Abstract
深度学习能够融合一些局部特征,但是在一定程度上忽略了很多的局部有判别力的特征,这个时候需要attention来帮忙,对于常见的结构表达BOW,VLAD也有了长足的发展,NetVLAD,和FisherNet,本文最后的优化采用了NetVLAD的优化方法,解耦了dictionary和descriptor之间的关系
所以本文就是NetVLAD+attention
Architecture
在重复一下之前博客里记录的东西,对于Bow来讲,仅仅描述codeword分配给哪一个local descriptor。但是VLAD会学习一个残差。
X输入为WXHXD,X可以被看成N=WXH个局部描述子,每一个
,i=1,..,N都是D维的向量,所以VLAD产生DK维的表达
,
将hard分配变成soft 分配
对于NetVLAD,最后并没有按照这个公式来,他把
和b_k学习解构,这样就避免了对字典的学习,这也是上一篇博客作者的批判之处,本文采用了这种解耦
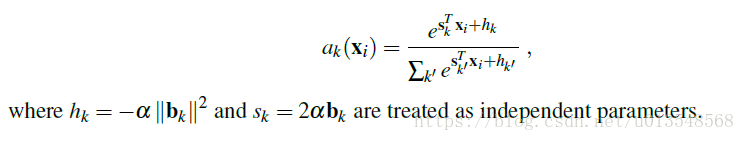
从公式来看,没有去学习 ,变成了去学习 两个参数
Attention
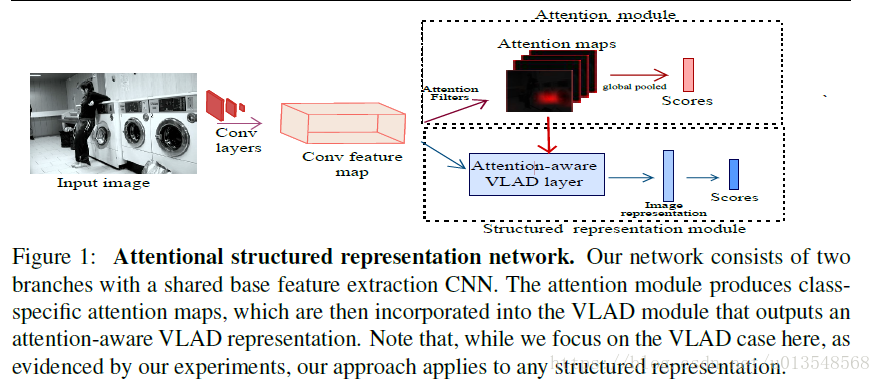
Attention Module
对于WXHXD的特征,作者生成两种attention
- class-agnostic attention: WXHX1,1x1卷积实现
- class-specific attention: WXHXC, C= nClasses
对于class-specific attention,一共有C张attention map,每张的大小都是WXH,然后将这个class-specific attention和class-agnostic attention进行相乘,获得全新的C张attention(H^1,….,H^C)
然后将C张attention map进行global average pooling变成Cx1维的向量,用这个向量去做分类损失。
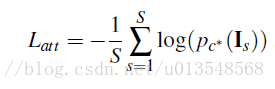
Attention-aware Feature Aggregation
将上面产生的C张attention(H^1,….,H^C)去生成一张单独的attention map
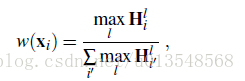
i代表空间位置,l是类别数,也即C张map,
的意思是第i个空间位置元素第l个通道,这个公式的意思是,首先对于C张map,取每一个位置在所有通道上的最大值,构成一张map,然后对这个map做空间softmax,这也符合我们的理解,对于背景一定在所有通道上的值都很小,对于前景一定至少在一个通道会有最大值,经过上面的公式就会产生有效的attention,最后VLAD的表示用attention进行加权
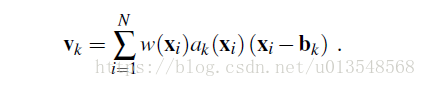
之后对v做L2 norm,然后送入分类网络。
最后的损失是第一个attention的损失和这里的分类损失
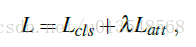
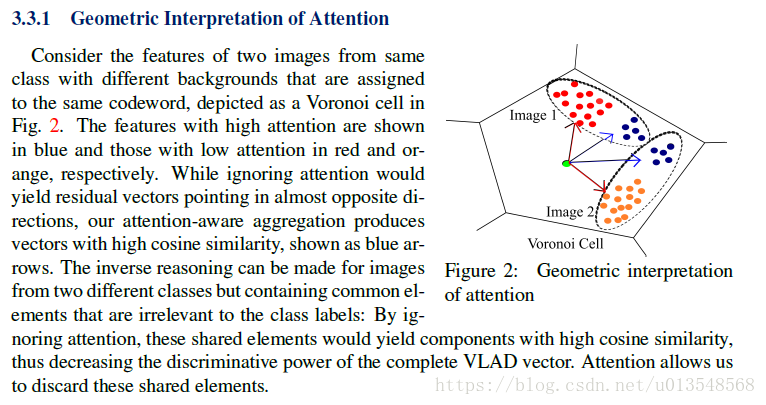
几何解释
实验略