High-Resolution Deep Image Matting
1.背景
在实际应用中,图像抠图经常被用于尺寸为5000 × 5000甚至更高的HR图像。由于GPU内存等硬件限制,以往的深度学习方法无法直接处理HR图像。
适应这些方法的两种常见策略是对输入进行下采样或琐碎的基于patch的推理。前一种策略会导致大部分细节的丢失,而后一种策略会导致patch-wise的不一致。
此外,HR图像在一个patch内可能存在较大甚至完全未知的区域。这进一步要求模型理解来自long-range patches的上下文信息,以实现成功的抠图。
2.内容
提出了一种新的patch-based的深度学习方法 HDMatt,用于高分辨率图像的抠图。
具体来说,将输入图像裁剪成小块,并提出一个 Cross-Patch Contextual module(CPC)来显式捕获cross-patch long-range上下文依赖。对于每个要估计的patch(即query patch),CPC会对图像中与它高度相关的其他patches(即reference patches)进行采样。然后CPC将这些相关的特征整合到一个更可靠的估计中。
在CPC内部,设计了一种新提出的 Trimap-Guided Non-Local(TGNL)操作来有效地传播reference patches中不同区域的信息
3.网络概述
如图所示:

HDMatt在patches上工作,基本上是一个编码-解码器结构。query patch与其相关联的trimap被输入到编码器E(编码器E由骨干特征提取器ResNet34和Atrous Spatial Pyramid Pooling(ASPP) 组成)。context pool中的patches及其trimaps也被输入到共享权重的编码器E中。提取的特征通过Cross-Patch Context (CPC)模块。然后,CPC的输出特征被馈送到解码器,用于query patch的alpha估计。
来自编码器块的pooling outputs被跳过连接到相应的解码器层;在解码器中使用unpooling操作来进行feature map上采样。
绿色和红色框是训练期间的query patch和context patches。黄色框是测试期间两个连续的query patches。
4.裁剪和拼接patch
给出一个训练图像和trimap,在不同的位置随机抽取不同大小(320 × 320,480 × 480,640 × 640)的图像patch及其对应的trimaps,然后将其调整为固定大小320 × 320。
对于那些超过图像边界的补丁,本文使用reflective padding 来填充像素。小的重叠区域有助于在将附近patches的alpha matte缝合在一起时避免边界伪影。特别是,本文设计了一些blending函数来合并相邻patches之间重叠区域的估计alpha值,以实现平滑过渡。
patch-based方法以一种“crop-and-switch”的方式运行。为了获得最终的alpha预测,使用重叠的方法将alpha matte patches缝合在一起。重叠区域为了平滑过渡使用blending来合并
blending:
给定一个预测的alpha matte patch α p,我们为α p中的每个像素α p i分配一个权重w p i。在α p中,在边界上有与相邻patches重叠的区域(OR),中心部分有一个与相邻patches不重叠的区域(NOR)。在NOR中,w p i总是设置为1。在OR中,w p i被定义为:

其中,boundary_dist()是αpi和patch边界之间的最短距离,margin是重叠区域的宽度。因此,OR中的w p i∈ [0,1]。在训练中,w p i被用作权重来计算论文中提到的整体训练损失。最后,对于整个alpha matte中的像素α,它是如下的加权和:

其中,P是整个alpha matte中像素α的重叠面片的数量,ip是对应于像素α的第P个面片中的像素索引。
5.Context Patch 采样
给定一个query patch I q,本文首先计算 I q的未知区域和每个context patch I ci的整个区域之间的相关性。然后从N个context patches 中选择前K个面片,ci≤ N。
具体来说,如图所示:
(下图是Cross-Patch Context(CPC)模块的工作流。它包括一个context patch采样和一个trimap引导的非局部(TGNL)操作。⊗:矩阵乘法(matrix乘法),⊕:feature map连接,●: element-wise乘法。)

I q和I ci连同它们的trimap被馈送到编码器中,以提取更高级的特征图(为简单起见,让q E和c E i表示它们相应的feature maps)。然后q E和c E i被两个卷积层θ和φ进一步嵌入q和c i;
为了获得新特征q的未知区域(U),使用下采样的trimap来归零q的前景(F)和背景(B)区域,即:

其中s是像素索引。然后,两个特征图q U和c i之间的相关性可以通过对它们在每个位置的特征的点积求和来计算,即:

其中s和s’分别为qU和ci中的像素位置。通过softmax操作对 query patch与所有N个context patches之间的相关性进行归一化,得到每个context patch的相似度评分,即:

分数越高,说明候选context patches与query patch中未知区域的相关性越强,因此在信息传播中应该发挥更重要的作用。所以本文根据context patches的相似度评分dci对所有的context patches进行排序,只选择top-K的context patches进行特征传播。
6.trimap引导的Non-Local (TGNL) 操作
对于抠图问题,trimap提供了非常有用的关于前景、背景和未知区域的信息。与前景像素相似的未知像素更有可能是前景像素而不是背景像素,反之亦然。因此,从trimaps指示的不同区域传播上下文信息是很重要的。而最近基于深度学习的抠图方法通常将trimaps作为输入连接起来,这使得他们的方法很难精确地利用这些信息。
为了解决这个问题,本文的方法将trimap信息结合到Non-Local 操作中。具体来说,将query patch的未知区域与context patch的未知区域、前景区域和背景区域分别进行比较。然后,来自三种不同关系(即,U-U、U-F和U-B)的相关特征被连接在一起,并用作解码器输入。

如图所示:
自编码器输出的查询特征q E被两个卷积层θ和δ进一步嵌入到key feature map q和value feature map q ~中。
类似地,每个采样的context patch特征c E i由两个卷积层θ和φ嵌入到key feature map c i和value feature map c i ~中。然后我们使用下采样的query trimap提取未知区域的特征图,即:

那么通过将query patch的U区域与所有采样的上下文片的R区域进行比较而传播的特征可以如下计算:

其中s为聚合feature map fR,s的像素位置。最后,将所有三个区域fU、fF和fB的聚合feature maps串接在一起作为模块输出并用于解码器。
7.损失
损失是α损失Lα和复合损失Lc的平均值。形式上,对于每个像素,损失定义为:
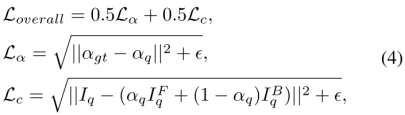
如前所述,在测试期间,在相邻patches之间的重叠区域上采用smooth blending,因此沿着每个训练patch的边界区域的像素应该被相应地加权。因此,使用相同的blending函数作为Loverall损失的一个weighted mask。
8.实验结果
(1)Adobe Image Matting Benchmark
量化对比结果:

视觉效果:

(2)AlphaMatting Benchmark
量化对比结果:

视觉效果:

(3)Real-world Images

(4)Context Patches的注意力可视化

(5)消融实验

第一模块是探讨CPC模块和non-local的有效性
第二模块是探讨patch size的影响
第三模块是探讨context patch数量的影响