动机:
Unsupervised representation learning is highly successful in natural language processing,but supervised pre-training is still dominant in computer vision. The reason may stem from differences in their respective signal spaces, Language tasks have discrete signal spaces, Computer vision, in contrast, as the raw signal is in a continuous, high-dimensional space and is not structured
【CC】无监督在NLP领域大获成功,但在CV领域没啥动静。大佬认为可能是两个领域的信息空间差异比较大:NLP是离散化的/低维度的结构化信息,CV是连续的/高维度非结构化信息
意义:
These results show that MoCo largely closes the gap between unsupervised and supervised representation learning in many computer vision tasks
【CC】本文的方法在CV大幅抹平监督-无监督的GAP
前置知识- 对比学习 as dictionary look-up
Though driven by various motivations, these methods can be thought of as building dynamic dictionaries. The“keys” (tokens) in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network. Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others. Learning is formulated as minimizing a contrastive loss.
【CC】大佬认为对比学习的本质是“构造字典-查字典”. 一个key,类比NLP的token,是由一个encoder(学习出来的NN网络)从一幅图片或者图片的一部分编码而成. 假设这个encoder已经训练好了,现在来做“查字典”:给定已经编码好的一条“query”(即待确认的一副图片),该“query”应该跟正样本的距离更近而跟负样本的距离更远(很像triplet loss). 整个过程就是学习一个encoder使得这个contrastive loss最小
Contrastive learning [29], and its recent developments, can be thought of as training an encoder for a dictionary look-up task Consider an encoded query q and a set of encoded samples {k0, k1, k2, …} that are the keys of a dictionary. Assume that there is a single key (denoted as k+) in the dictionary that q matches. A contrastive loss [29] is a function whose value is low when q is similar to its positive key k+ and dissimilar to all other keys (considered negative keys for q). With similarity measured by dot product, a form of a contrastive loss function, called InfoNCE [46], is considered in this paper:
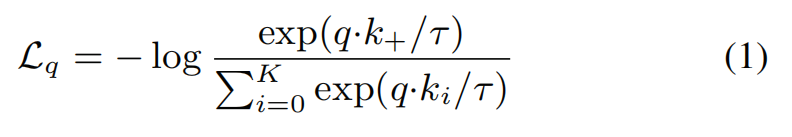
where τ is a temperature hyper-parameter
【CC】query q是待确认的图片编码, {k0, k1, k2, …} 是整个字典. 假定在字典中一定存在一个k+跟q匹配(实际这个k+就是通过图片样本经过数据增强得到的,所以字典中一定有一个k+,这是pretext任务完成的). contrastive loss 目标函数使得:q跟k+的距离很近,跟其他负样本很远. 这里引入NCE这个目标函数形式就是一个softmax函数,只不过分母中包含的是一个正样本+K个负样本,就像一个K+1的分类的CE
In general, the query representation is q = fq(xq) where fq is an encoder network and xq is a query sample (likewise, k = fk(xk)).
【CC】fq就是正样本的encoder,xq是正样本的编码;fk是字典的encoder, xk是字典的编码
创新点:
From this perspective, we hypothesize that it is desirable to build dictionaries that are: (i) large and (ii) consistent as they evolve during training. Intuitively, a larger dictionary may better sample the underlying continuous, high dimensional visual space, while the keys in the dictionary should be represented by the same or similar encoder so that their comparisons to the query are consistent.
【CC】一个好的字典要满足两个条件: 1)字典越大越好 2)字典编码要有一致性
We maintain the dictionary as a queue of data samples: the encoded representations of the current mini-batch are enqueued, and the oldest are dequeued. The queue decouples the dictionary size from the mini-batch size, allowing it to be large. Moreover, as the dictionary keys come from the preceding several mini-batches, a slowly progressing key encoder, implemented as a momentum-based moving average of the query encoder, is proposed to maintain consistency. Our hypothesis is that good features can be learned by a large dictionary that covers a rich set of negative samples, while the encoder for the dictionary keys is kept as consistent as possible despite its evolution.
【CC】通过queue来维护字典:当前mini-batch的编码进队列,最老的一批出队列。这么做queue的size(即字典大小)跟mini-batch的size解耦了,这样可以把字典做很大。另一个好处是可以通过动量更新的方式去更新encoder。这样就保持了一定的编码一致性。说白了,就是针对上面两个必要条件做优化
Dictionary as a queue
At the core of our approach is maintaining the dictionary as a queue of data samples. The introduction of a queue decouples the dictionary size from the mini-batch size. Our dictionary size can be much larger than a typical mini-batch size, and can be flexibly and independently set as a hyper-parameter.
【CC】这里不用翻译了,还是在讲queue的好处
Momentum update
We hypothesize that such failure is caused by the rapidly changing encoder that reduces the key representations’ consistency. Formally, denoting the parameters of fk as θk and those of fq as θq, we update θk by:
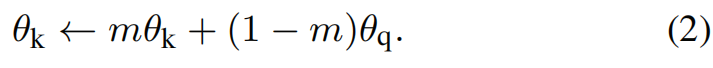
Here m ∈ [0, 1) is a momentum coefficient. As a result, though the keys in the queue are encoded by different encoders (in different mini-batches), the difference among these encoders can be made small.
【CC】首先,我们的encoder fq/fk是NN网络, 其参数为θq/ θk. 这里通过式子(2)来更新θk, 即上一个时刻的θk加上θq更新当前的θk,说白了就是一个简单的线性权重相加(非常像遗传算法里面的启发函数),这里的m超参
框架&实现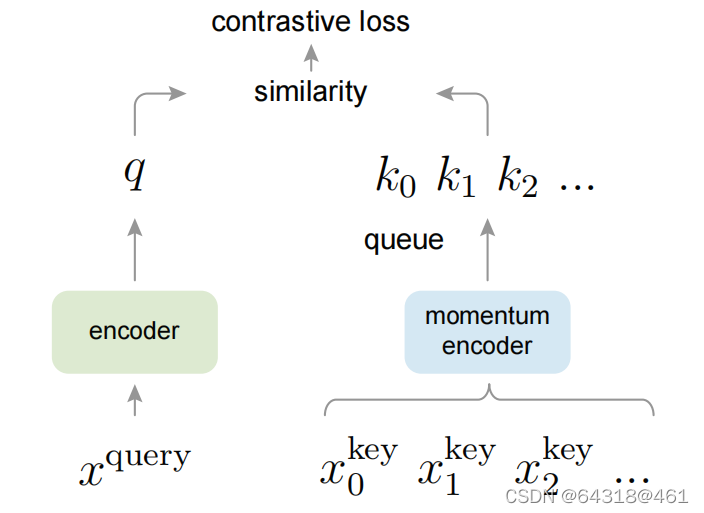
Momentum Contrast (MoCo) trains a visual representation encoder by matching an encoded query q to a dictionary of encoded keys using a contrastive loss. The dictionary keys {k0, k1, k2, …} are defined on-the-fly by a set of data samples.The dictionary is built as a queue, with the current mini-batch enqueued and the oldest mini-batch dequeued, decoupling it from the mini-batch size. The keys are encoded by a slowly progressing encoder, driven by a momentum update with the query encoder.This method enables a large and consistent dictionary for learning visual representations.
【CC】contrastive loss是上面的NCE。整个流程就如上图:xq通过encoder fq得到token q,跟字典里面的各种xk做 contrastive loss. xk的encoder是通过式子(2)的方式对fk进行更新

Code: https://github.com/facebookresearch/moco
【CC】伪代码和实现都在上面了,福利啊
- Pretext Task
we use a simple one mainly following the instance discrimination task. Following [61], we consider a query and a key as a positive pair if they originate from the same image, and otherwise as a negative sample pair.
【CC】这里使用了非常原始的instance discrimination task:当前图片通过数据增强(就是简单的corp)得到对应的正样本,数据集中其他图片都是负样本
- encoder
We adopt a ResNet as the encoder,whose last fully-connected layer (after global average pooling) has a fixed-dimensional output (128-D [61]). This output vector is normalized by its L2-norm. This is the representation of the query or key.
【CC】encoder网络直接使用resnet,输出的矢量(128D)L2正则化即为编码
- Shuffling BN
The model appears to“cheat” the pretext task and easily finds a low-loss solution. For the key encoder fk, we shuffle the sample order in the current mini-batch before distributing it among GPUs (and shuffl back after encoding); the sample order of the mini-batch for the query encoder fq is not altered.
【CC】因为BN容易产生static info的信息泄露,而模型会通过泄露的信息去cheat(找到梯度下降最快的路径). Mini-batch内打乱字典图片的顺序,查询图片的顺序不变
比较其他对比学习
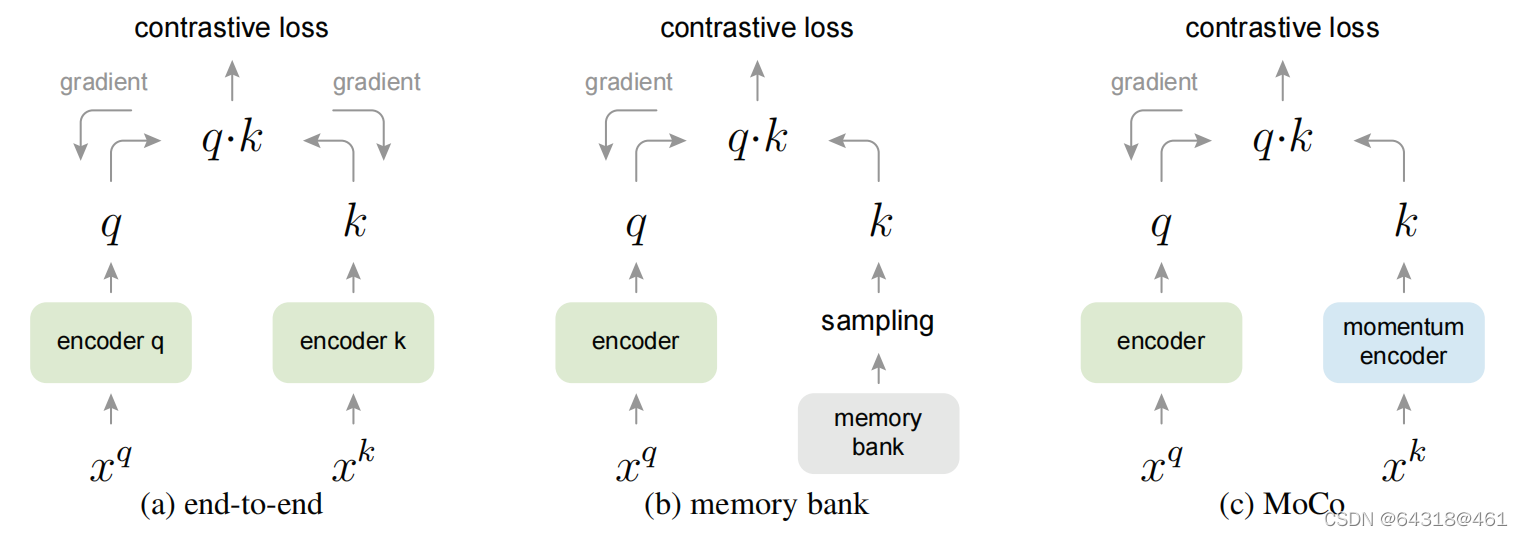
Conceptual comparison of three contrastive loss mechanisms (empirical comparisons are in Figure 3 and Table 3). Here we illustrate one pair of query and key. The three mechanisms differ in how the keys are maintained and how the key encoder is updated.
(a): The encoders for computing the query and key representations are updated end-to-end by back-propagation (the two encoders can be different).
(b): The key representations are sampled from a memory bank .
©: MoCo encodes the new keys on-the-fly by a momentum-updated encoder, and maintains a queue (not illustrated in this figure) of keys.
【CC】end-to-end的方式比较native一点,coder q和k 都是通过反向传播自行训练, 可以预料到每个batch间的encoder方式不一样效果不好; memory bank的方式必然收到内存大小的限制; moco就不说了。 其实本文还有后续研究, 发现通过moco方式训练出来的represetation跟监督方式训练出来的表达差别非常大:比如在后面fine-tune时,moco需要特别大的学习率,比如30