文章目录
-
- 一、Harmonic Block
- 二、Spatial Group-wise Enhance
- 三、Residual SRM
- 四、DiCE Unit
- 五、Dimension-wise Fusion
- 六、Strided EESP
- 七、Compact Global Descriptor
- 八、OSA (identity mapping + eSE)
- 九、Effective Squeeze-and-Excitation Block
- 十、Elastic ResNeXt Block
- 十一、Depthwise Fire Module
- 十二、CornerNet-Squeeze Hourglass Module
- 十三、Contextual Residual Aggregation
- 十四、Content-Conditioned Style Encoder
- 十五、Hierarchical-Split Block
- 十六、Attentional Liquid Warping Block
- 十七、Patch Merger Module
- 十八、Global Local Attention Module
一、Harmonic Block
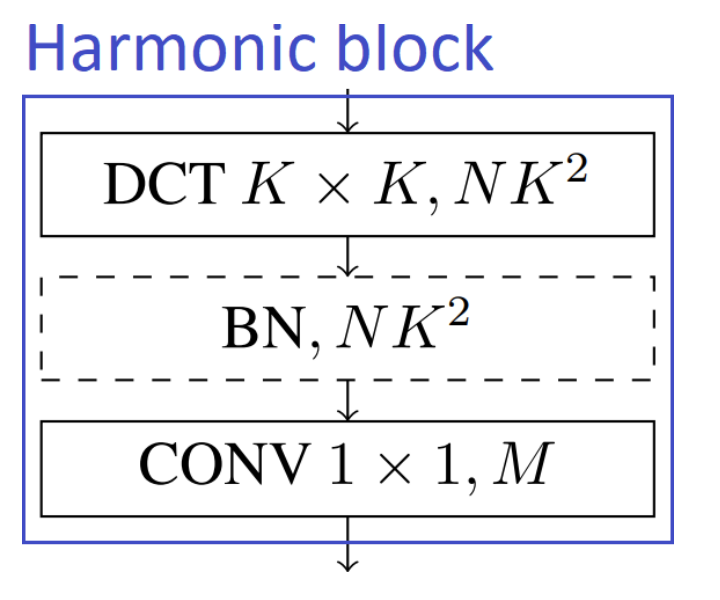
谐波块是一种利用离散余弦变换 (DCT) 滤波器的图像模型组件。 卷积神经网络 (CNN) 学习滤波器以捕获特征空间中的局部相关模式。 相比之下,DCT具有预设的频谱滤波器,可以更好地压缩信息(由于频谱域中存在冗余)。
DCT 已成功用于 JPEG 编码,将图像块转换为频谱表示,从而用少量系数捕获最多信息。 谐波模块学习如何以最佳方式组合每一层的频谱系数,以生成固定大小的表示形式,该表示形式定义为 DCT 滤波器响应的加权和。 DCT 滤波器的使用可以解决模型压缩的任务。
二、Spatial Group-wise Enhance
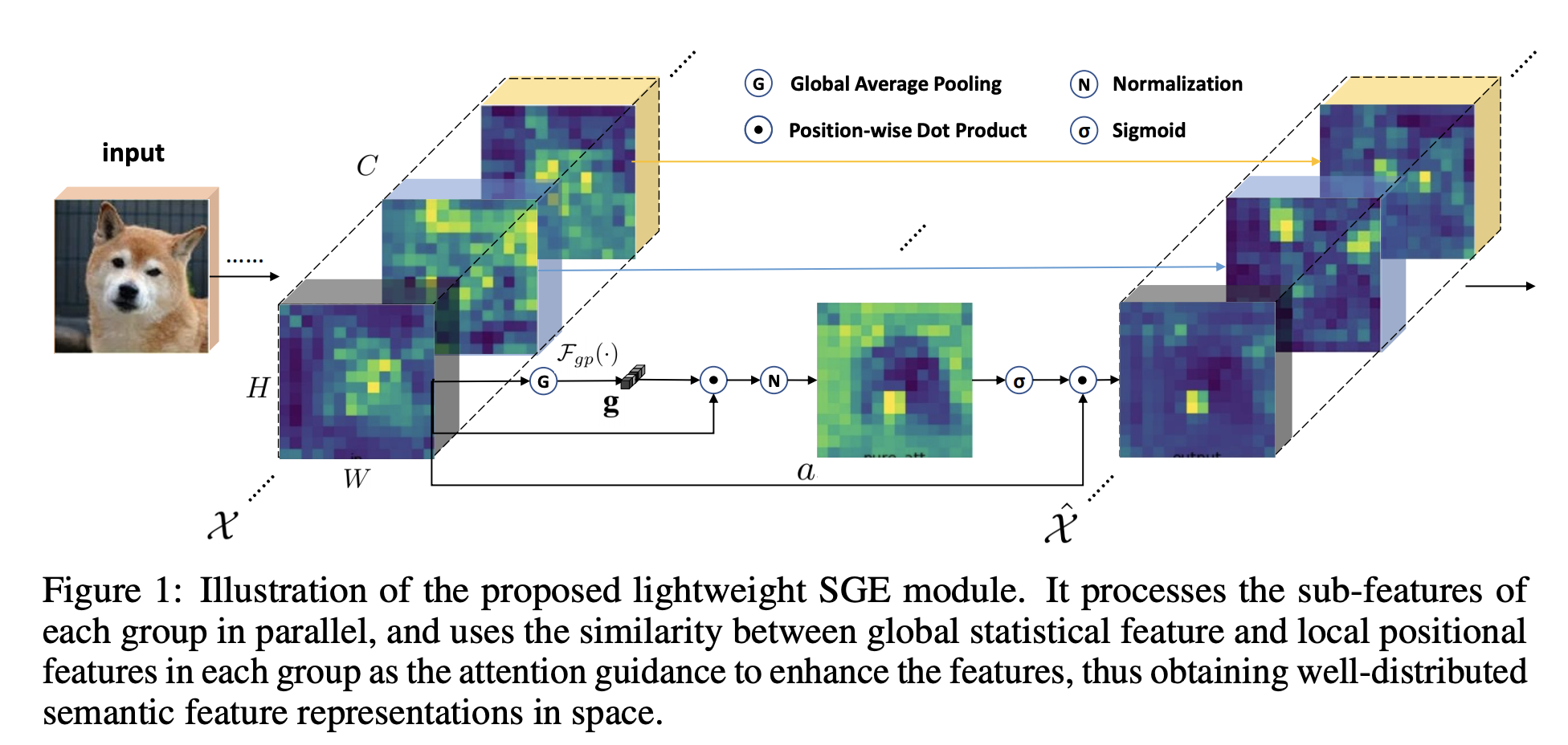
Spatial Group-wise Enhance 是卷积神经网络的一个模块,它可以通过为每个语义组中的每个空间位置生成注意因子来调整每个子特征的重要性,从而使每个单独的组都可以自主增强其学习到的表达并抑制可能的表达 噪音
在每个特征组内,我们通过使用注意掩模在所有位置上缩放特征向量,在每个特征组内建模空间增强机制。 该注意掩模旨在抑制可能的噪声并突出显示正确的语义特征区域。 与其他流行的注意力方法不同,它利用全局统计特征与每个位置的局部统计特征之间的相似性作为注意力掩模的生成源。
三、Residual SRM
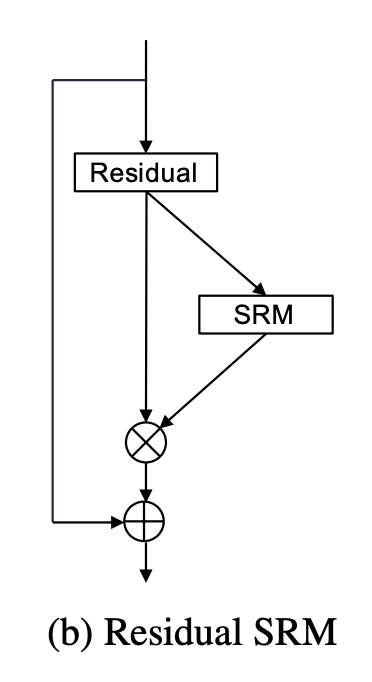
残差 SRM 是卷积神经网络的一个模块,它在残差块状结构中使用基于样式的重新校准模块。 基于样式的重新校准模块(SRM)通过利用中间特征图的样式来自适应地重新校准中间特征图。
四、DiCE Unit
DiCE 单元是使用逐维卷积和逐维融合构建的图像模型块。 维度卷积在输入张量的每个维度上应用轻量级卷积滤波,而维度融合有效地组合了这些维度表示; 允许 DiCE 单元有效地编码输入张量中包含的空间和通道信息。

标准卷积同时编码空间和通道信息,但它们的计算成本很高。 为了提高标准卷积的效率,引入了可分离卷积,其中空间和通道信息分别使用深度卷积和点卷积分别编码。 尽管这种分解是有效的,但它给逐点卷积带来了巨大的计算负担,并使它们成为计算瓶颈。
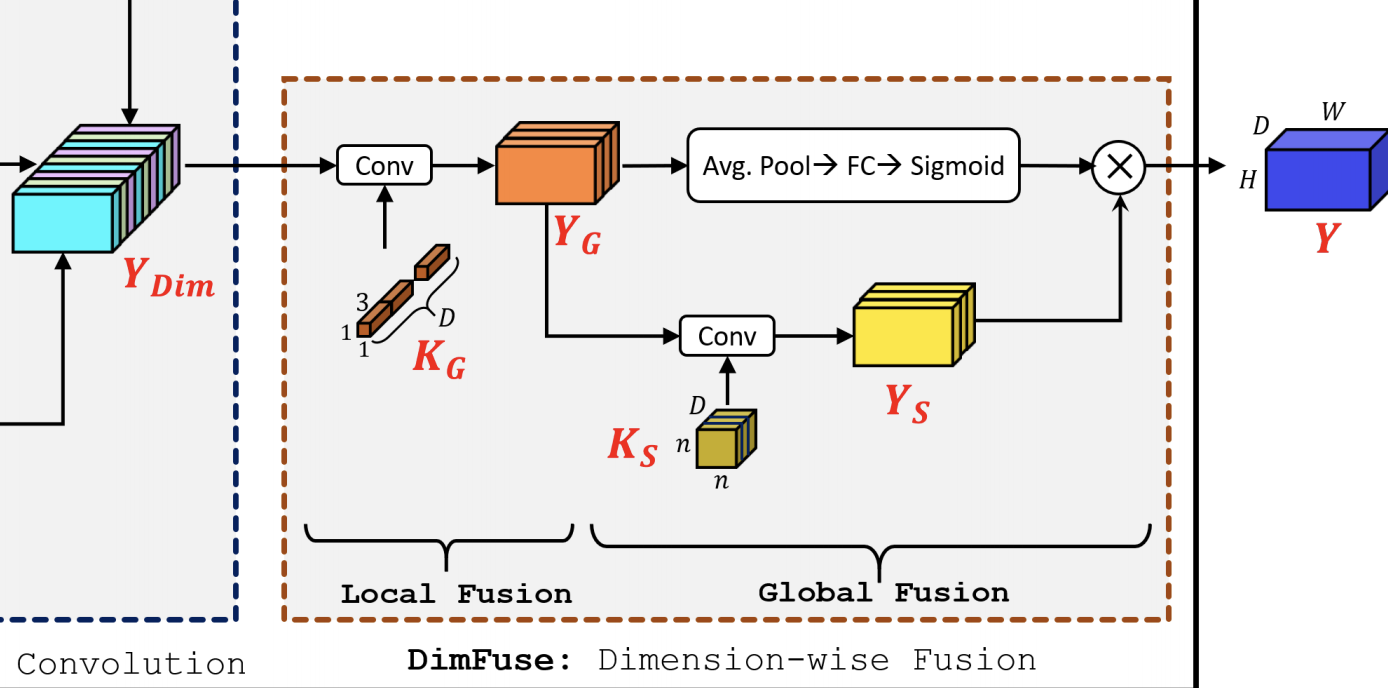
DiCE 单元利用维度卷积来独立编码深度、宽度和高度信息。 维度卷积对来自输入张量的不同维度的局部信息进行编码,但不捕获全局信息。 一种方法是逐点卷积,但计算量大,因此维度融合将逐点卷积分解为两个步骤:(1) 局部融合和 (2) 全局融合。
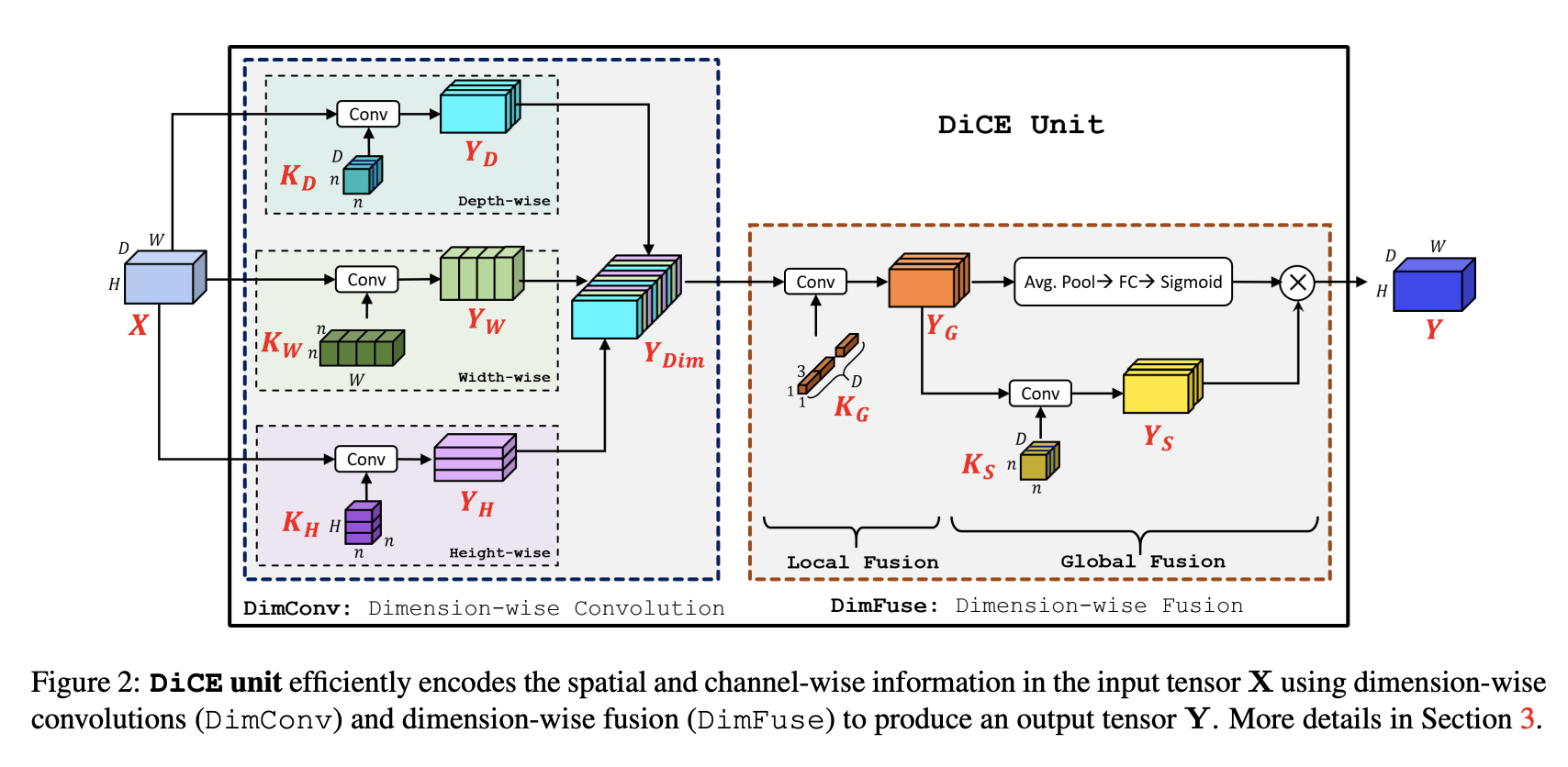
五、Dimension-wise Fusion

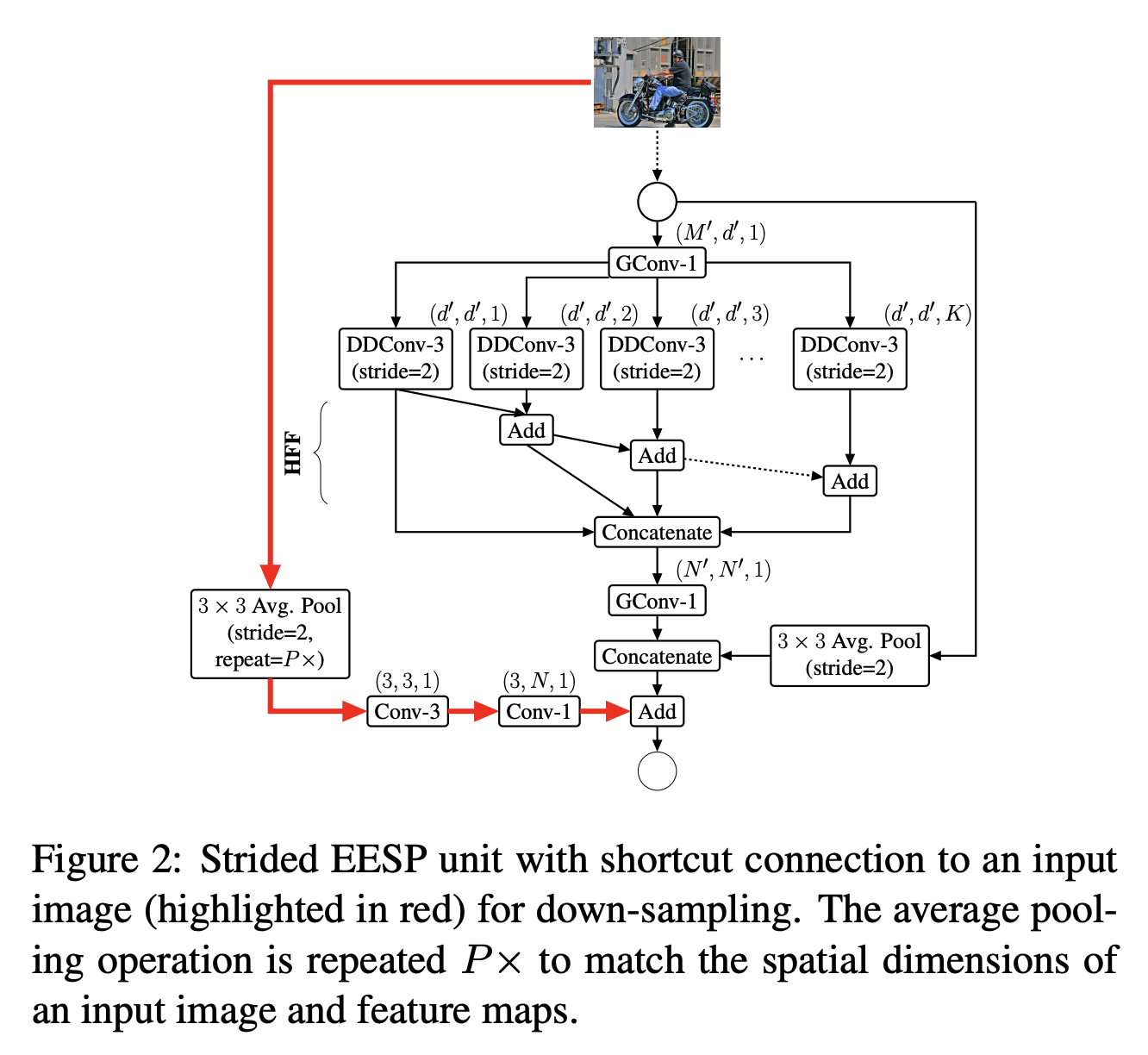
六、Strided EESP
Strided EESP 单元基于 EESP 单元,但经过修改以在多个尺度上更有效地学习表示。 深度扩张卷积被赋予步长,添加平均池化操作而不是恒等连接,并且元素级加法操作被连接操作取代,这有助于有效地扩展特征图的维度。
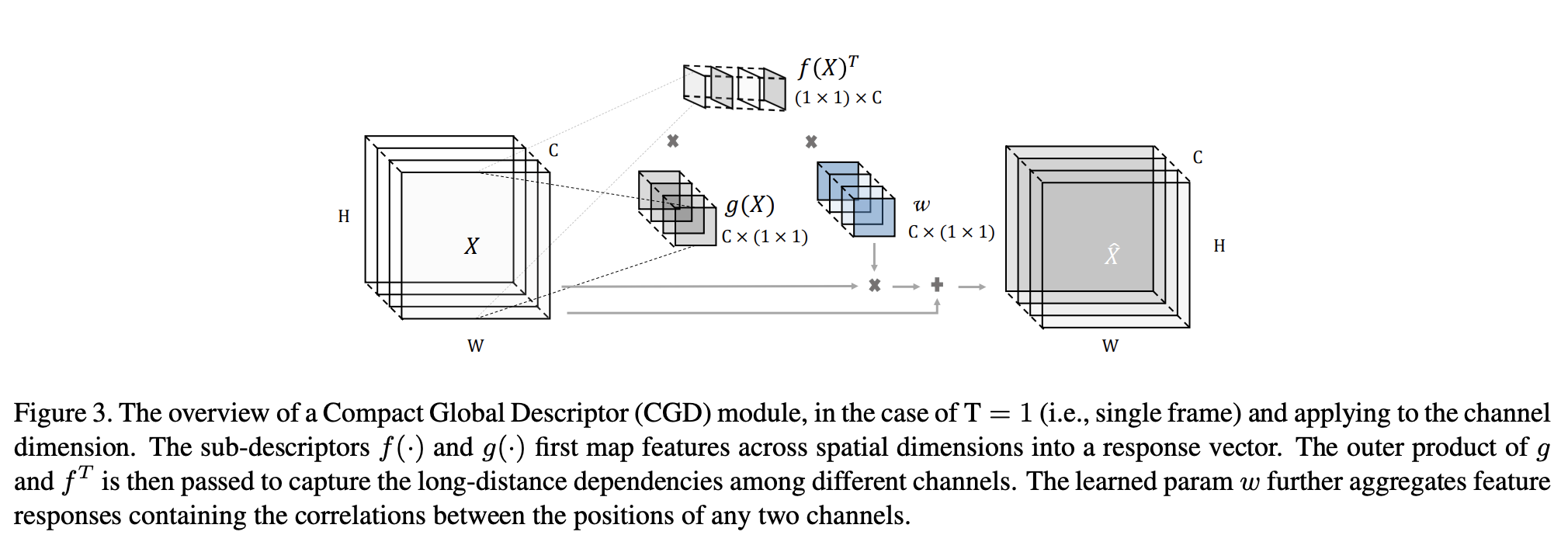
七、Compact Global Descriptor
紧凑全局描述符是一个图像模型块,用于对不同维度(例如通道、帧)的位置之间的交互进行建模。 该描述符使后续的卷积能够访问信息丰富的全局特征。 这是一种注意力形式。
八、OSA (identity mapping + eSE)
具有身份映射和 eSE 的单次聚合是一种图像模型块,它通过残差连接和有效的挤压和激励块扩展了单次聚合。 它被提议作为 VoVNetV2 CNN 架构的一部分。
该模块向 OSA 模块添加了恒等映射 - 输入路径连接到 OSA 模块的末端,该模块能够像 ResNet 一样在每个阶段以端到端的方式反向传播每个 OSA 模块的梯度。 此外,还使用了一种通道注意模块 - 有效的挤压激励 - 类似于常规的挤压和激励,但仅使用一个 FC 层C通道而不是两个 FC,无需通道降维,从而保留通道信息。

九、Effective Squeeze-and-Excitation Block
有效的挤压和激励模块是一种基于挤压和激励的图像模型模块,不同之处在于少使用了一个FC层。 作者指出 SE 模块有一个局限性:由于降维导致通道信息丢失。 为了避免高模型复杂性负担,SE模块的两个FC层需要减少通道维度。

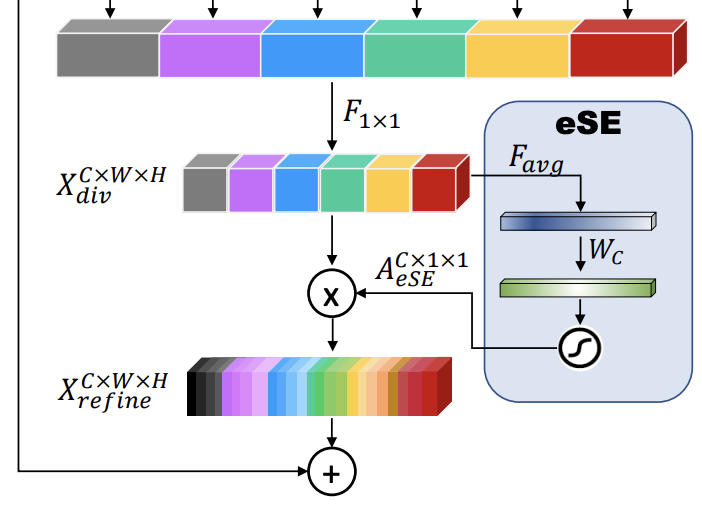
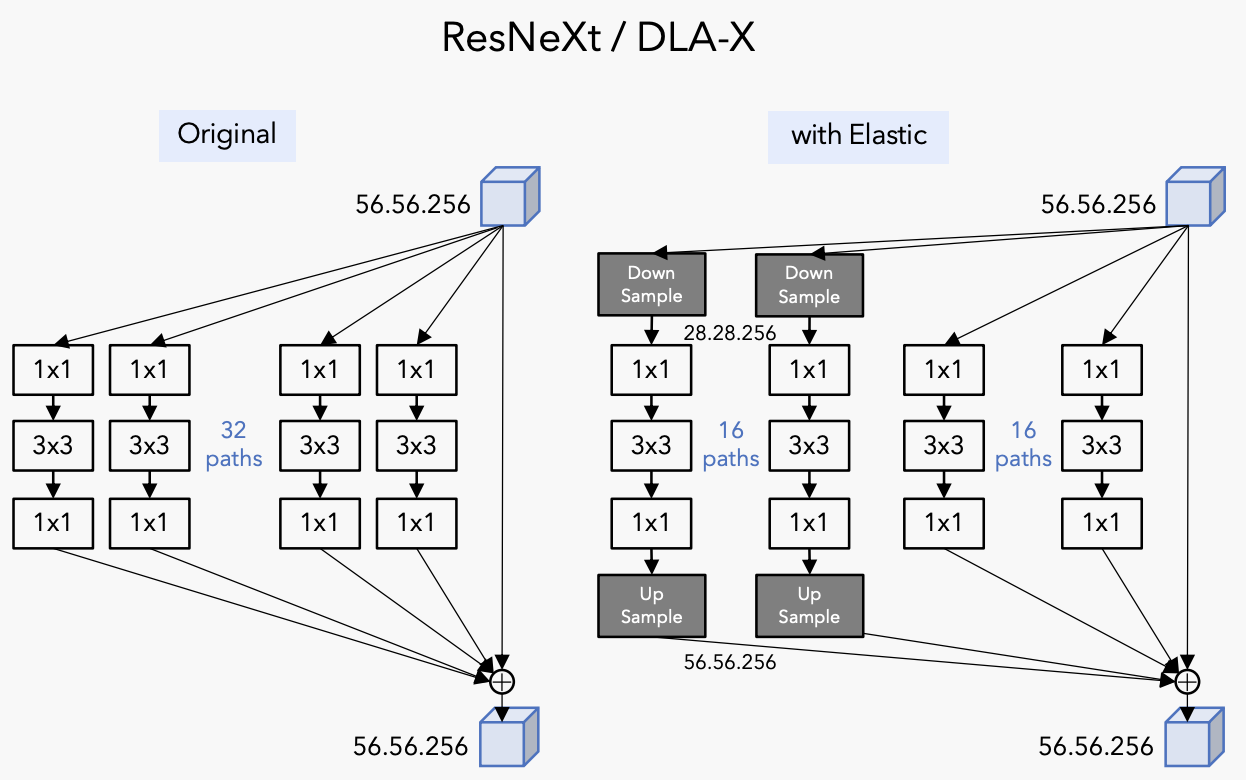
十、Elastic ResNeXt Block
Elastic ResNeXt Block 是 ResNeXt Block 的修改版,它在每一层的并行分支中添加下采样和上采样。 之所以称为“弹性”,是因为网络中的每一层都可以通过软策略灵活选择最佳规模。
十一、Depthwise Fire Module
Depthwise Fire Module 是对具有深度可分离卷积的 Fire Module 的修改,以提高推理时间性能。 它在 CornerNet-Lite 架构中用于对象检测。

十二、CornerNet-Squeeze Hourglass Module
CornerNet-Squeeze Hourglass Module 是 CornerNet-Lite 中使用的图像模型块,它基于沙漏模块,但使用修改后的火模块而不是残差块。 除了替换残差块之外,进一步的修改包括:通过在沙漏模块之前添加一个下采样层来降低沙漏模块的最大特征图分辨率,在每个沙漏模块中删除一个下采样层,用1 x替换3 × 3滤波器 CornerNet 的预测模块中使用 1 个滤波器,最后用 4 × 4 核的转置卷积替换沙漏网络中的最近邻上采样。

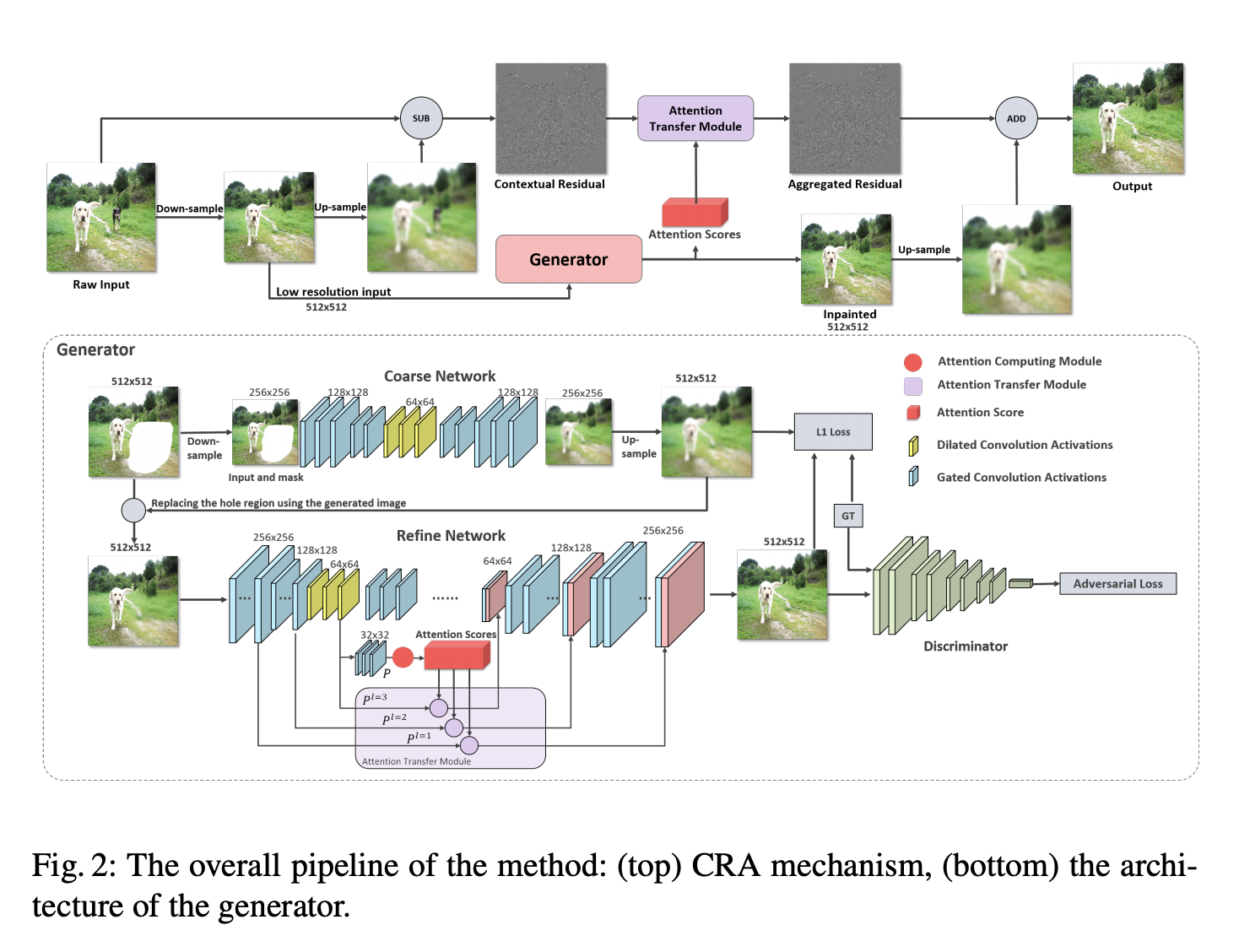
十三、Contextual Residual Aggregation
上下文残差聚合(CRA)是一个图像修复模块。 它可以通过加权聚合上下文补丁的残差来生成缺失内容的高频残差,因此只需要网络的低分辨率预测。 具体来说,它涉及一个神经网络来预测低分辨率的修复结果并对它进行上采样以产生大的模糊图像。 然后,我们通过聚合上下文补丁的加权高频残差来生成孔内补丁的高频残差。 最后,我们将聚合残差添加到大模糊图像中以获得清晰的结果。
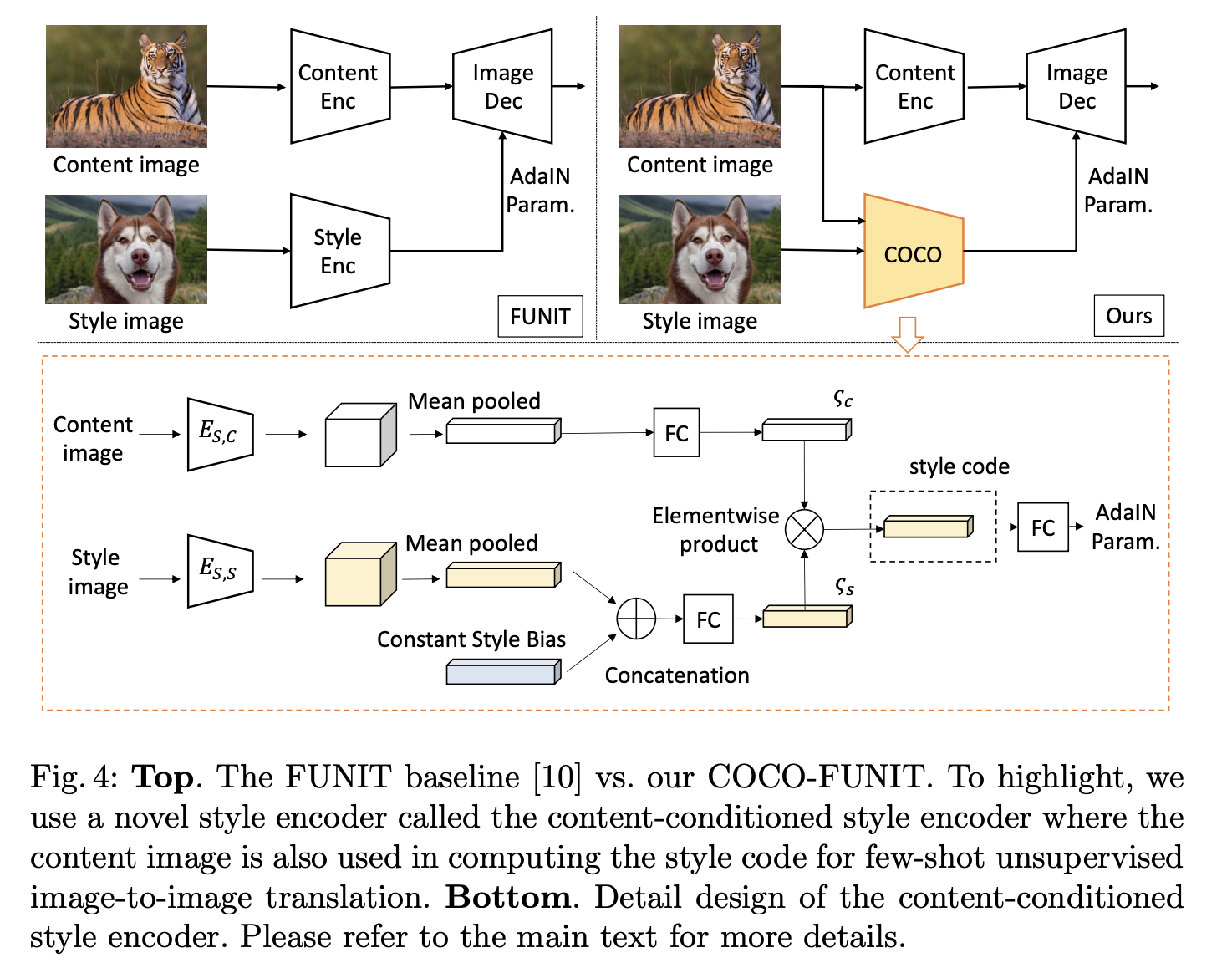
十四、Content-Conditioned Style Encoder
内容条件样式编码器(COCO)是一种样式编码器,用于 COCO-FUNIT 架构中图像到图像的转换。 与 FUNIT 中的样式编码器不同,COCO 将内容和样式图像作为输入。 通过这种内容调节方案,我们在学习过程中创建直接反馈路径,让内容图像影响样式代码的计算方式。 它还有助于减少样式图像对提取样式代码的直接影响。

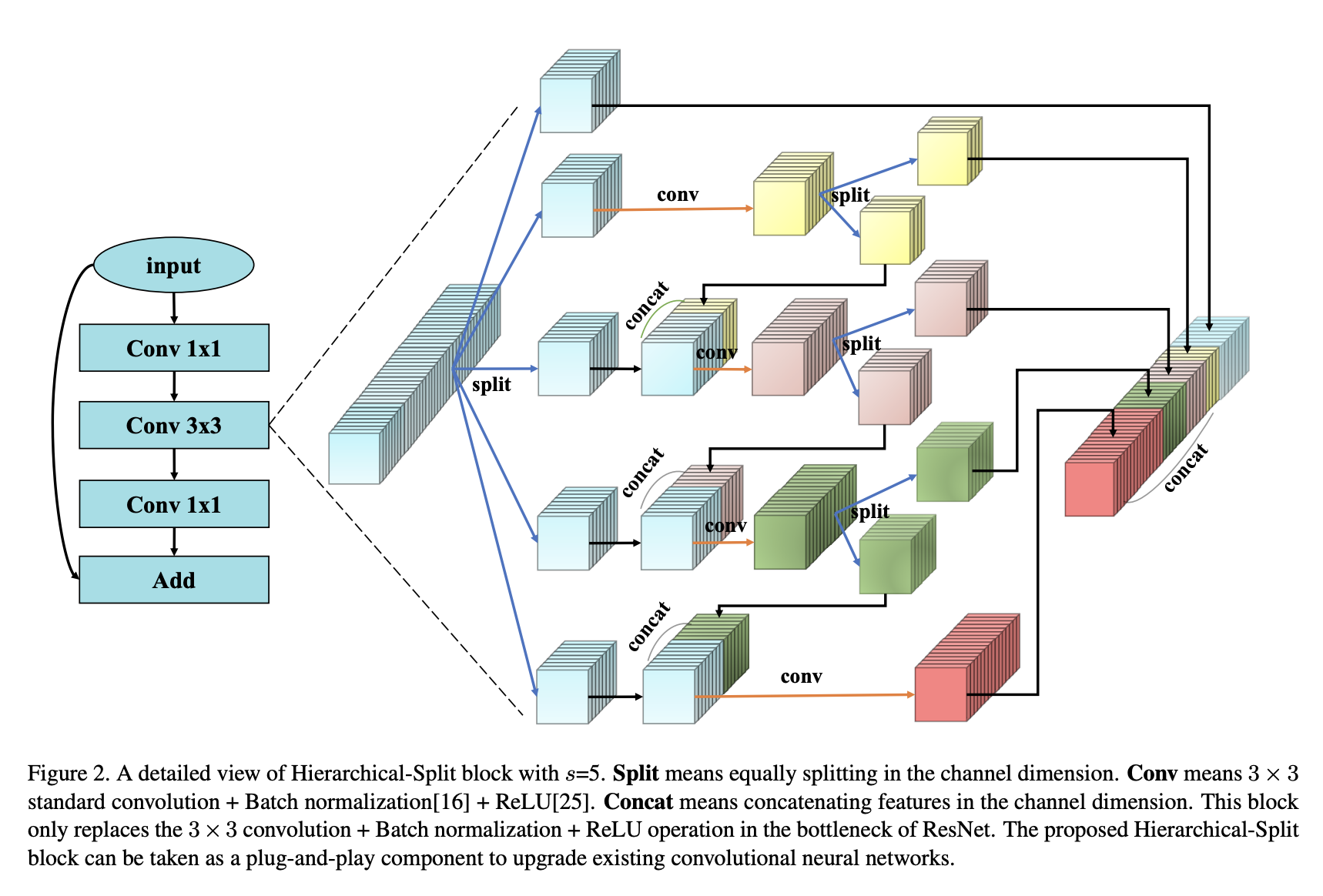
十五、Hierarchical-Split Block
分层分割块是用于多尺度特征表示的表示块。 它在一个残差块内包含许多分层分割和串联连接。
具体来说,深度神经网络中的普通特征图被分为s组,每个组都有w渠道。 如图所示,只有第一组过滤器可以直接连接到下一层。 第二组特征图被发送到卷积 3 × 3 3 \times 3 3×3首先使用滤波器提取特征,然后将输出特征图在通道维度上分为两个子组。 一个子组的特征图直接连接到下一层,而另一个子组则与通道维度中的下一组输入特征图连接。 连接的特征图由一组操作 3 × 3 3 \times 3 3×3卷积滤波器。 这个过程重复几次,直到处理完其余的输入特征图。 最后,将所有输入组的特征图连接起来并发送到另一层 1 × 1 1 \times 1 1×1过滤器来重建特征。
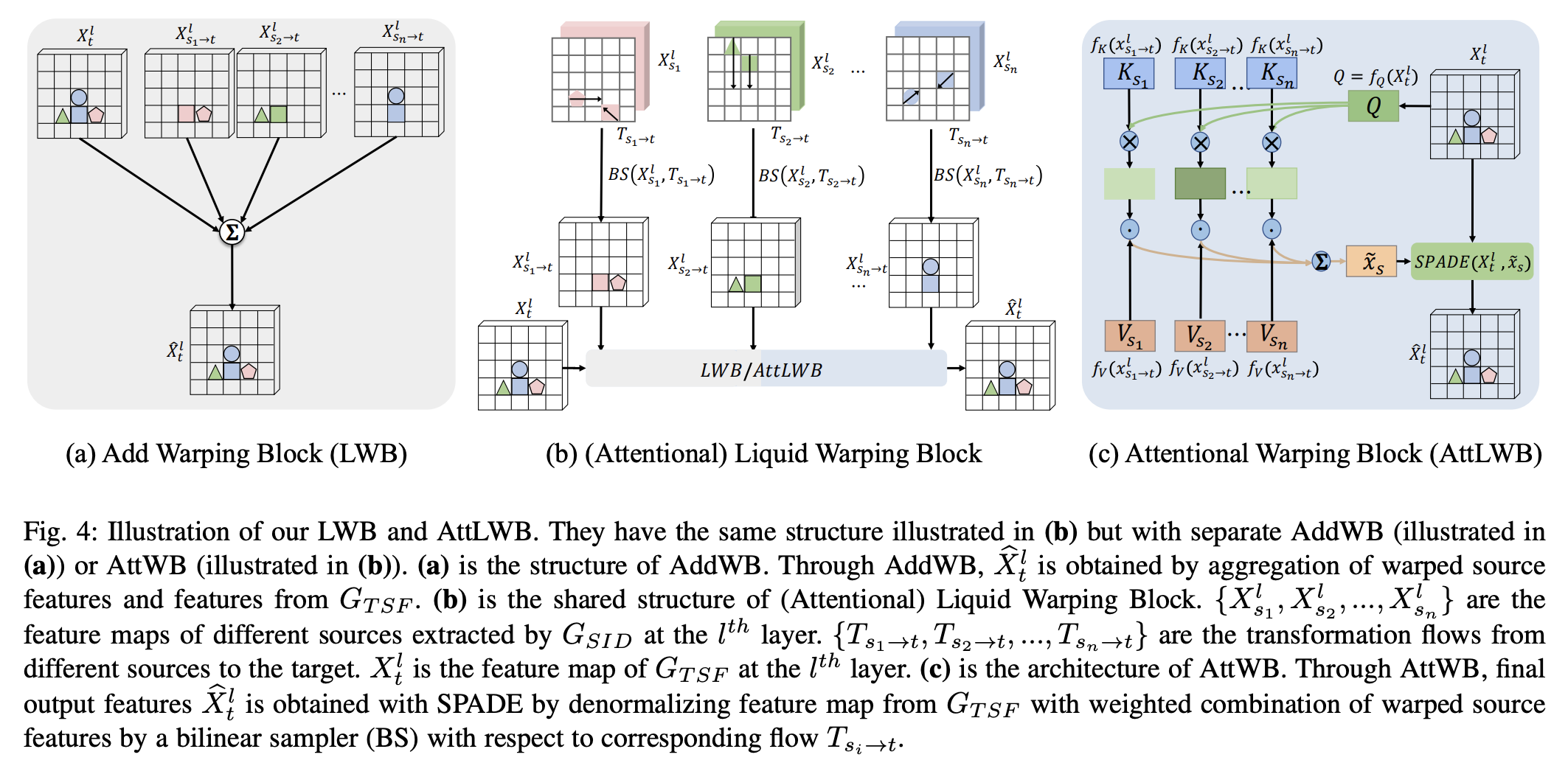
十六、Attentional Liquid Warping Block
Attentional Liquid Warping Block(AttLWB)是一个用于人类图像合成 GAN 的模块,它将图像和特征空间中的源信息(例如纹理、风格、颜色和面部身份)传播到合成参考。 它首先学习所有多源特征之间全局特征的相似性,然后通过学习到的相似性与特征空间中的多源的线性组合来融合多源特征。 最后,为了更好地将源标识(样式、颜色和纹理)传播到全局流中,通过空间自适应标准化(SPADE)将融合的源特征扭曲到全局流。
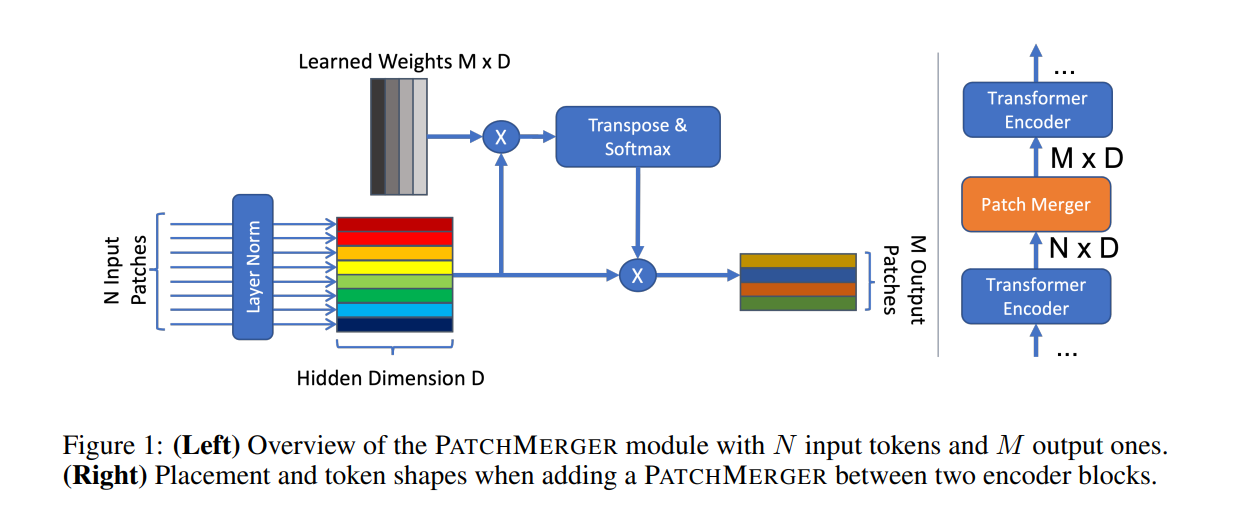
十七、Patch Merger Module
PatchMerger 是 Vision Transformers 的一个模块,可减少传递到每个单独 Transformer 编码器块的令牌/补丁数量,同时保持性能并减少计算量。 PatchMerger 通过形状为 M 的输出 patch × D 的可学习权重矩阵,对形状为 N 个 patch × D 维度的输入进行线性变换。这会生成 M 个分数,其中对每个分数应用 Softmax 函数。 所得输出的形状为 M × N,与原始输入相乘,得到形状为 M × D 的输出。
从数学上来说:
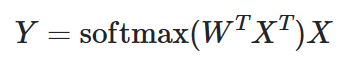
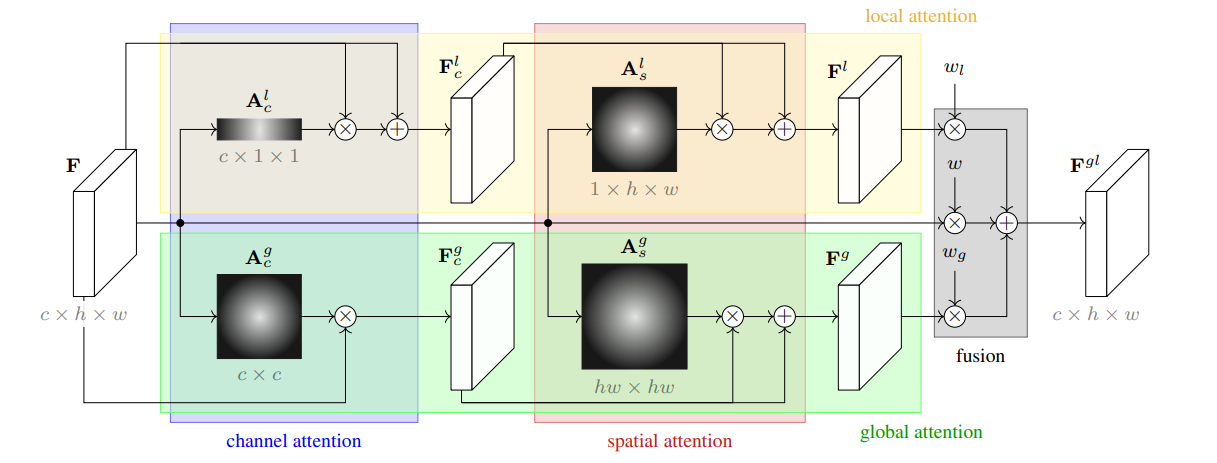
十八、Global Local Attention Module
全局局部注意模块(GLAM)是一个图像模型块,它局部关注特征图的通道和空间维度,并且还全局关注特征图的通道和空间维度。 然后通过加权和(具有可学习的权重)融合局部参与特征图、全局参与特征图和原始特征图,以获得最终特征图。