0. 前言
- 相关资料:
- arxiv
- github
- 论文解读(写得很好,值得看)
- 本文中截图来自论文或上面这篇博客
- 论文基本信息
- 领域:姿态估计
- 作者单位:中国科学技术大学&微软亚洲研究院
- 发表时间:CVPR 2019
- 一句话总结:提出一种新的backbone设计思路,即不同尺寸的特征图之间进行多次信息融合。
1. 要解决什么问题
- 为了获取图像中的位置信息(如目标检测、姿态估计、图像分割任务),一种常见的解决方案是增加特征图的尺寸,一般网络就是先下采样再上采样,且下采样、上采样过程中相同尺寸的特征图之间可能有skip connection。
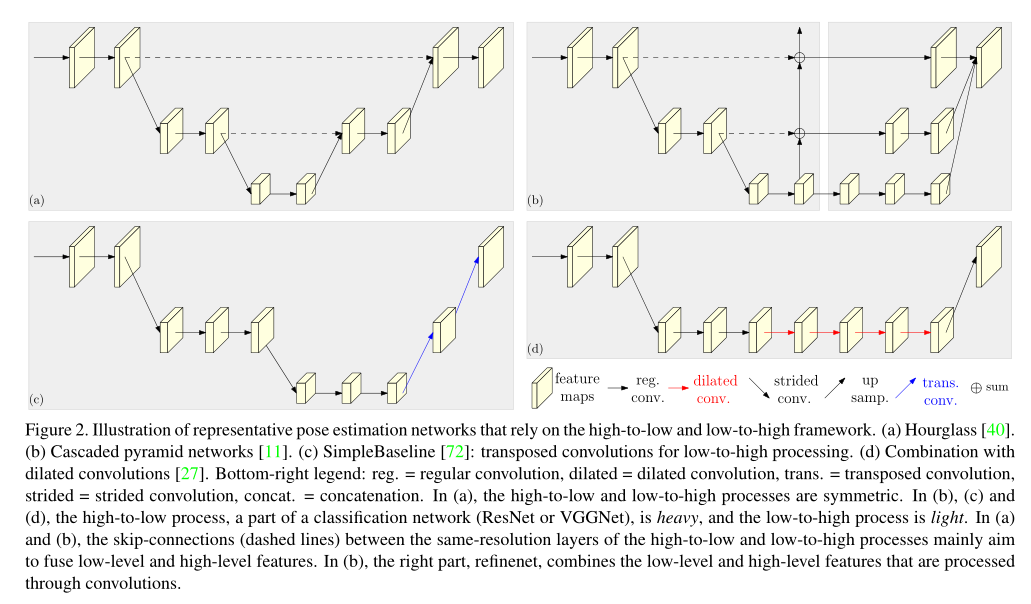
- 现有的方法如下图
- a是hourglass结构
- b是cascade pyramid结构
- c是simplebaseline结构
- d中使用了空洞卷积
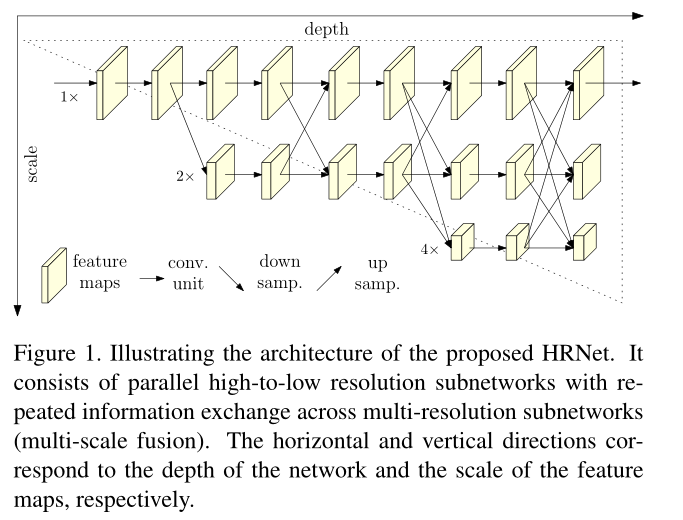
2. 用了什么方法
-
说白了,就是不同尺寸间特征图相互连接(有FPN的感觉,但也不完全是,毕竟1x的通道从头到尾都有)
-
不同尺寸间特征图应该如何融合呢
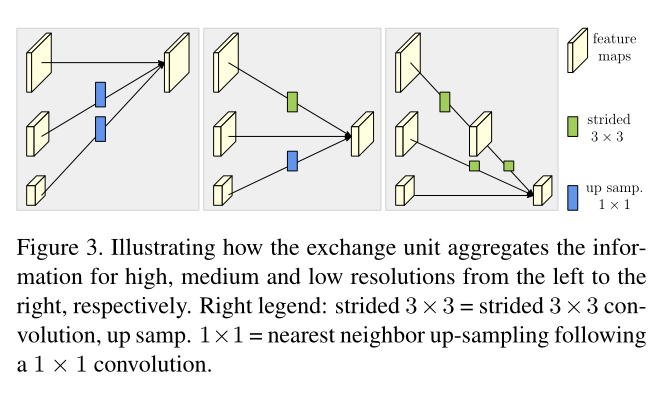
- 最终结果预测好像用的就是最高尺寸的特征图,其他的没用上。
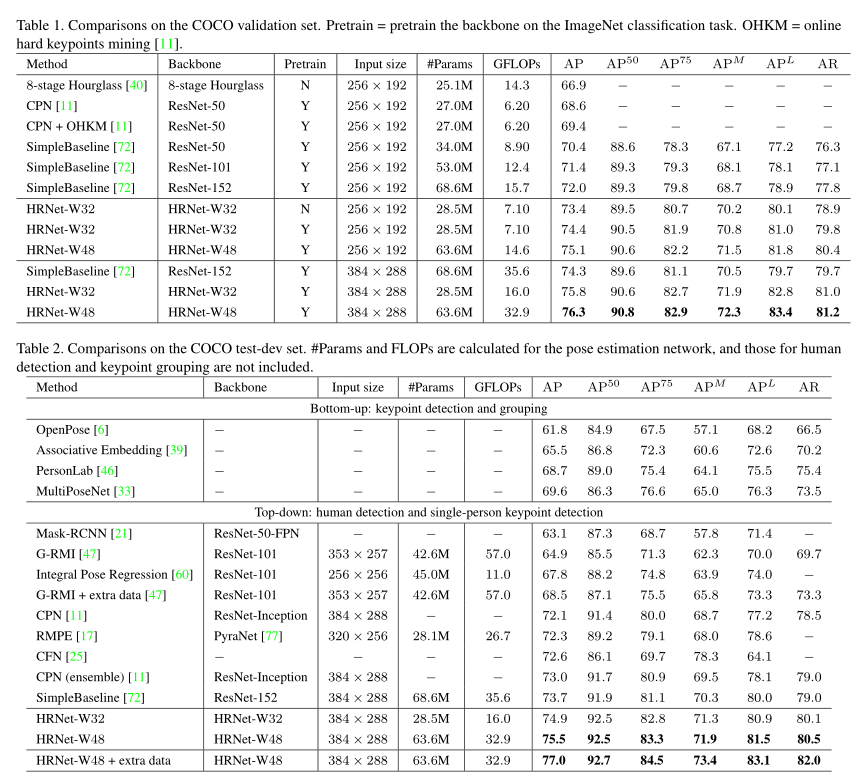
3. 效果如何
- 横扫COCO/MPII/PoseTracking
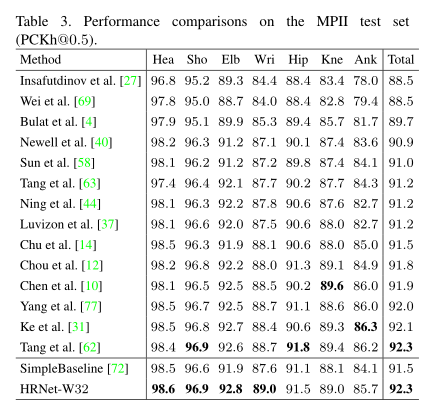

4. 还存在什么问题&可借鉴之处
- 这种结构应该非常消耗算力和显存吧。毕竟连了这么多。