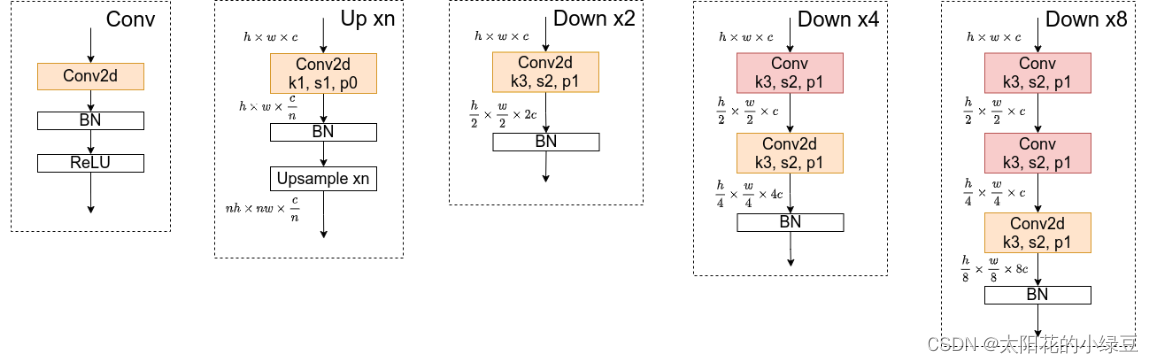
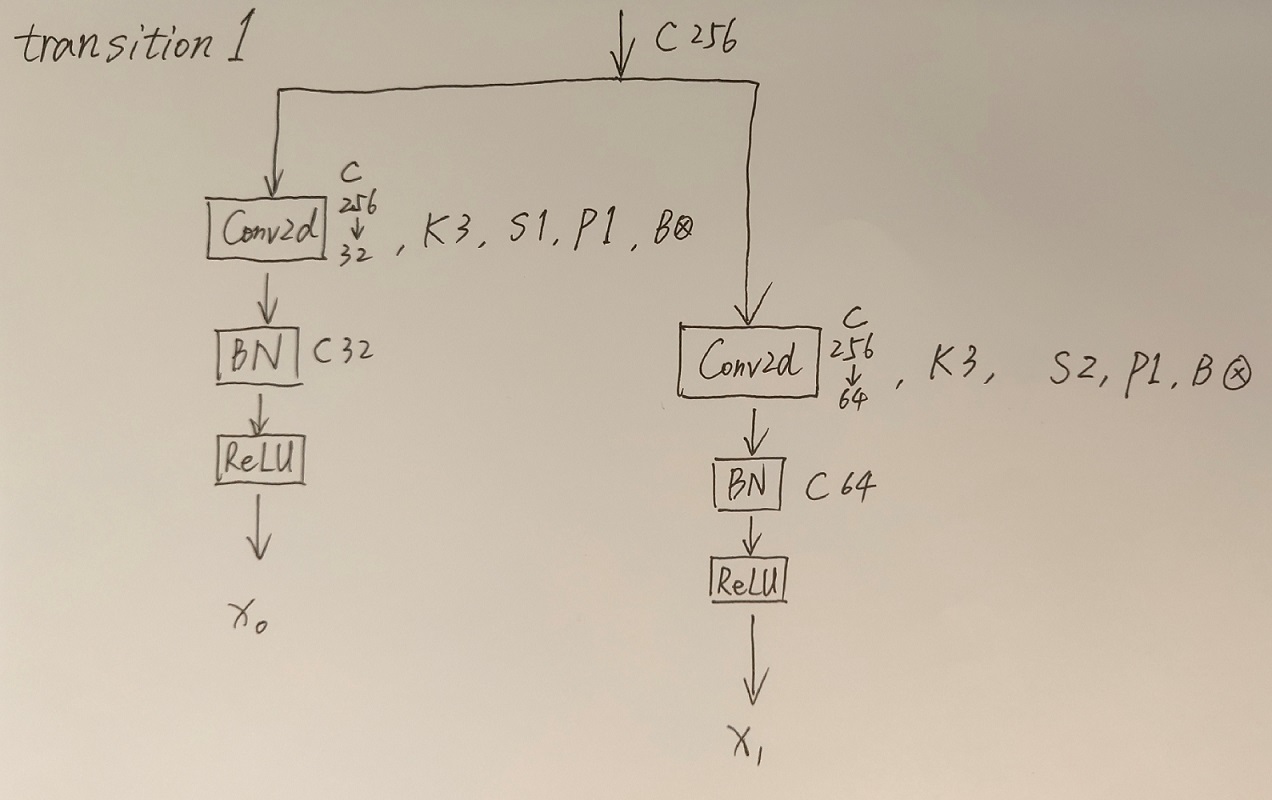
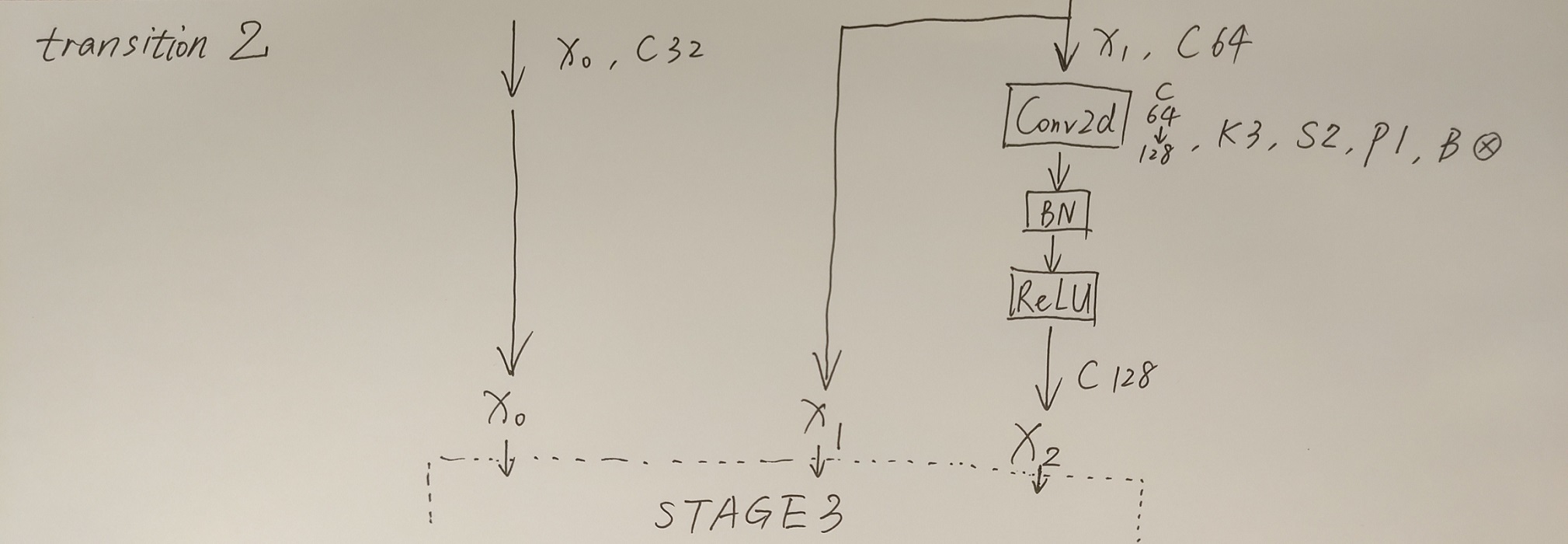
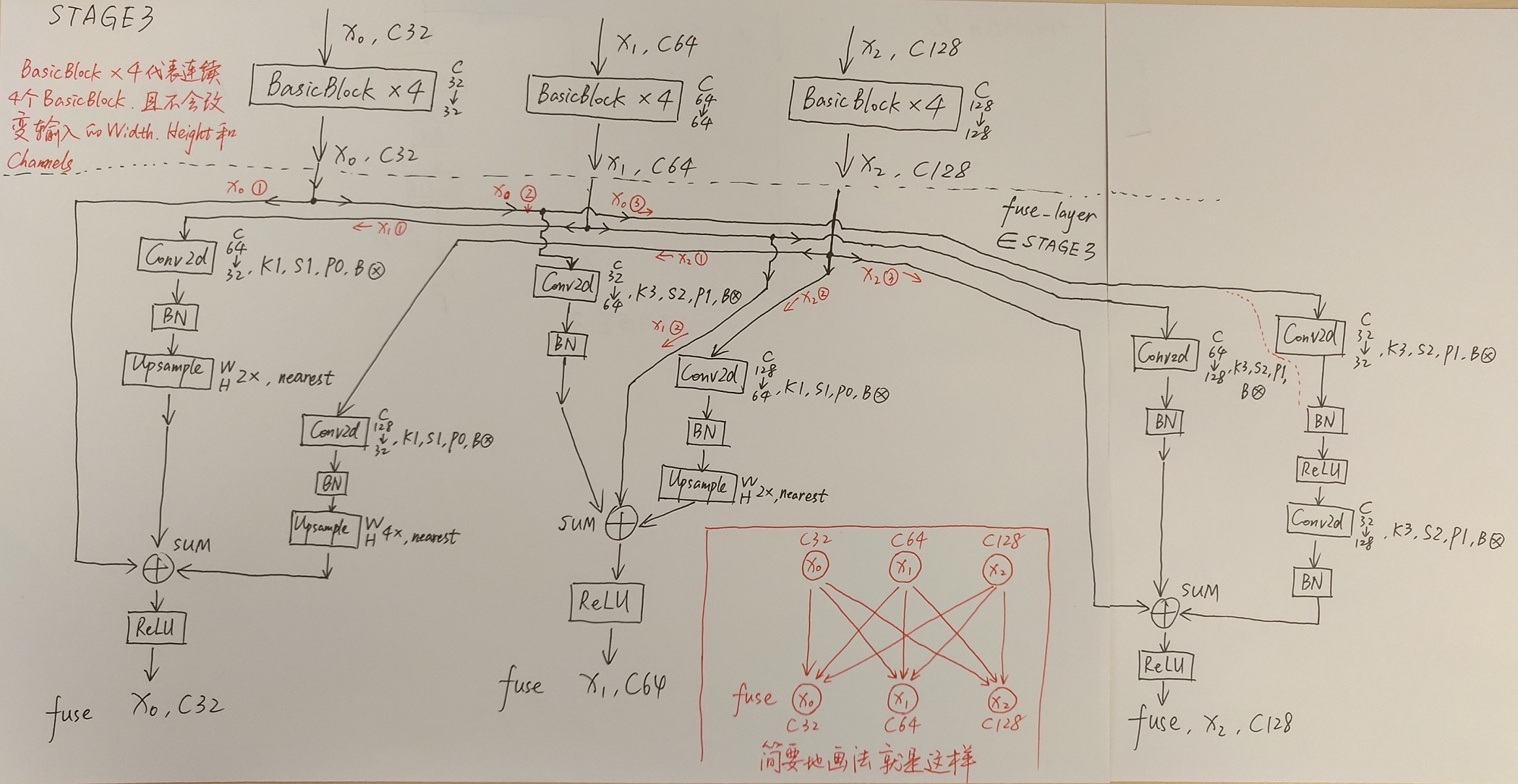
接着通过一系列Transition结构以及Stage结构,每通过一个Transition结构都会新增一个尺度分支。比如说Transition1,它在layer1的输出基础上通过并行两个卷积核大小为3x3的卷积层得到两个不同的尺度分支,即下采样4倍的尺度以及下采样8倍的尺度。在Transition2中在原来的两个尺度分支基础上再新加一个下采样16倍的尺度,注意这里是直接在下采样8倍的尺度基础上通过一个卷积核大小为3x3步距为2的卷积层得到下采样16倍的尺度。如果有阅读过原论文的小伙伴肯定会有些疑惑,因为在论文的图1中,给出的Transition2应该是通过融合不同尺度的特征层得到的(下图用红色矩形框框出的部分)。但根据源码的实现过程确实就和我上面图中画的一样,就一个3x3的卷积层没做不同尺度的融合,包括我看其他代码仓库实现的HRNet都是如此。大家也可以自己看看源码对比一下。

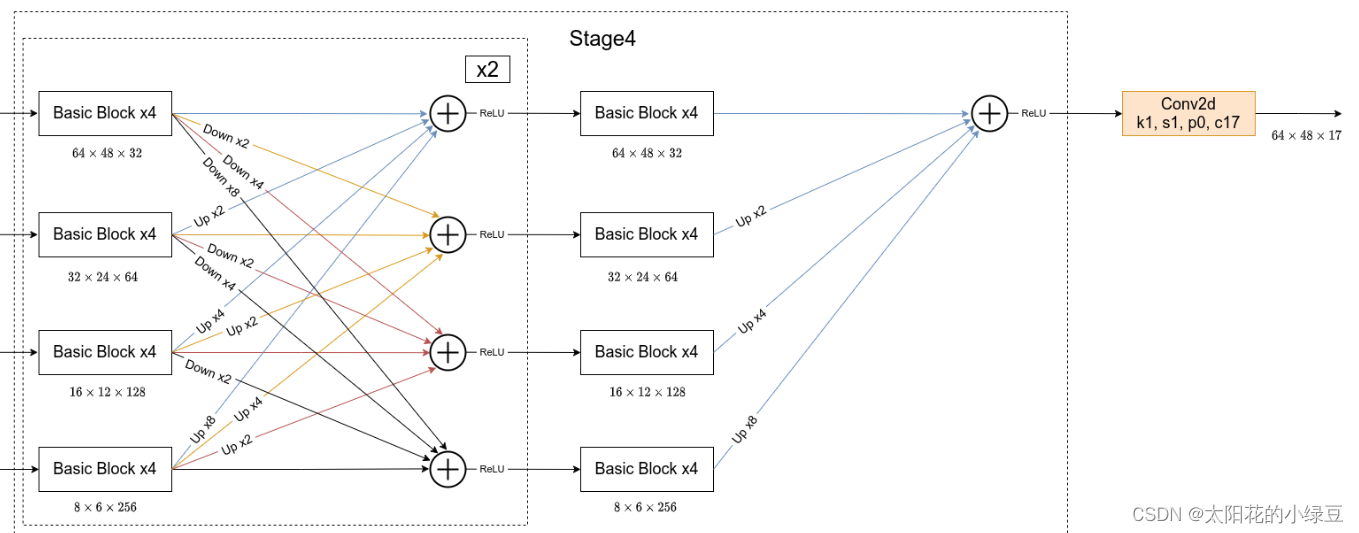
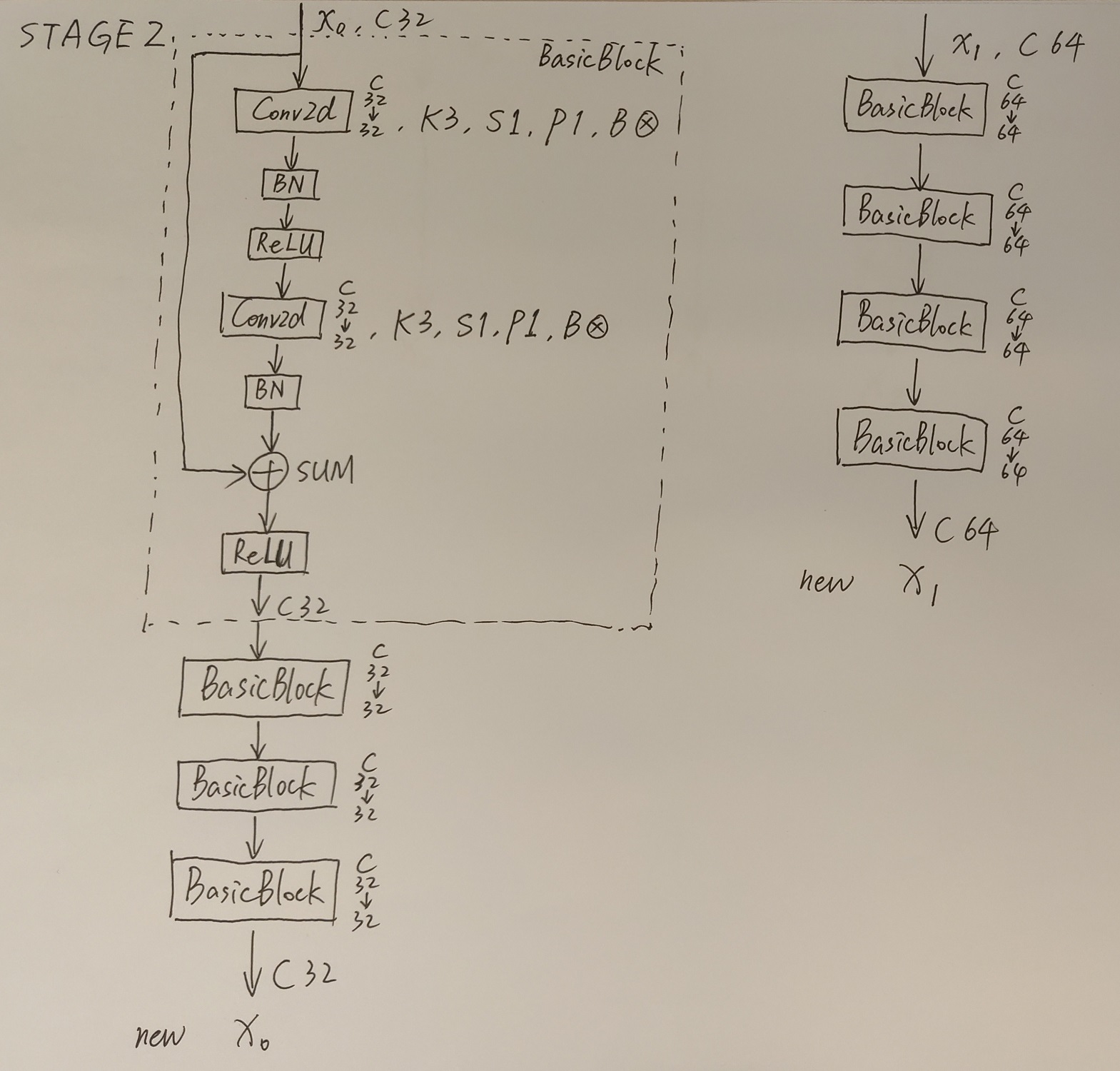
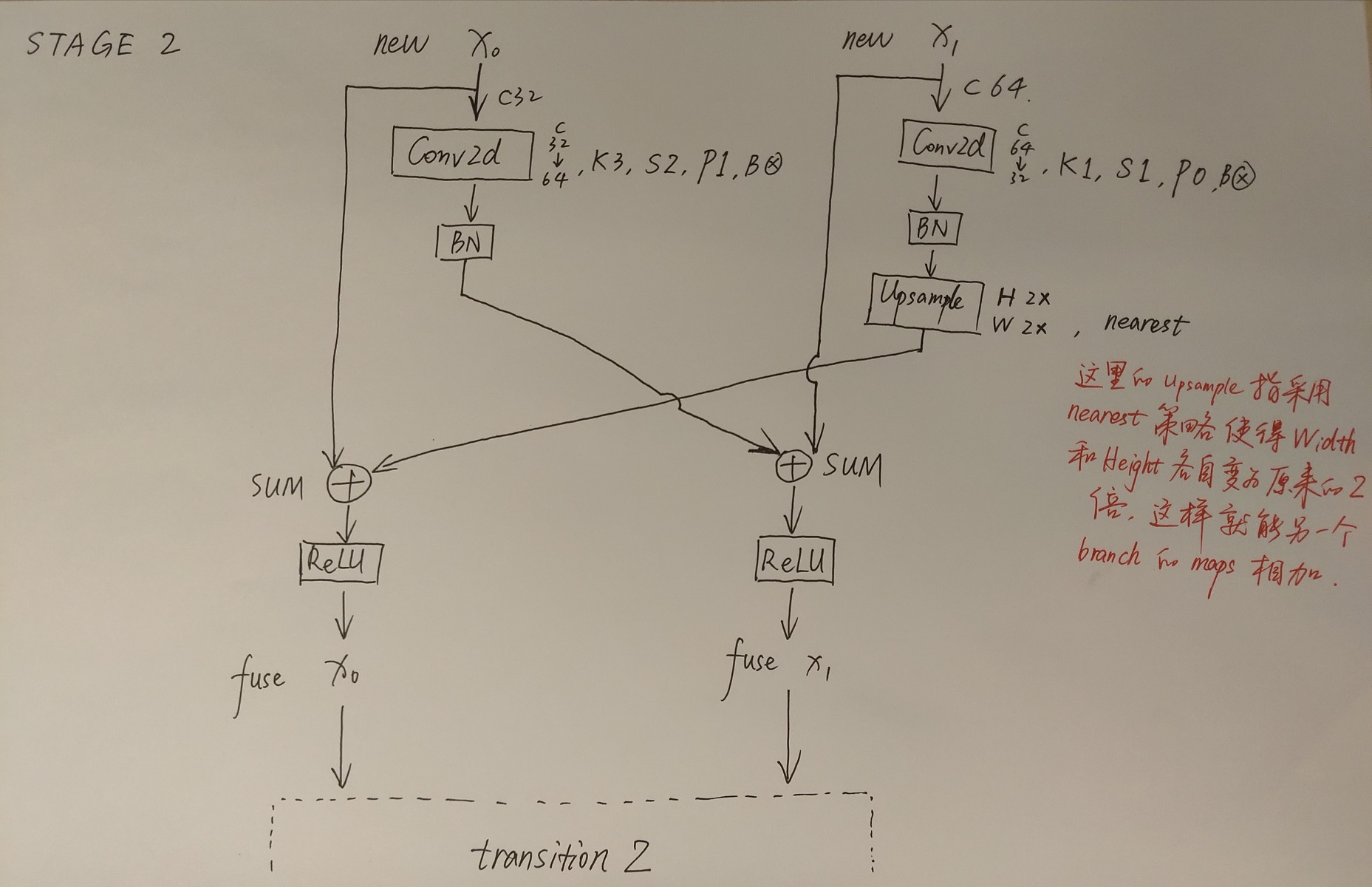
简单介绍完Transition结构后,在来说说网络中最重要的Stage结构。为了方便大家理解,这里以Stage3为例,对于每个尺度分支,首先通过4个Basic Block,没错就是ResNet里的Basic Block,然后融合不同尺度上的信息。对于每个尺度分支上的输出都是由所有分支上的输出进行融合得到的。比如说对于下采样4倍分支的输出,它是分别将下采样4倍分支的输出(不做任何处理) 、 下采样8倍分支的输出通过Up x2上采样2倍 以及下采样16倍分支的输出通过Up x4上采样4倍进行相加最后通过ReLU得到下采样4倍分支的融合输出。其他分支也是类似的,下图画的已经非常清楚了。图中右上角的x4表示该模块(Basic Block和Exchange Block)要重复堆叠4次。

接着再来聊聊图中的Up和Down究竟是怎么实现的,对于所有的Up模块就是通过一个卷积核大小为1x1的卷积层然后BN层最后通过Upsample直接放大n倍得到上采样后的结果(这里的上采样默认采用的是nearest最邻近插值)。Down模块相比于Up稍微麻烦点,每下采样2倍都要增加一个卷积核大小为3x3步距为2的卷积层(注意下图中Conv和Conv2d的区别,Conv2d就是普通的卷积层,而Conv包含了卷积、BN以及ReLU激活函数)。
最后,需要注意的是在Stage4中的最后一个Exchange Block只输出下采样4倍分支的输出(即只保留分辨率最高的特征层),然后接上一个卷积核大小为1x1卷积核个数为17(因为COCO数据集中对每个人标注了17个关键点)的卷积层。最终得到的特征层(64x48x17)就是针对每个关键点的heatmap(热力图)。
首先是整体结构:

其次是对每一模块的详细图示:

另一个手绘HRNet的网络结构---非常详细_枫呱呱的博客-CSDN博客_hrnet网络结构
按照以下代码画的网络结构
simple-HRNet/hrnet.py at master · stefanopini/simple-HRNet · GitHub




4 实验
4.1 COCO关键点检测
数据集: COCO数据集包含超过20万张图像和25万个人实例,这些实例标记了17个关键点。在COCO train2017数据集(57K图像和150K人实例)上训练模型。在val2017数据集(5000张图像)和test-dev2017数据集(20K张图像)上评估本文方法。
评价指标: 标准的评价度量是基于目标关键点相似度(OKS):
![]()
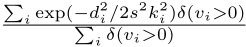

其中,di为所检测关键点与相应GT之间的欧氏距离,vi为GT的可见性标志,s为目标尺度,ki为控制衰减的关键点(per-keypoint)常数。
我们报告标准平均精度和召回分数:AP50(OKS = 0.50的AP) 、AP75、AP(10个位置的AP得分的平均值,OKS = 0.50,0.55,…, 0.90, 0.95)、APM中型目标、 APL大型目标, 在 OKS = 0.50,0.55,…, 0.90, 0.955的AR
训练:
(1)将人体检测框的高度或宽度上扩展到一个固定的长宽比:高:宽= 4:3,然后从图像中裁剪该框,将其大小调整为固定大小,256 × 192或384 × 288。
(2)数据增强包括随机旋转([−45◦,45◦])、随机尺度([0.65, 1.35])、翻转、涉及半身体数据的增强。
(3)使用Adam 优化器;基本学习速率为1e−3,在第170和200个epoch时分别降为1e−4和1e−5;训练过程在210个epoch结束。
测试:
使用两阶段自顶向下范式:使用人检测器检测人实例,然后预测检测关键点。
使用SimpleBaseline为验证集(validation set)和测试开发集(test-dev set)提供的相同的人检测器。通过平均原始图像和翻转图像的热图来计算热图;通过调整最高热值位置(从最高响应到第二最高响应的方向偏移四分之一)来预测每个关键点位置。
验证集上的结果: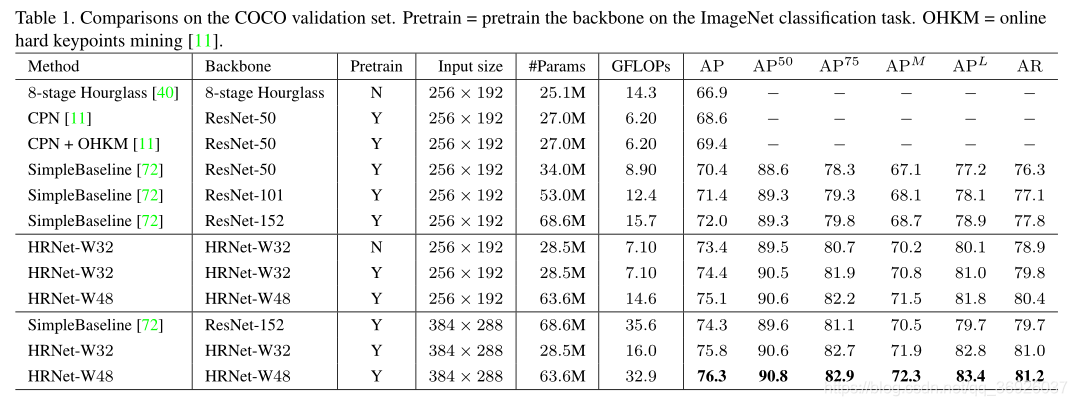
表1报告了本文方法和其他最先进方法的结果。本文小网络HRNet-W32,从头开始训练,输入大小为256 × 192,获得了73.4 AP分数,优于其他相同输入大小的方法。
(1)与沙漏网络相比,HRNet-W32网络提高6.5个百分点的AP,并且网络的GFLOPs要低得多,不到一半,而参数的数量也差不多,略大一些。
(2)与CPN w/o和w/ OHKM相比,HRNet-W32网络模型尺寸略大,复杂度略高,分别获得4.8和4.0的增益。
(3)相比之前表现最好的SimpleBaseline,HRNet-W32获得显著改善:骨干网络为ResNet-50时获得3.0的增益,并且模型大小和GFLOPs相似 ,骨干网络为ResNet-152时获得1.4的增益,但模型大小(参数量)和GLOPs是本文的两倍。
本文网络可以受益于:
(1) ImageNet分类问题的预训练模型的训练:HRNet-W32的增益为1.0点;
(2)通过增加宽度来增加容量:本文大网络HRNet-W48在256 × 192和384 × 288的输入尺寸上分别得到0.7和0.5的改进。
以384 × 288为输入尺寸,HRNet-W32和HRNet-W48的AP分别为75.8和76.3,比256 × 192的输入尺寸提高了1.4和1.2。与使用ResNet-152作为主干的SimpleBaseline相比,HRNet-W32和HRNetW48分别在45%和92.4%的计算成本下获得了1.5和2.0点的AP增益。
测试开发集上的结果: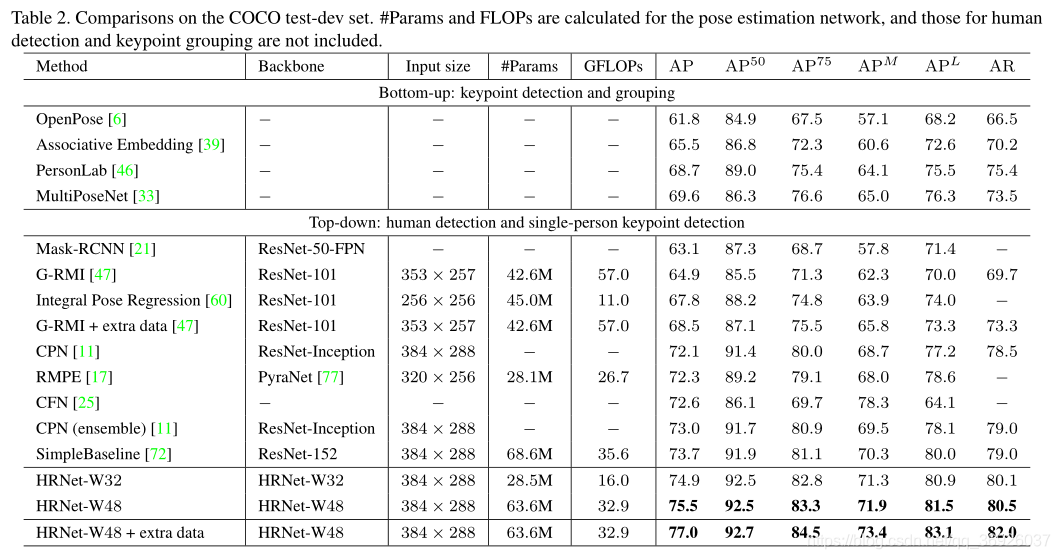
表2本文方法和现有的最先进的方法的姿态估计性能。
(1)本文方法明显优于自底向上的方法。小型网络HRNet-W32的AP达到了74.9,性能优于所有其他自顶向下的方法,并且在模型大小(#Params)和计算复杂度(GFLOPs)方面更高效。大型网络HRNet-W48,达到最高的75.5 AP。
(2)与具有相同输入大小的SimpleBaseline相比,小网络和大网络分别得到了1.2和1.8的改进。使用来自AI Challenger额外训练数据,单个大网络可以获得77.0的AP。
4.2 MPII人体姿态估计
数据集:
MPII人体姿势数据集包含了从广泛的真实世界活动中拍摄的带有全身姿势注释的图像。大约有25K的图像,40K的人实例,其中有12K的人实例用于测试,其余的人实例用于训练。数据增强和训练策略与MS COCO相同,只是为了与其他方法进行公平比较,将输入大小裁剪为256 × 256。
测试:
测试过程几乎与COCO中相同,除了采用标准测试策略来使用提供的person box而不是检测到的person box,进行了一个六尺度金字塔测试程序。
评价指标:
使用标准度量,即PCKh (正确关键点的头部归一化概率)分数。如果落在ground-truth位置的αl 像素内,那么关节是正确的,其中α是一个常数,l是头部大小,对应于ground-truth头部边界框对角线长度的60%。报告[email protected](α = 0.5)的得分。
测试集上的结果: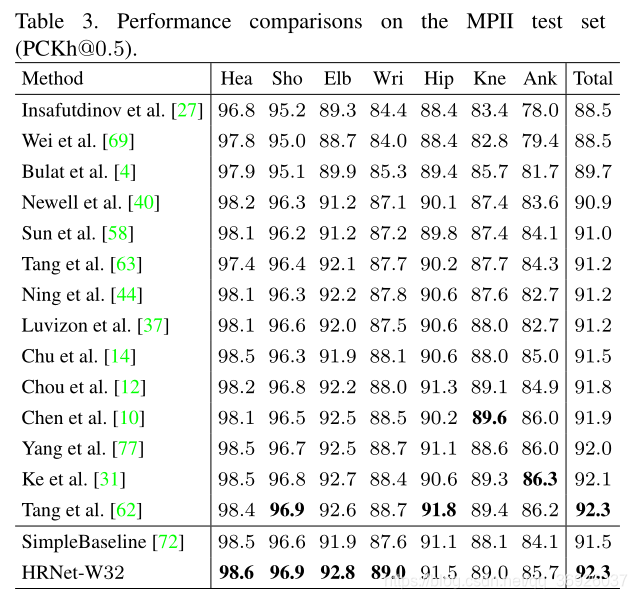
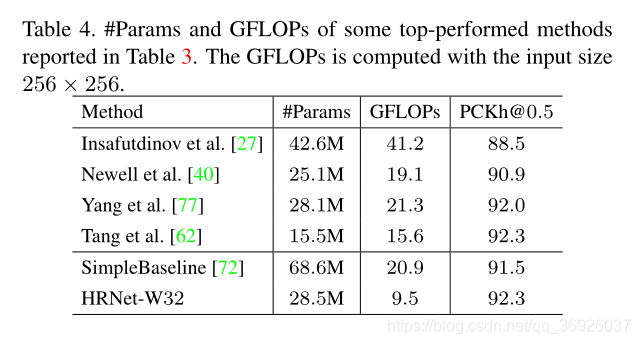
表3和表4显示了[email protected]结果,最优执行方法的模型大小和GFLOPs。使用ResNet-152作为输入大小为256 × 256的骨干,重新实现了SimpleBaseline。HRNet-W32达到了92.3 [email protected]评分,优于堆叠沙漏方法及其延伸。我们的结果与之前发布的最佳结果相同。我们想指出的是,该方法是对我们方法的补充,它利用了组成模型来学习人体的结构,并采用了多层次的中间监督,我们的方法也可以从中受益。测试大网络HRNetW48,得到了同样的结果92.3,原因可能是该数据集中的性能趋于饱和。
4.3 姿态跟踪的应用
数据集:
PoseTrack是一个用于视频中人体姿态估计和关节跟踪的大规模基准。该数据集基于流行的MPII人体姿势数据集提供的原始视频,包含550个视频序列,66374帧。视频序列被分成292,50,208个视频分别用于训练,验证和测试。训练视频的长度在41 ~ 151帧之间,从视频中心开始的30帧被密集标注。验证/测试视频帧数为65 ~ 298帧。来自MPII Pose数据集的关键帧周围的30帧被密集标注,之后每四帧都进行标注。总共大约有23,000个贴有标签的框架和153,615个姿势注释。
评价指标:
从两个方面对结果进行评估:基于帧的多人姿态估计和多人姿态跟踪。姿态估计由平均精度(mAP)评估。通过多目标跟踪精度(MOTA)来评估多人姿态跟踪。
训练:
在PoseTrack2017训练集上训练HRNet-W48用于单人姿态估计,其中网络由coco数据集上预训练的模型初始化;通过将所有关键点(单个人)的边界框扩展15%的长度,从训练帧中的注释关键点中提取人框,作为网络的输入;训练设置,包括数据增强,几乎与COCO相同,除了学习速率从1e−4开始,在第10个epoch下降到1e−5,在第15个epoch下降到1e−6;迭代在20个epoch内结束。
测试:
来跟踪帧之间的姿势,算法包括三个步骤:人框检测与前向传播、人体姿态估计和与相邻帧的姿态关联。使用与SimpleBaseline相同的person box检测器,并根据FlowNet 2.0计算的光流预测关键点,将检测到的box传播到附近的帧中,然后进行非极大值抑制用于边界框移除。该位姿关联方案基于一帧中的关键点与根据光流从邻近帧传播的关键点之间的目标关键点相似性,然后使用贪婪匹配算法计算关键点之间的对应关系附近的帧。
PoseTrack2017测试集的结果: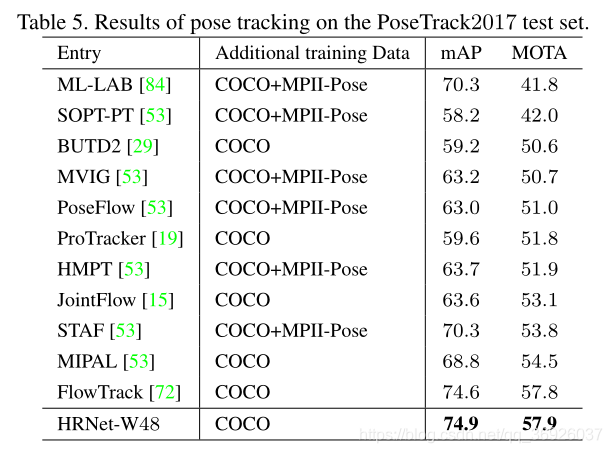
表5报告了结果:
(1)大网络HRNet-W48获得了更好的结果,mAP得分为74.9,MOTA得分为57.9。
(12)与第二好的方法相比——使用ResNet-152作为主干的SimpleBaseline中的FlowTrack,我们的方法在mAP和MOTA方面分别获得了0.3和0.1点的增益。
(3)与FlowTrack相比,与COCO关键点检测和MPII人体姿态估计数据集的优势是一致的,进一步暗示了我们的姿态估计网络的有效性。
4.4 消融研究
研究该方法中各成分对COCO关键点检测数据集的影响。除了对输入尺寸的影响研究外,其他结果均在256 × 192的输入尺寸下得到。
重复多尺度融合:
对重复多尺度融合的效果进行了实证分析,我们研究本文网络的三种变体
( a )没有中间交换单元(1融合):除了最后一个交换单元,多分辨率子网之间没有交换。
( b ) 没有跨阶段交换单元(3个融合):在每个阶段内的并行子网之间没有交换
( c )跨阶段和阶段内交换单元(共8个融合):本文提出的方法。
所有的网络都是从零开始训练的,结果如表6所示,多尺度融合是有益的,多尺度融合可以获得更好的性能。
维持分辨率:
研究一种HRNet变体的性能:四个高分辨率到低分辨率的子网都是在开始时添加的,并且深度相同;融合策略与本文相同。HRNet-W32和变种(带有类似的#参数和GFLOPs)从头开始训练,并在COCO验证集中进行测试,该变体的AP为72.5,低于小网络HRNet-W32的73.4。我们认为原因是在低分辨率的子网上从早期阶段提取的低级别特征没有多大帮助。此外,参数和计算复杂度相似的简单高分辨率网络,在没有低分辨率并行子网的情况下,其性能要低得多。
表征分辨率:
从两个方面研究了表征分辨率对姿态估计性能的影响:
(1)检查每个分辨率(从高到低)的特征图所估计的热图的质量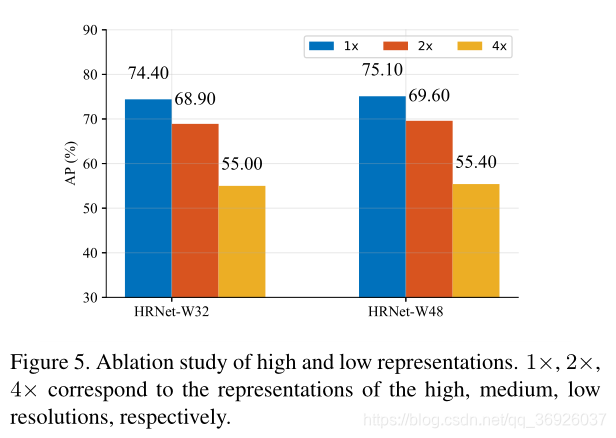
训练大、小网络,网络使用预先训练的ImageNet分类模型初始化,从高到低的分辨率输出四个响应图,最低分辨率响应图的热图预测质量过低,AP得分低于10分。图5报告了AP在其他三个图上的得分。结果表明,分辨率对关键点的预测质量有一定的影响
(2)研究输入大小如何影响热图质量:图6显示了与SimpleBaseline (ResNet50)相比,输入图像大小如何影响性能。相对于较大的输入尺寸,较小的输入尺寸的提高更为显著,原因是在整个过程中都保持了高分辨率,这意味着本文方法在实际应用中更有优势,因为计算成本也是一个重要的因素。
5 结论和未来工作
本文:
提出了一个用于人体姿态估计的高分辨率网络,产生精确和空间精确的关键点热图。成功的原因有两个方面:
(1)在不需要恢复高分辨率的情况下,整个过程都保持高分辨率;
(2)重复融合多分辨率表征,呈现可靠的高分辨率表征。
未来的工作包括应用到其他密集预测任务,例如,语义分割,目标检测,人脸对齐,图像翻译,以及以较少光照的方式聚集多分辨率表示的研究。所有这些都可以在:https://jingdongwang2017.github.io/Projects/HRNet/index.html
附录
ImageNet验证集上的结果
本文网络应用于图像分类任务。在ImageNet 2013分类数据集上对模型进行训练和评估。训练模型100个epoch,批量大小为256。初始学习率设置为0.1,并在30、60和90 epoch减少10倍。模型可以达到与专门为图像分类设计的网络(如ResNet)相当的性能。
HRNet-W32单模型top-5验证误差为6.5%,单模型top-1验证误差为22.7%。
HRNet-W48得到了更好的性能:6.1%的top-5误差和22.1%的top-1误差。使用在ImageNet数据集上训练的模型来初始化姿态估计网络的参数