《Deep High-Resolution Representation Learning for Human Pose Estimation》
来源:中科技大学,微软亚洲研究院
论文:https://arxiv.org/pdf/1902.09212.pdf
源码:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
0 前沿
本文设计了新的人体姿态估计模型,刷新了三项COCO纪录,还中选了CVPR 2019。
简称HRNet,拥有与众不同的并联结构,可以随时保持高分辨率表征,不只靠从低分辨率中恢复高分辨率表征,其在姿势识别的效果明显提升:
不但如此,HRNet在COCO数据集的关键点检测、姿态估计、多人姿态估计这三项任务里,HRNet都超越了所有前辈。
1 相关研究
本文重点在其HRNet结构上,其他研究与前面点一些人体姿态论文(CPN,SimplePose等)并无差异,可以参见本人前期博客,这里就忽略了,重点来看看HRNet结构
2 HRNet
2.1 整体思路
在人体姿态任务中,之前一些方法,如CPN,SimplePose等,重建高分辨率表征都是从低分辨中恢复的,一般是通过一个从高到低分辨率网络结构(如VGG,Resnet)中用低分辨率恢复高分辨率表征;在CPN中有提到过,较高的空间分辨率有利于特征点精确定位,低分辨率具有更多的语义信息
我想作者也是基于了这一细想(个人理解),设计了高低多分辨率网络并联的网络结构来提取特征,如下图
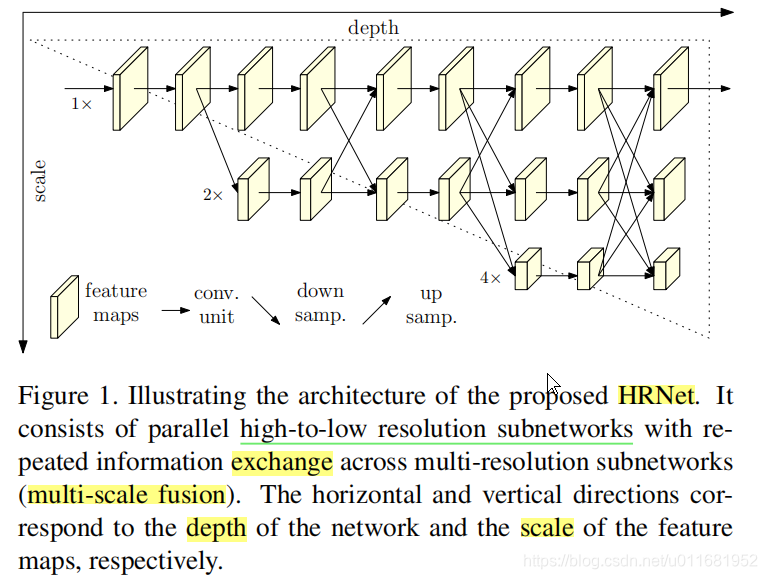
1)它从一个高分辨率的子网络开始,慢慢加入分辨率由高到低的子网络。
2)HRNet结构分为纵向Depth和横向Scale两个维度
3)横向上,不同分辨率点子网络并行(parallel)
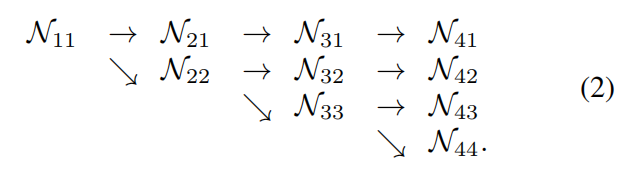
4)且进行多分辨率信息融合(multi-scale fusion),即 exchange unit

5)输出热力图
2.2 整体结构
1)整体流程:4 stages
input–>>stages1(conv1–>bn1–>conv2–>bn2–>layer1)–>>stages2(transition1–>stage2)–>>stages3(transiton2–>stage3)–>>stages4(transiton3–>stage4)–>>final_layer
2)stages1与resnet50第一个res2相同,包括4个bottleneck
3)stages2,3,4分别拥有1,4,3个exchange blocks;每个exchange blocks也包含4个bottleneck构成
4)从上到下,每个stages分辨率减半,通道增倍,文中提到HRNet-W32和HRNet-W48,指的是这些stage的通道数不同,但结构相同
5)从整体上看,与resnet50极为相似,但多了些过渡单元transition和并行子网络,以及exchange需要的操作
3 Experiments
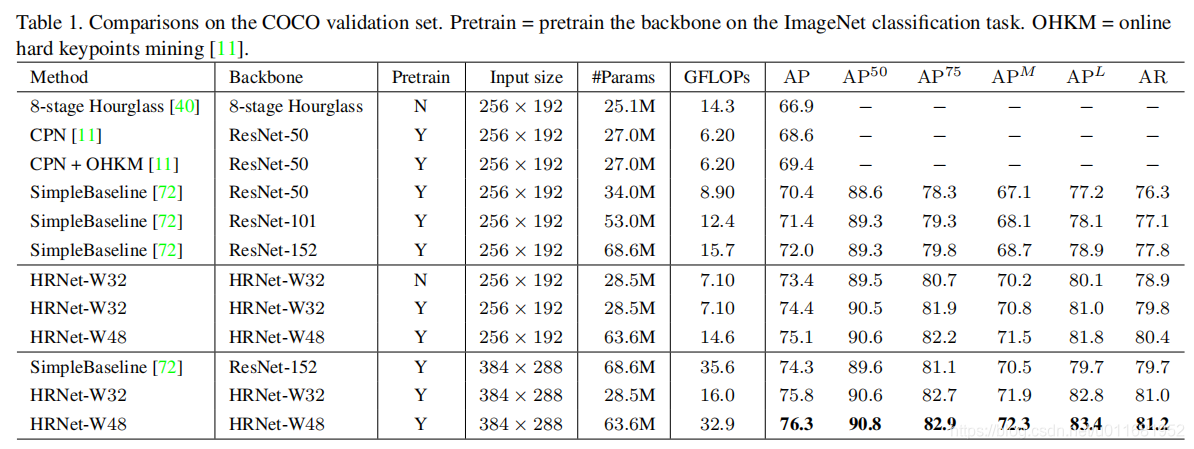
1)采用ImageNet预训练,在COCO validation set上对比
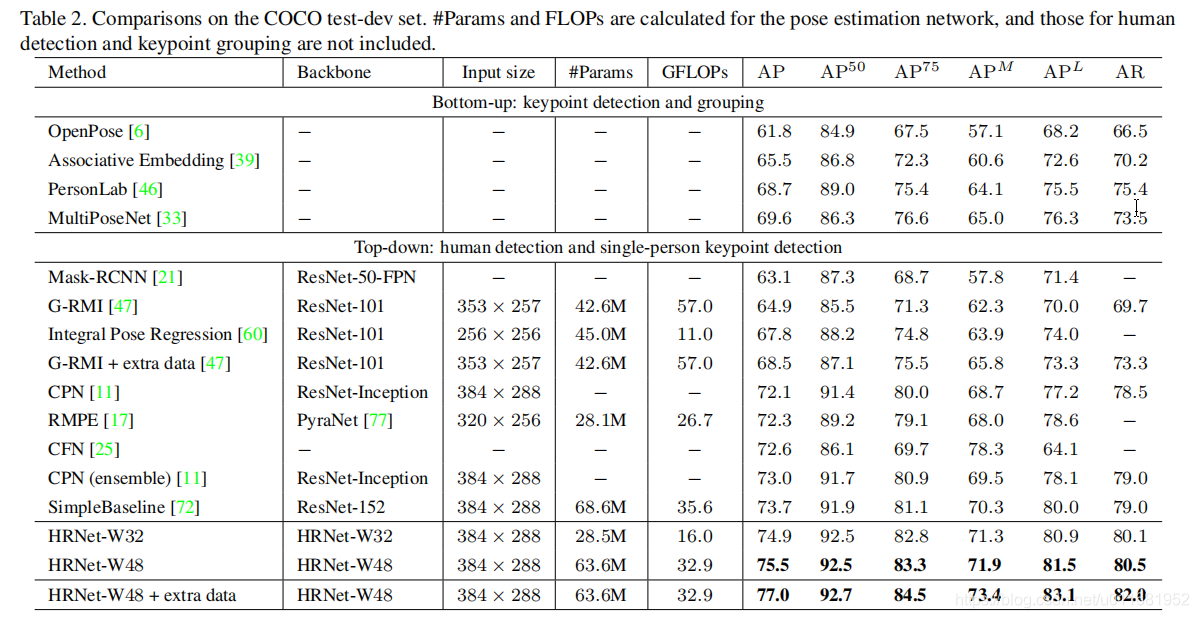
2)在COCO test set上对比
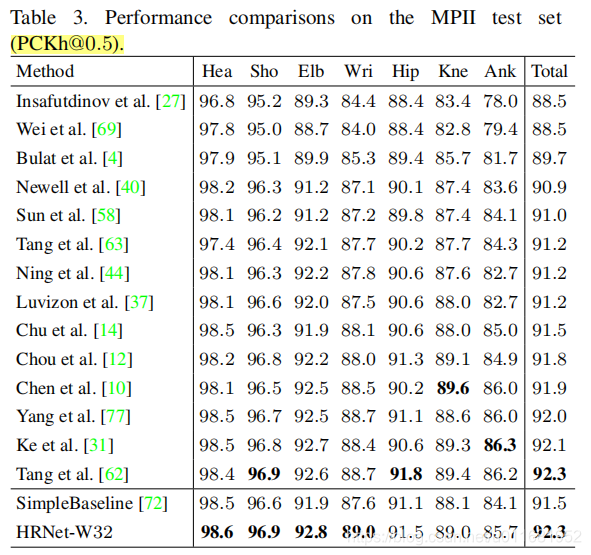
3)在MPII test set上对比
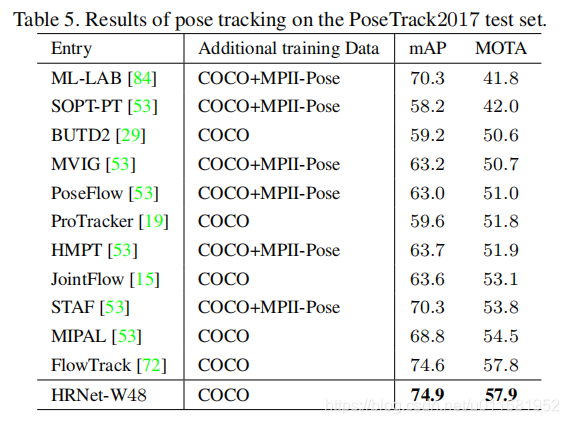
4)在PoseTrack2017 test set上的姿态跟踪对比
5)效果

4 延展
除了估计姿势,这个方法也可以做语义分割,人脸对齐,物体检测等
