
论文链接:Deep High-Resolution Representation Learning for Human Pose Estimation
时间:2019.02 CVPR2019
作者团队:Ke Sun Bin Xiao Dong Liu Jingdong Wang
分类:计算机视觉–人体关键点检测–2D top-down
###目录:
1.HRNet背景
2.HRNet姿态识别
3.HRNet网络架构图
4.引用
1.主要在于学习记录,如有侵权,私聊我修改
2.水平有限,不足之处感谢指出
1.HRNet背景
对于Human Pose Estimation任务,基于深度学习的方法主要有两种,HRNet便是采用基于heatmap的方式:
- 基于regressing的方式,即直接预测每个关键点的位置坐标。
- 基于heatmap的方式,即针对每个关键点预测一张热力图,预测每个位置的分数。
本文由中国科学技术大学和亚洲微软研究院在2019年共同发表,针对2D人体姿态估计任务提出的。
一般来说现有网络都是该网络通过串联高分辨率到低分辨率的卷积(ResNet, VGGNet),然后从编码的低分辨率表示中恢复高分辨率表示。在Hourglass、级联金字塔网络中,高到低与低到高过程中同样分辨率的层进行跳跃连接,目的是融合低级和高级的特征。在级联金字塔网络中,通过卷积操作来融合低级和高级特征。
HRnet在整个过程中维护高分辨率表示。其主要特点是:(i)高分辨率到低分辨率的卷积流并行连接;(ii)跨分辨率重复交换信息。其好处是结果表示在语义上更丰富,在空间上更精确。
2.HRNet姿态识别
- 网络结构部分
文中提出了一种新的体系结构,即高分辨率网络(HRNet),它能够在整个过程中保持高分辨率的表示。第一阶段构建高分辨率子网络,后续阶段逐步添加high-to-low分辨率子网络,并行地连接多分辨率子网络。通过交换贯穿于并行多分辨率子网络的信息指导多尺度融合,并不断重复这个过程。
(1)并行地连接high-to-low分辨率子网络,而不是串联连接。
(2)重复的多尺度融合,利用相同深度、相似水平的低分辨率表示提高高分辨率。

该论文的核心思想就是不断地去融合不同尺度上的信息,HRNet首先通过两个卷积核大小为3x3步距为2的卷积层共下采样4倍。然后通过Layer1模块调整通道个数,不改变特征层大小。
再通过一系列Transition结构以及Stage结构,每通过一个Transition结构都会新增一个尺度分支。
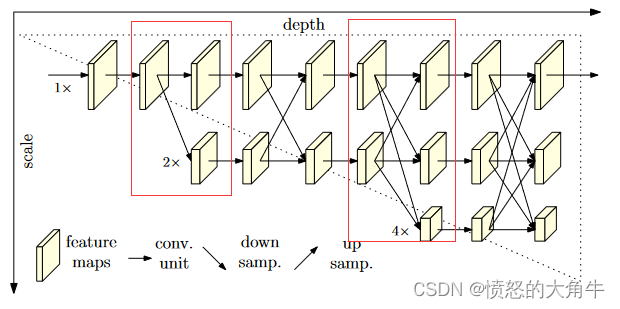
经过Stage时,对于每个尺度分支,首先通过n个Basic Block,然后融合不同尺度上的信息。对于每个尺度分支上的输出都是由所有分支上的输出进行融合得到的。
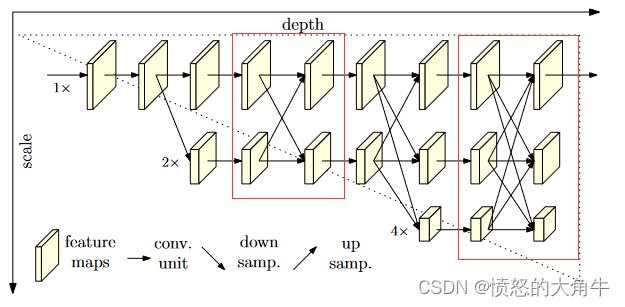
在Stage4中的最后一个Exchange Block只输出下采样4倍分支的输出,然后接上一个卷积核大小为1x1xn(n为关键点数)的卷积层。最终得到的特征层(64x48xn)的heatmap。根据heatmap寻找最大score可以找到位置坐标点,接着分别对比该点左右上下两侧的score,最终预测的坐标向最大的那一侧偏移0.25。
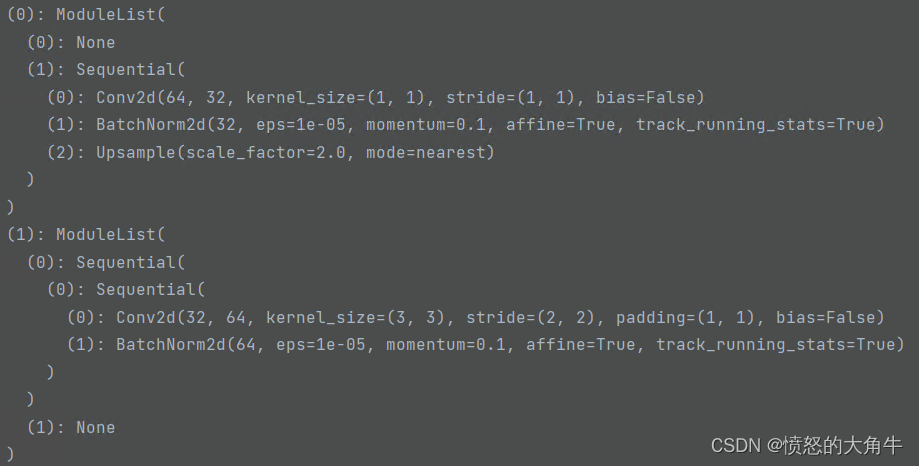
stage2中上下采样的流程:
- 结果评估
使用的两阶段自顶向下范式:使用人检测器检测人员实例,然后预测检测关键点。
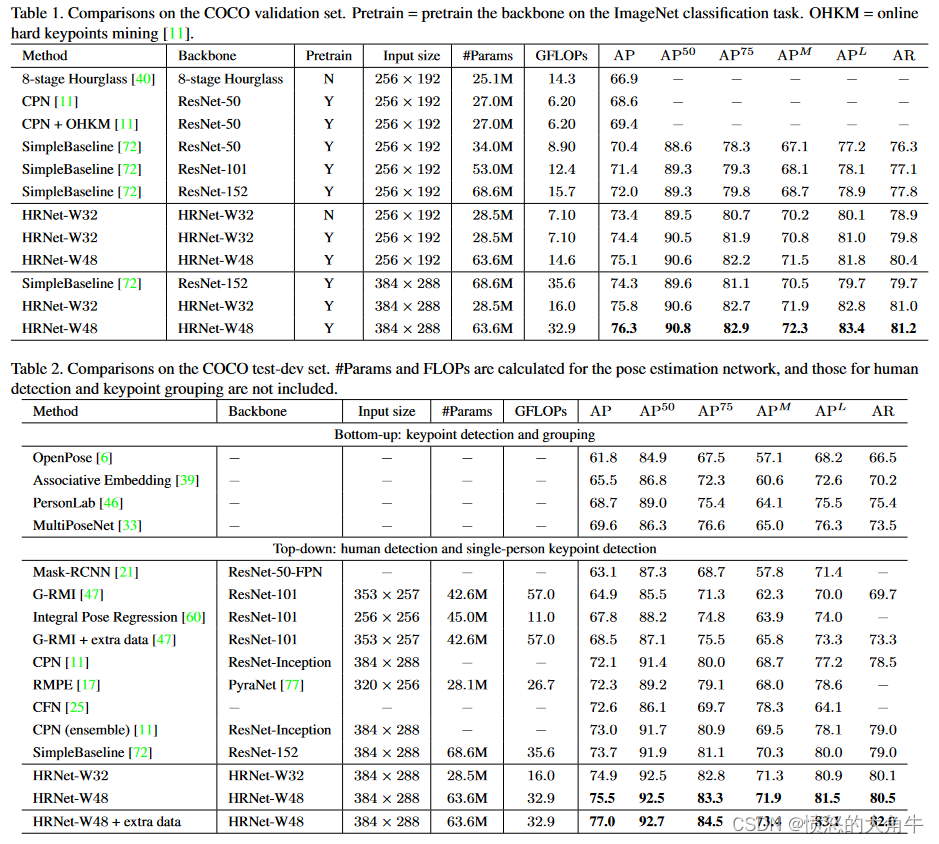
COCO测试集上的结果图:
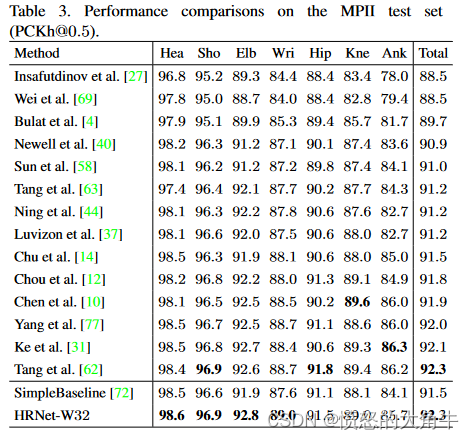
MPII Human Pose Estimation
3.HRNet网络架构图
