无监督学习
如果可以建立一种通用的无监督模型,经过海量无标签数据的学习后,可以习得一个强大的特征提取器,在面对新的任务,尤其是医疗影像等小样本任务时,也能提取到较好的特征。这就是无监督学习的意义。
对比学习
对比学习的概念很早就有了,它是无监督学习的一种方法,但真正成为热门方向是在2020年的2月份,Hinton组的Ting Chen提出了SimCLR,用该框架训练出的表示以7%的提升刷爆了之前的SOTA,甚至接近有监督模型的效果。
对比学习不需要高细粒度的还原,它所记住的事物特征,不一定是像素级别的,而是更高维度的,这样也就会丢失部分细节。
既没有监督信息,又不需要重构数据,那如何学习呢?
答案是数据增强+互信息
数据增强augmentation:
-
颜色数据增强,对图像亮度、饱和度、对比度进行调整,最常见的是对亮度进行调整。
-
裁剪(crop),对图像进行随机裁剪;也可以先进行缩放,再进行裁剪。
-
反转(flip),进行水平或者垂直的反转。
-
平移变换(shift)。
-
旋转/仿射变换。
-
添加噪声(noise),添加高斯噪声。
-
模糊(blur),对图像进行模糊处理。
互信息
如果对最大化互信息的目标进行推导,就会得到对比学习的loss(也称InfoNCE),其核心是通过计算样本表示间的距离,拉近正样本,拉远负样本。也就是说,当我们能够区分该样本的正负例时,得到的表示就够用了。
基本模型
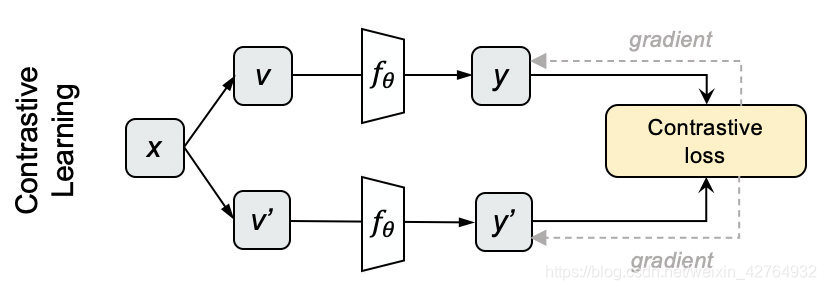
- 采样N个图片,用不同的数据增强方法为每个图片生成两个view
- 分别将他们输入网络,获得编码表示y和y’。
- 我们对上下两批表示两两计算cosine,得到NxN的矩阵,每一行的对角线位置代表y和y’的相似度,其余代表y和N-1个负例的相似度。对每一行做softmax分类,采用交叉熵损失作为loss,就得到对比学习的损失了 L y = − log e x p ( y ⋅ y ′ / τ ) ∑ i = 0 N e x p ( y ⋅ y ′ / τ ) L_{y}=- \log \frac{exp(y \cdot y^{\prime}/ \tau)}{\sum _{i=0}^{N}exp(y \cdot y^{\prime}/ \tau)} Ly=−log∑i=0Nexp(y⋅y′/τ)exp(y⋅y′/τ)其中 τ \tau τ 是可调节的系数, 点乘后的结果的量级不适合softmax运算,通过一个 τ \tau τ 系数控制。
优化方向简单来说就是增加view难度、增加更多负例、提升encoder表现等。。。
那为啥正样本是同一张图的不同aug,负样本直接就是不同图及aug,不怕同类的不同图干扰吗?解释链接https://blog.csdn.net/weixin_42764932/article/details/112927959
优化模型end2end、memory bank、MoCo
把负例咔咔地往上整,不信它优化不好
先来几个定义
从一张图片中进行采样(crop),如果当前采样图片与另外一张图片来源于同一张图片,那么该图片就被为当前图片的一个正样本,否则则认为是负样本。
所以当前采样图片我们称之为query,同时我们会将一系列的图片保存起来,形成一个图片集,并集合成一个dictionary,这些图片的特征作为这个dictionary的key,损失函数如下:
L q = − log e x p ( q ⋅ k + / τ ) ∑ i = 0 K e x p ( q ⋅ k i / τ ) L_{q}=- \log \frac{exp(q \cdot k_{+}/ \tau)}{\sum _{i=0}^{K}exp(q \cdot k_{i}/ \tau)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
其中 q q q 表示query的特征, k i k_i ki表示dictionary中特征key, k + k_+ k+表示 q q q 在dictionary中的一个正样本(假设有且只有一个), τ \tau τ是一个超参数,用于调整上述loss的。
end2end
不咋地
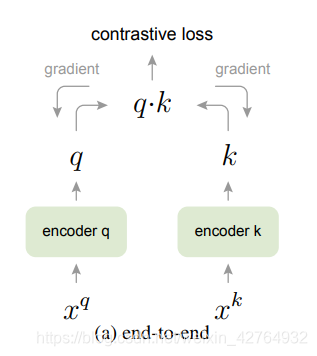
它使用当前batch中的样本作为dictionary,因此key是一致编码的(通过相同的编码器参数)。其中1个可以匹配的key,K个不可以匹配的key。但是受限于GPU,batch不可能太大,dictionary也就大不了,想尽了办法使用了大batch,又会遇到大batch本身优化难的问题;如果batch小的时候,下一个batch和该batch的参数不一样了,就不能保持一致了。
memory bank
也不咋地
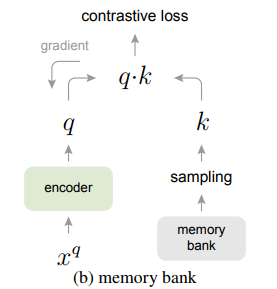
设立memory bank,把之前编码好的样本存储起来,每个batch的dictionary都是从memory bank中随机抽取,不进行反向传播,因此可以支持大的dictionary。
但这样有个问题是存储好的编码都是之前的编码器计算的,而 左侧编码器一直在更新,会有两侧不一致的情况,影响目标优化。一个可行方法之一就是用最新的左侧encoder更新编码再放入memory bank,但这依然避免不了memory bank中表示不一致的情况,实验效果很差。还有研究用动量去更新样本表示,但这样必须存储所有样本,消耗过多内存。
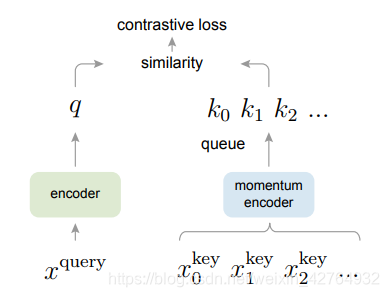
MoCo
所以何凯明带着MoCo来拯救世界了
代码https://github.com/facebookresearch/moco
-
记 x x x 为一个batch的原始数据,经过augmentation分别得到 x q , x k x^{q}, x^{k} xq,xk
-
f q ( . ) f_q(.) fq(.)和 f k ( . ) f_k(.) fk(.)分别为query和key的encoder,参数分别为 θ q \theta_{q} θq和 θ k \theta_{k} θk
-
分别将增强后的数据输入,得到表示 q q q和 k k k, q = f q ( x q ) , k = f k ( x k ) q=f_{q}(x^{q}),k=f_{k}(x^{k}) q=fq(xq),k=fk(xk)
两大创新
其一:dictionary队列化,把dictionary整成长度为K的队列,每次计算loss时就用K个负样本,然后将当前batch得到的特征 k k k(瞅好了,是k,不是q,k配合着创新二可以让key保持一致性) 入队,队头的batch出队,维持长度为K。
dictionary的大小不需要受batchsize的约束,可以设置成任意大小.
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
@torch.no_grad()
def _dequeue_and_enqueue(self, keys):
# gather keys before updating queue
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # for simplicity
# replace the keys at ptr (dequeue and enqueue)
self.queue[:, ptr:ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K # move pointer
self.queue_ptr[0] = ptr
其二:Momentum update,因为dictionary的key来自于不同的mini-batch,通过这种方式缓慢更新(slowly progressing)key的encoder,使得key的特征保持一致性。
好处在于:避免了因为encoder的剧烈变化导致特征丢失一致性,同时也保持encoder一直处于被更新的状态。 θ k = m θ k + ( 1 − m ) θ q \theta_{k}=m \theta _{k}+(1-m)\theta _{q} θk=mθk+(1−m)θq
实验发现,适当增加m会带来更好地效果,因此本文 m=0.999,也印证了缓慢更新key的encoder是使用队列dictionary的核心。
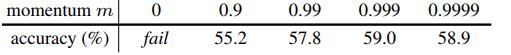
@torch.no_grad()
def _momentum_update_key_encoder(self):
"""
Momentum update of the key encoder
"""
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
为啥这么搞呢?
在优化的过程中,如果key的encoder剧烈变化,key的特征也随着发生较大变化。query的encoder也在训练初期是在剧烈变化,而query的特征在softmax的分子,key在分母,当softmax的分子和分母均有巨大变化的时候,对于无监督的优化可能不是那么友好。因此MoCo限制了key的encoder的剧烈变化,相当于分母项的扰动少了,有助于query的encoder的更新。
https://blog.csdn.net/FatMigo/article/details/103211622
流程伪代码

-
记 x ∈ R N ∗ C ∗ H ∗ W x\in R^{N*C*H*W} x∈RN∗C∗H∗W 为一个batch的原始数据,经过augmentation分别得到 x q , x k x^{q}, x^{k} xq,xk
-
分别将增强后的数据输入l两个encoder,得到表示 q q q和 k k k, q = f q ( x q ) , k = f k ( x k ) q=f_{q}(x^{q}),k=f_{k}(x^{k}) q=fq(xq),k=fk(xk)
-
k = k . d e t a c h ( ) k=k.detach() k=k.detach(), 这一路删了梯度,不再反传,就是凯明在文章《Exploring Simple Siamese Representation Learning》中提出的stop-gradient,即在计算相似性时,其中一个样本的新表示作为叶子节点,不计算梯度。该方法避免了孪生网络在无监督学习中陷入崩溃解,使得孪生网络可以为无监督学习领域提供更简洁的方案。
-
计算 q q q 和 k k k 的互信息作为正类logits,大小为N
-
计算 q q q 和队列即dictionary中的key的互信息作为负类logits,大小为N*K
-
将正类logits和负类logits拼接,大小为N*(1+K),然后依据公式计算损失
-
损失反传,更新 q q q 的encoder f q ( . ) f_q(.) fq(.)
-
根据动量公式,更新 k k k 的encoder f k ( . ) f_k(.) fk(.)
-
将当前batch得到的特征 k k k 入队,队头的batch出队,维持长度为K。
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum('nc,nc->n', [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum('nc,ck->nk', [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
性能
指腚是牛皮,一上来就是一个state-of-the art
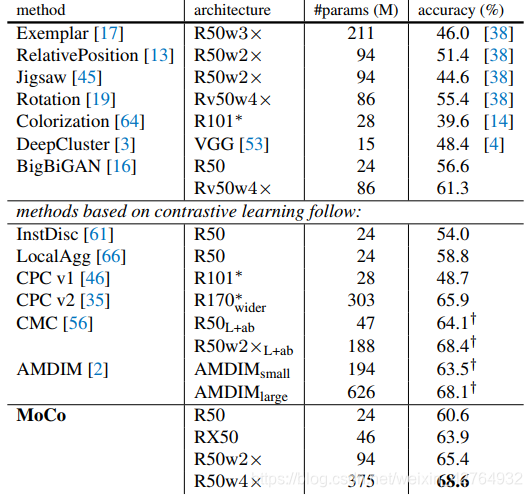
结果就被SimCLR刚了7个点。。。
刚才有个朋友问我,何老师发生肾么事了,
我一看,嗷,源濑氏佐天,有几个年轻人,塔们说,我的MoCo没用,
我说有用,
我一说,他啪就站起来了,很快啊,
然后上来就是一个最优数据增强组合,一个非线性映射,一个加负例!
我全部防出去了,防出去以后自然是传统功法的点到为止,没打他,我笑一下,准备收拳。因为按传统功夫的点到为止他他已经输了。
我收拳的时间不打了,
他突然袭击,
我大意了啊,没有闪。
我说小伙子你不讲武德,
他忙说对不起,我不懂规矩啊何老师,他说他是乱打的。
塔克不是乱打的啊,
后来他说他带了128块TPU,整了9000个以上样本的米妮batch ,开了1000轮的训练,看来是有bear来。
这俩年轻人, 不讲武德,
来,骗
来, 偷袭
我何老师
这号码
这不好
握拳这位年轻人,耗子尾汁,
好好反思,以后不要再犯这样的小聪明,
DL要以和为贵,要讲武德,不要搞窝里斗,
来我被窝里抖