对象检测模型是用于执行对象检测任务的体系结构。 您可以在下面找到不断更新的对象检测模型列表。
文章目录
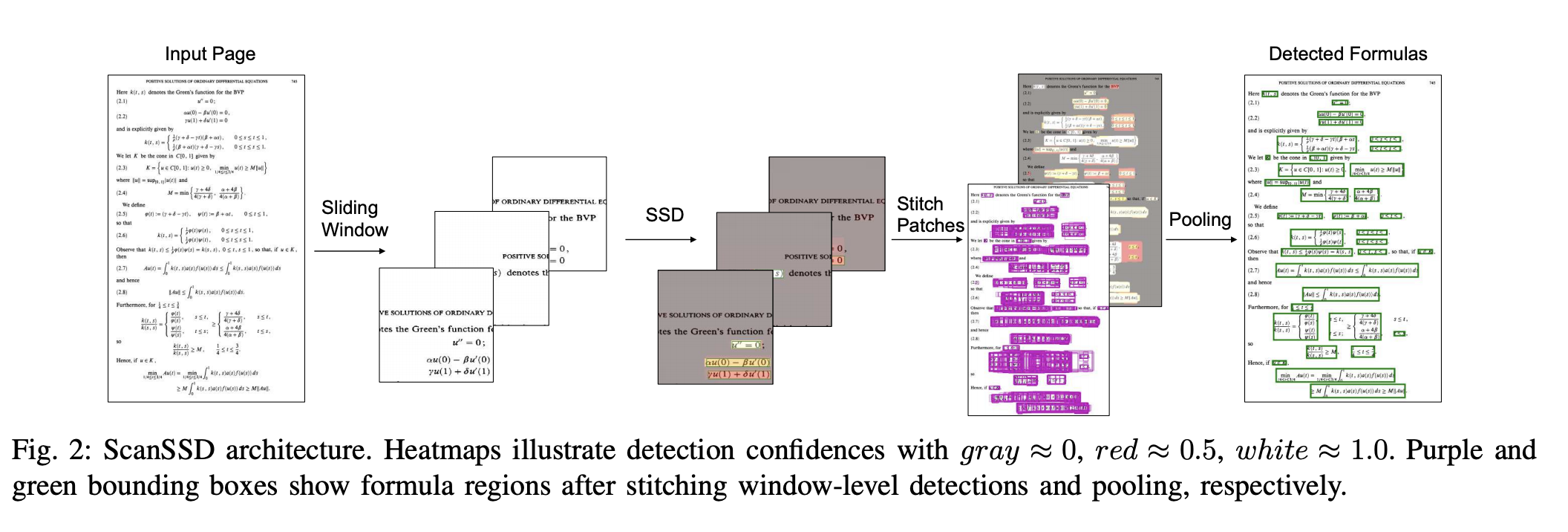
一、 ScanSSD
ScanSSD 是一种单次检测器 (SSD),用于定位偏离文本并嵌入文本行的数学公式。 它仅使用视觉特征进行检测:不使用布局、字体或字符标签等格式或排版信息。 给定 600 dpi 文档页面图像,单次检测器 (SSD) 使用滑动窗口在多个尺度上定位公式,然后汇集候选检测以获得页面级结果。
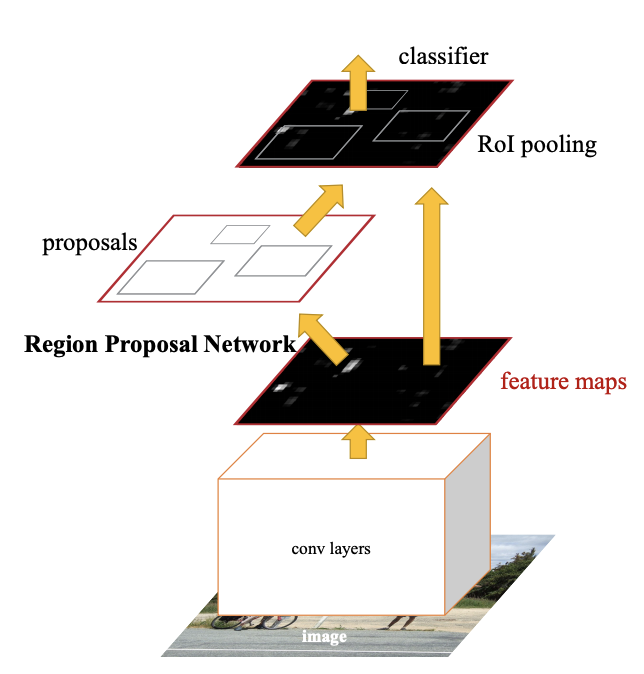
二、Faster R-CNN
Faster R-CNN 是一种目标检测模型,通过将区域提议网络 (RPN) 与 CNN 模型结合使用,在 Fast R-CNN 的基础上进行了改进。 RPN 与检测网络共享全图像卷积特征,从而实现几乎无成本的区域提议。 它是一个完全卷积网络,可同时预测每个位置的对象边界和对象性分数。 RPN 经过端到端训练以生成高质量的区域提案,Fast R-CNN 使用这些区域提案进行检测。 RPN 和 Fast R-CNN 通过共享它们的卷积特征合并成一个网络:RPN 组件告诉统一网络要往哪里看。
总体而言,Faster R-CNN 由两个模块组成。 第一个模块是提议区域的深度全卷积网络,第二个模块是使用提议区域的 Fast R-CNN 检测器。
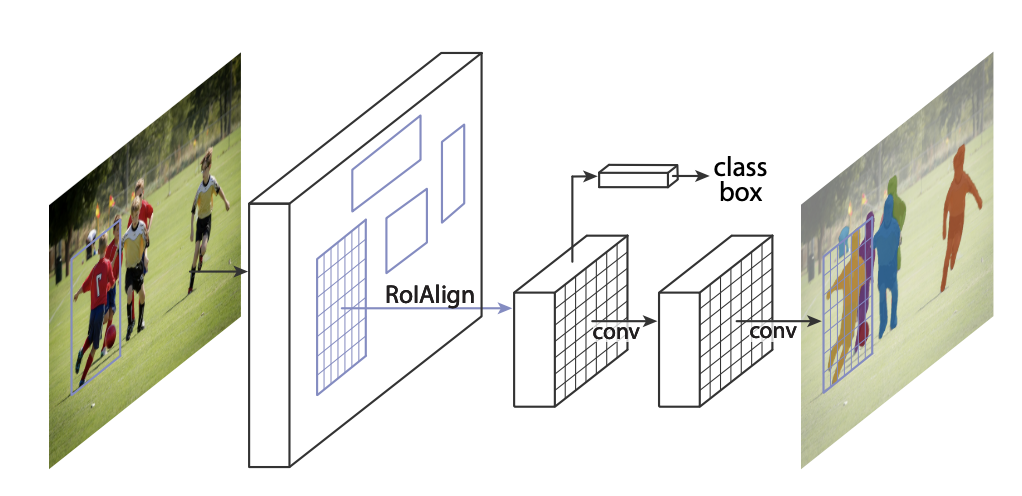
三、Mask R-CNN
Mask R-CNN 扩展了 Faster R-CNN 以解决实例分割任务。 它通过添加一个用于预测对象掩模的分支与用于边界框识别的现有分支并行来实现这一点。 原则上,Mask R-CNN 是 Faster R-CNN 的直观扩展,但正确构建 mask 分支对于获得良好结果至关重要。
最重要的是,Faster R-CNN 并不是为网络输入和输出之间的像素到像素对齐而设计的。 这在 RoIPool(处理实例的事实上的核心操作)如何执行粗空间量化以进行特征提取中显而易见。 为了修复未对齐问题,Mask R-CNN 使用了一个简单的无量化层,称为 RoIAlign,它忠实地保留了精确的空间位置。
其次,Mask R-CNN将掩模和类别预测解耦:它独立地为每个类别预测一个二元掩模,没有类别之间的竞争,并依赖网络的RoI分类分支来预测类别。 相比之下,FCN 通常执行逐像素多类分类,将分割和分类结合起来。
四、YOLOv3
YOLOv3 是一种实时、单阶段目标检测模型,它建立在 YOLOv2 的基础上,并进行了多项改进。 改进包括使用新的骨干网络,即利用残差连接的 Darknet-53,或者用作者的话说,“那些新奇的残差网络东西”,以及对边界框预测步骤的一些改进,以及使用三个 从中提取特征的不同尺度(类似于 FPN)。
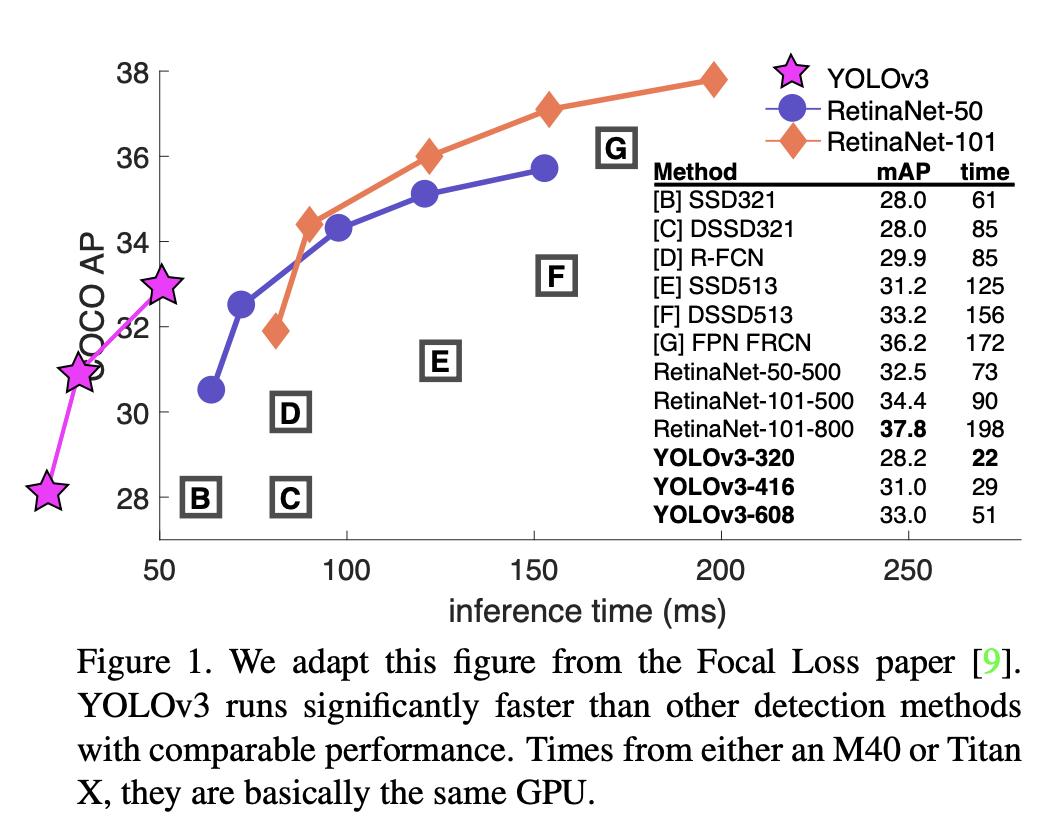
五、RetinaNet
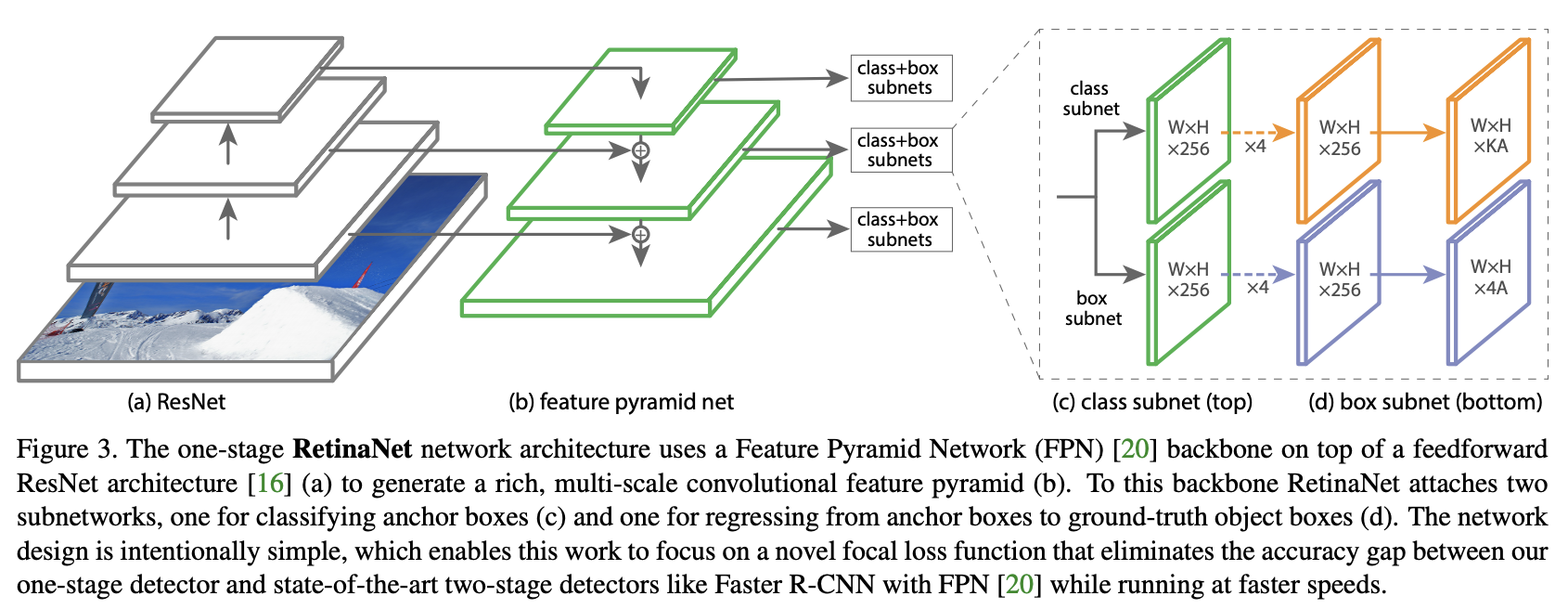
RetinaNet 是一种单阶段目标检测模型,利用焦点损失函数来解决训练期间的类别不平衡问题。 焦点损失对交叉熵损失应用了一个调节项,以便将学习集中在困难的负面例子上。 RetinaNet 是一个单一的、统一的网络,由一个主干网络和两个特定于任务的子网络组成。 主干网负责计算整个输入图像上的卷积特征图,并且是一个现成的卷积网络。 第一个子网对主干网的输出执行卷积对象分类; 第二个子网执行卷积边界框回归。 这两个子网络具有作者专门针对单阶段密集检测提出的简单设计。
通过与两级物体检测器的比较,我们可以看到焦点损失的动机。 这里,类不平衡是通过两阶段级联和采样启发式解决的。 提议阶段(例如,选择性搜索、EdgeBoxes、DeepMask、RPN)迅速将候选对象位置的数量缩小到较小的数量(例如,1-2k),过滤掉大多数背景样本。 在第二分类阶段,执行采样启发法,例如固定前景与背景比率或在线硬示例挖掘(OHEM),以维持前景和背景之间的可管理平衡。
相比之下,单级检测器必须处理在图像上定期采样的一组更大的候选对象位置。 为了解决这个问题,RetinaNet 使用焦点损失函数,这是一种动态缩放的交叉熵损失,其中缩放因子随着正确类别的置信度增加而衰减到零。 直观地说,这个比例因子可以在训练过程中自动降低简单示例的贡献,并快速将模型集中在困难示例上。

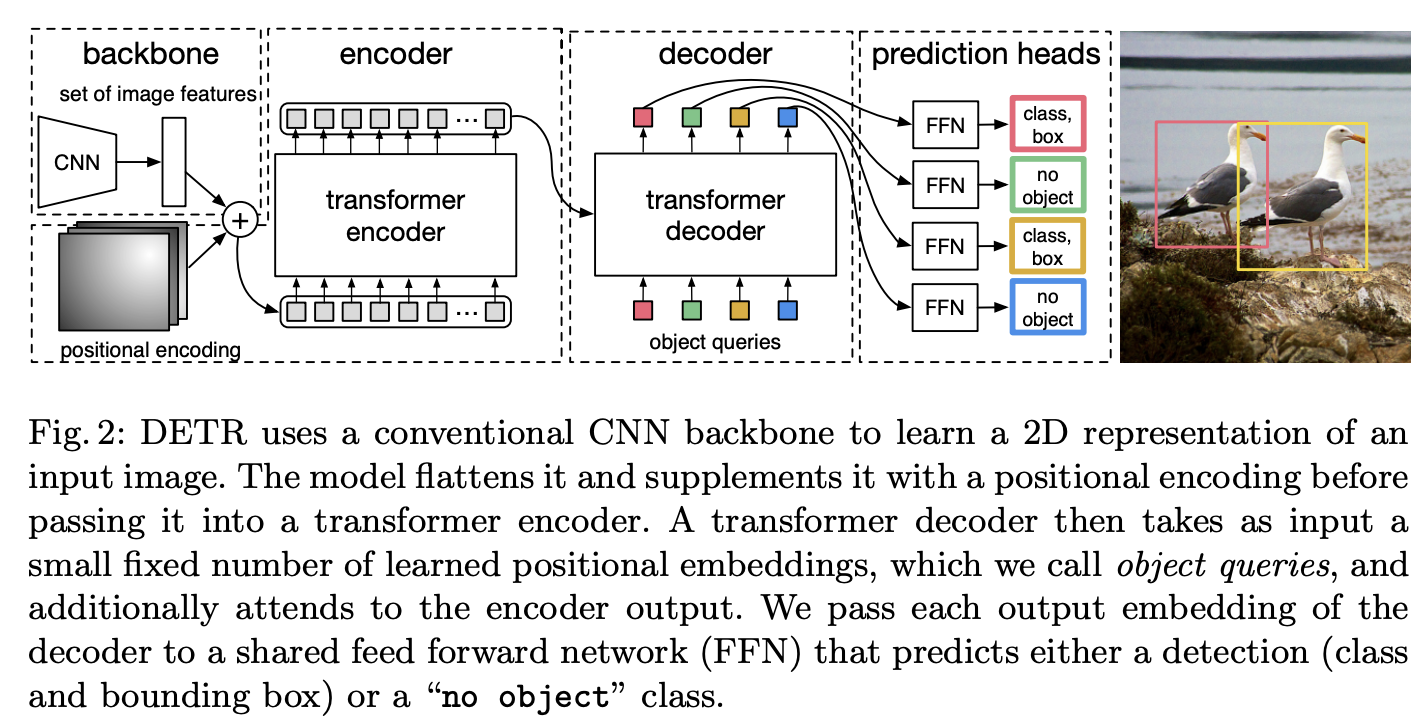
六、Detection Transformer
Detr(即检测变压器)是一种基于集合的目标检测器,在卷积主干之上使用变压器。 它使用传统的 CNN 主干来学习输入图像的 2D 表示。 该模型将其展平并用位置编码对其进行补充,然后将其传递到变压器编码器。 然后,变压器解码器将少量固定数量的学习位置嵌入(我们称之为对象查询)作为输入,并另外关注编码器输出。 我们将解码器的每个输出嵌入传递到共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。
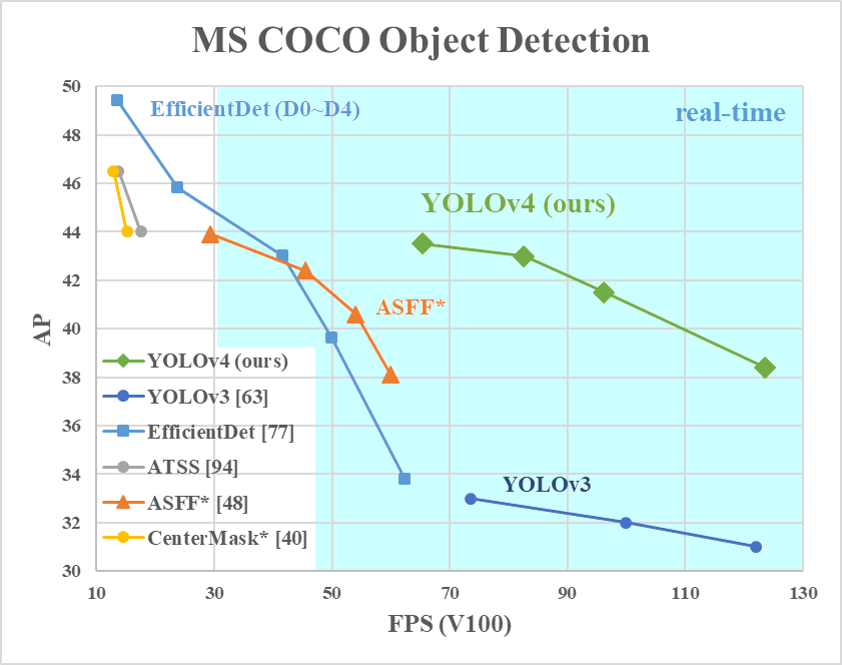
七、YOLOv4
YOLOv4 是一种单阶段目标检测模型,它在 YOLOv3 的基础上进行了改进,并在文献中引入了一些技巧和模块。 下面的组件部分详细介绍了所使用的技巧和模块。
八、FCOS
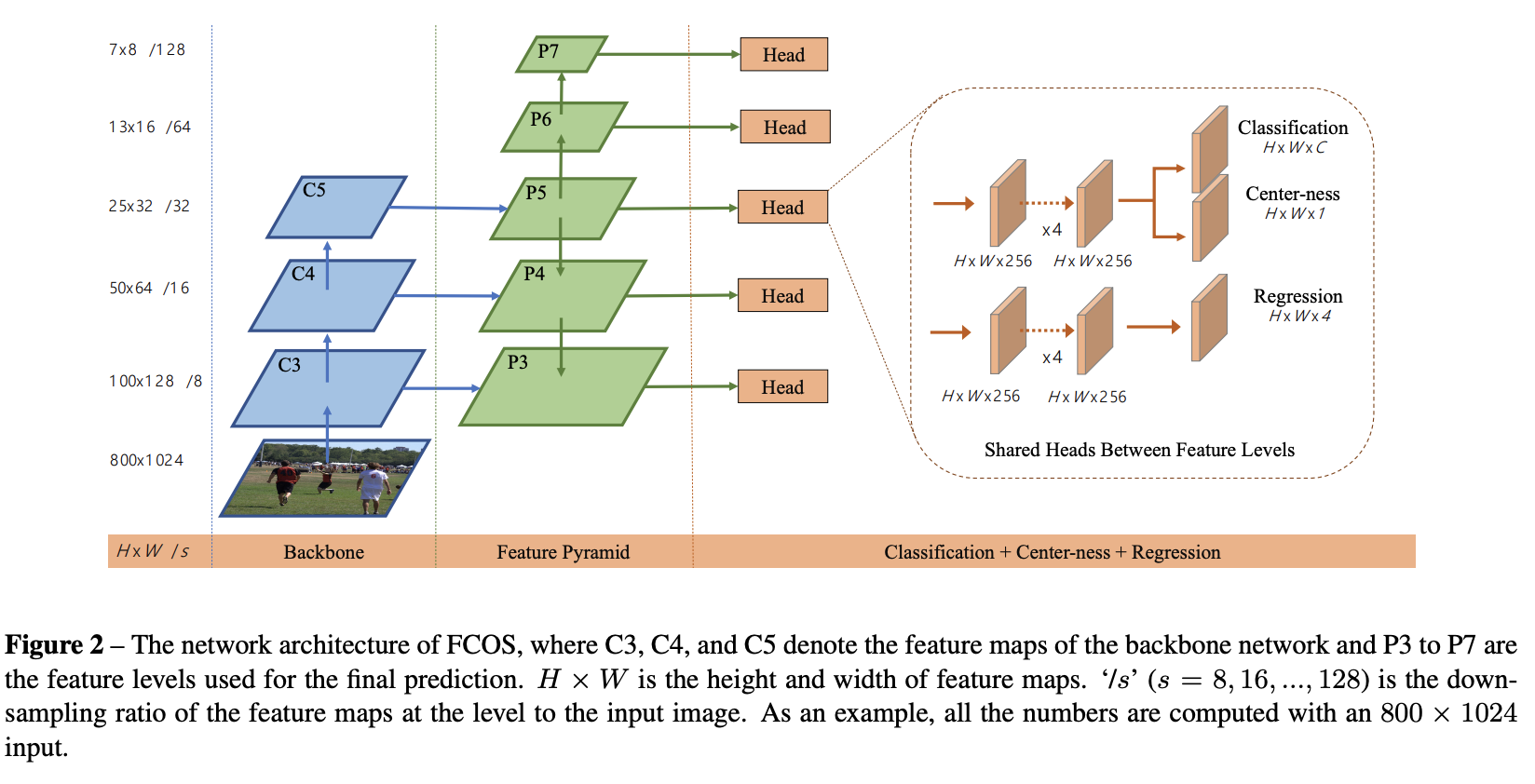
FCOS 是一种无锚框、无提议的单阶段目标检测模型。 通过消除预定义的锚框集,FCOS 避免了与锚框相关的计算,例如在训练期间计算重叠。 它还避免了与锚框相关的所有超参数,这些超参数通常对最终的检测性能非常敏感。
九、YOLOv2
YOLOv2,或YOLO9000,是一种单阶段实时目标检测模型。 它在多个方面对 YOLOv1 进行了改进,包括使用 Darknet-19 作为主干、批量归一化、使用高分辨率分类器以及使用锚框来预测边界框等等。

十、Fast R-CNN
Fast R-CNN 是一种目标检测模型,在许多方面对其前身 R-CNN 进行了改进。 Fast R-CNN 不是为每个感兴趣区域独立提取 CNN 特征,而是将它们聚合到图像上的单个前向传递中; 即来自同一图像的感兴趣区域在前向和后向传递中共享计算和内存。
十一、CenterNet
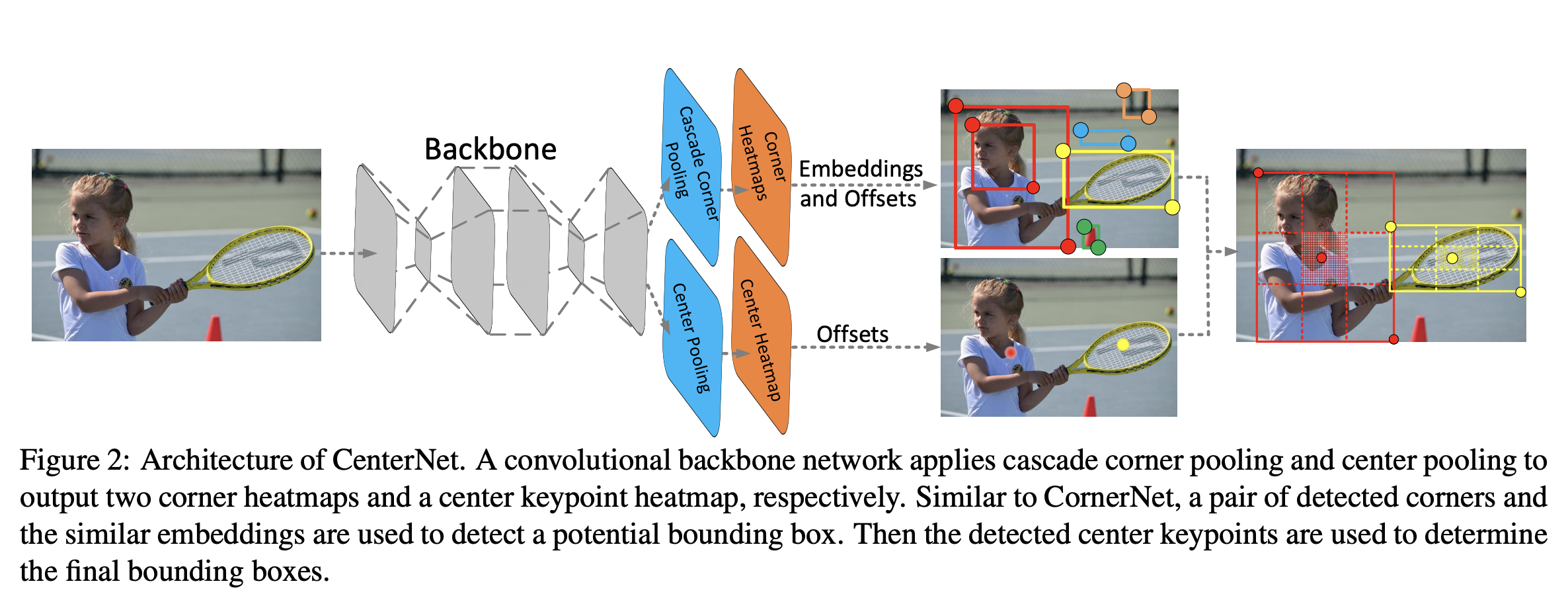
CenterNet 是一种单级对象检测器,它将每个对象检测为三元组,而不是一对关键点。 它利用两个定制模块,即级联角池化和中心池化,分别起到丰富左上角和右下角收集的信息并在中心区域提供更多可识别信息的作用。 直觉是,如果预测的边界框与真实框具有较高的 IoU,则其中心区域的中心关键点被预测为同一类的概率较高,反之亦然。 因此,在推理过程中,在将提案生成为一对角点关键点后,我们通过检查是否有同一类的中心关键点落在其中心区域内来确定该提案是否确实是一个对象。
十二、R-CNN
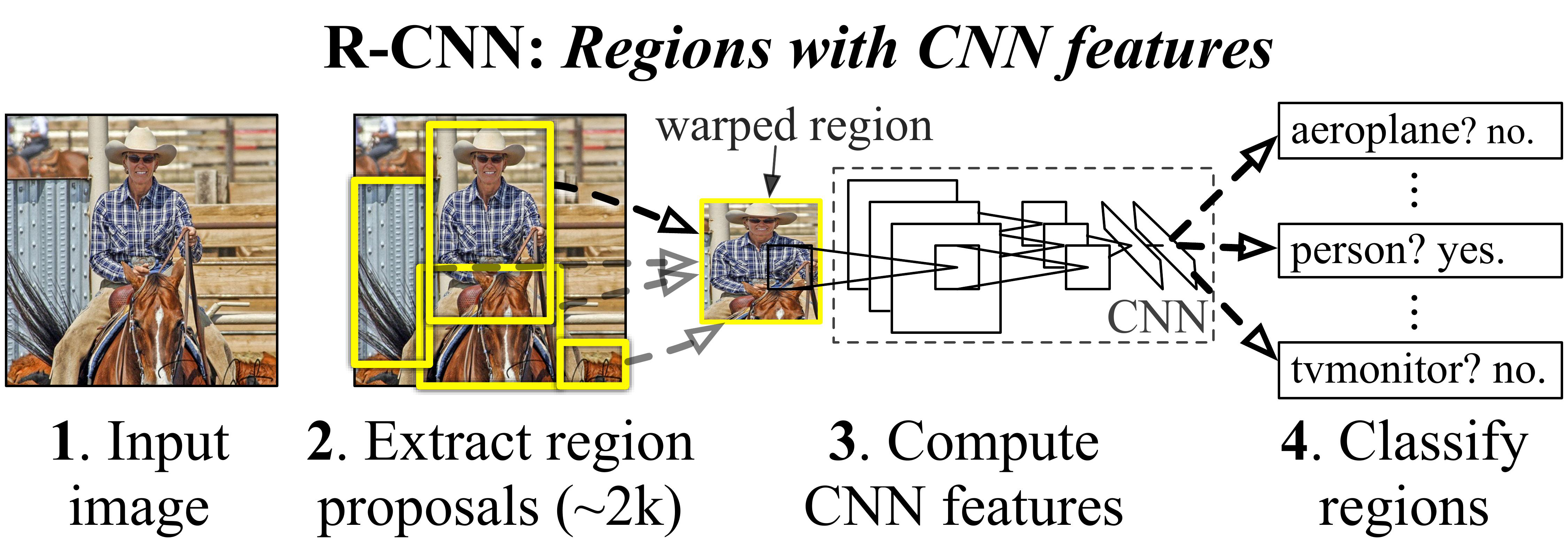
R-CNN(即具有 CNN 特征的区域)是一种对象检测模型,它使用大容量 CNN 自下而上的区域建议来定位和分割对象。 它使用选择性搜索来识别多个边界框对象候选区域(“感兴趣区域”),然后从每个区域独立提取特征进行分类。
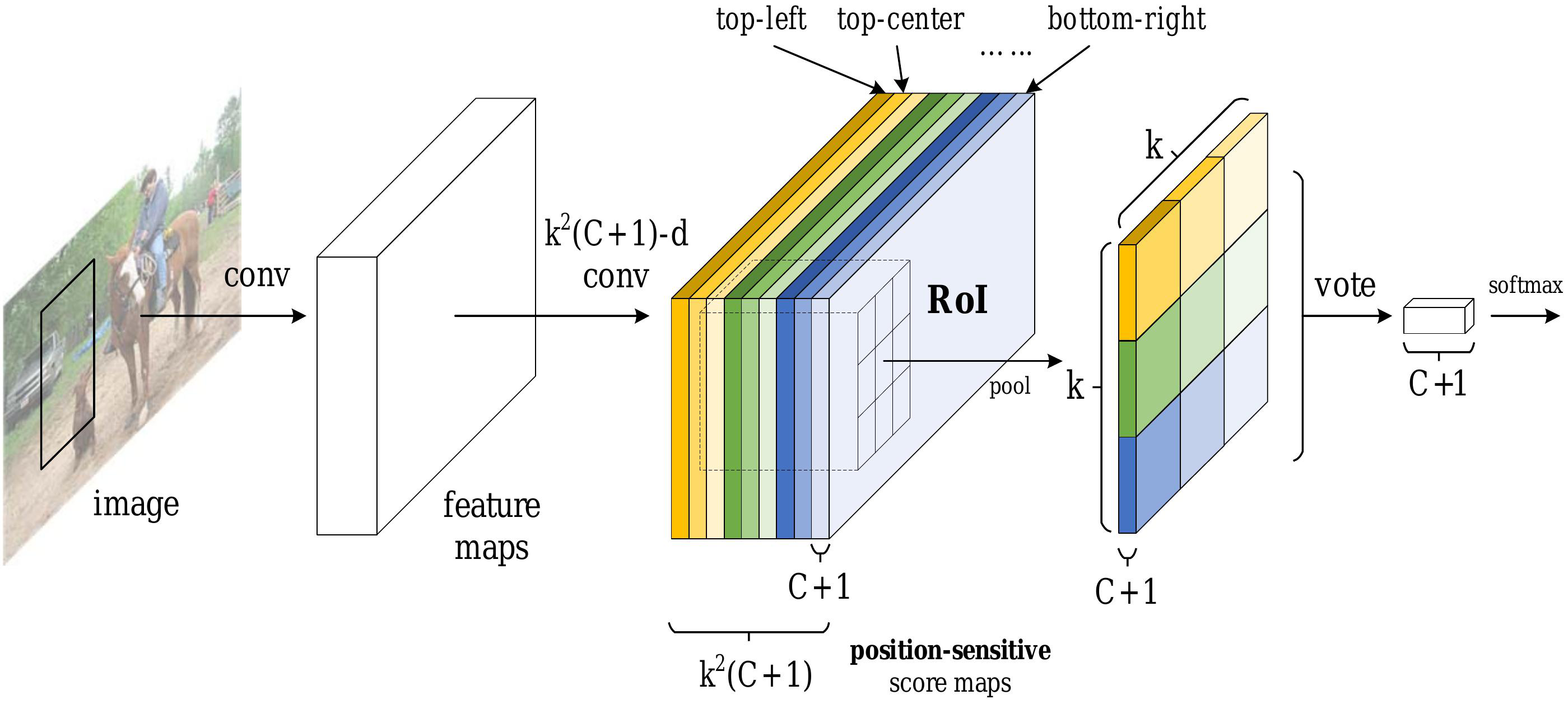
十三、Region-based Fully Convolutional Network
基于区域的全卷积网络(R-FCN)是一种基于区域的目标检测器。 与之前基于区域的目标检测器(例如 Fast/Faster R-CNN)相比,R-FCN 是完全卷积的,几乎所有计算都在整个图像上共享。
为了实现这一目标,R-FCN 利用位置敏感的分数图来解决图像分类中的平移不变性和对象检测中的平移方差之间的困境。
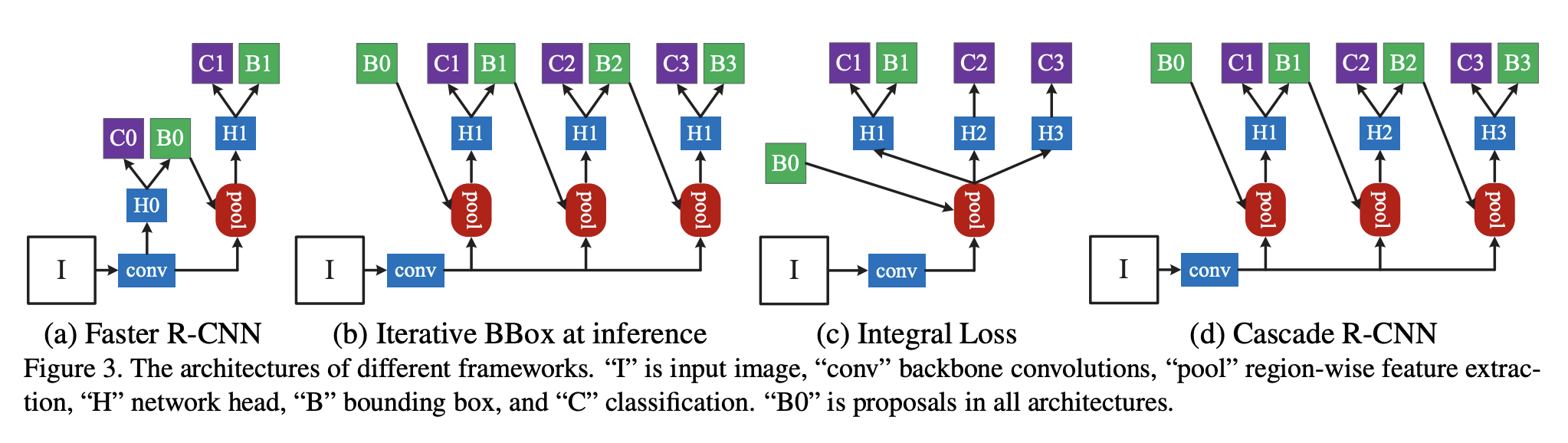
十四、Cascade R-CNN
Cascade R-CNN 是一种目标检测架构,旨在通过增加 IoU 阈值来解决性能下降的问题(由于训练期间的过度拟合以及最佳检测器与输入之间的 IoU 之间的推理时间不匹配)。 它是 R-CNN 的多级扩展,其中级联更深处的检测器级依次对接近的误报更具选择性。 R-CNN 级联级联按顺序进行训练,使用一个阶段的输出来训练下一个阶段。 这是由于观察到回归器的输出 IoU 几乎总是优于输入 IoU。
Cascade R-CNN 的目的不是挖掘硬负例。 相反,通过调整边界框,每个阶段的目标是找到一组良好的接近误报来训练下一阶段。 当以这种方式操作时,适应越来越高的 IoU 的一系列检测器可以克服过度拟合问题,从而得到有效的训练。 在推理时,应用相同的级联过程。 逐步改进的假设与每个阶段不断提高的探测器质量更好地匹配。
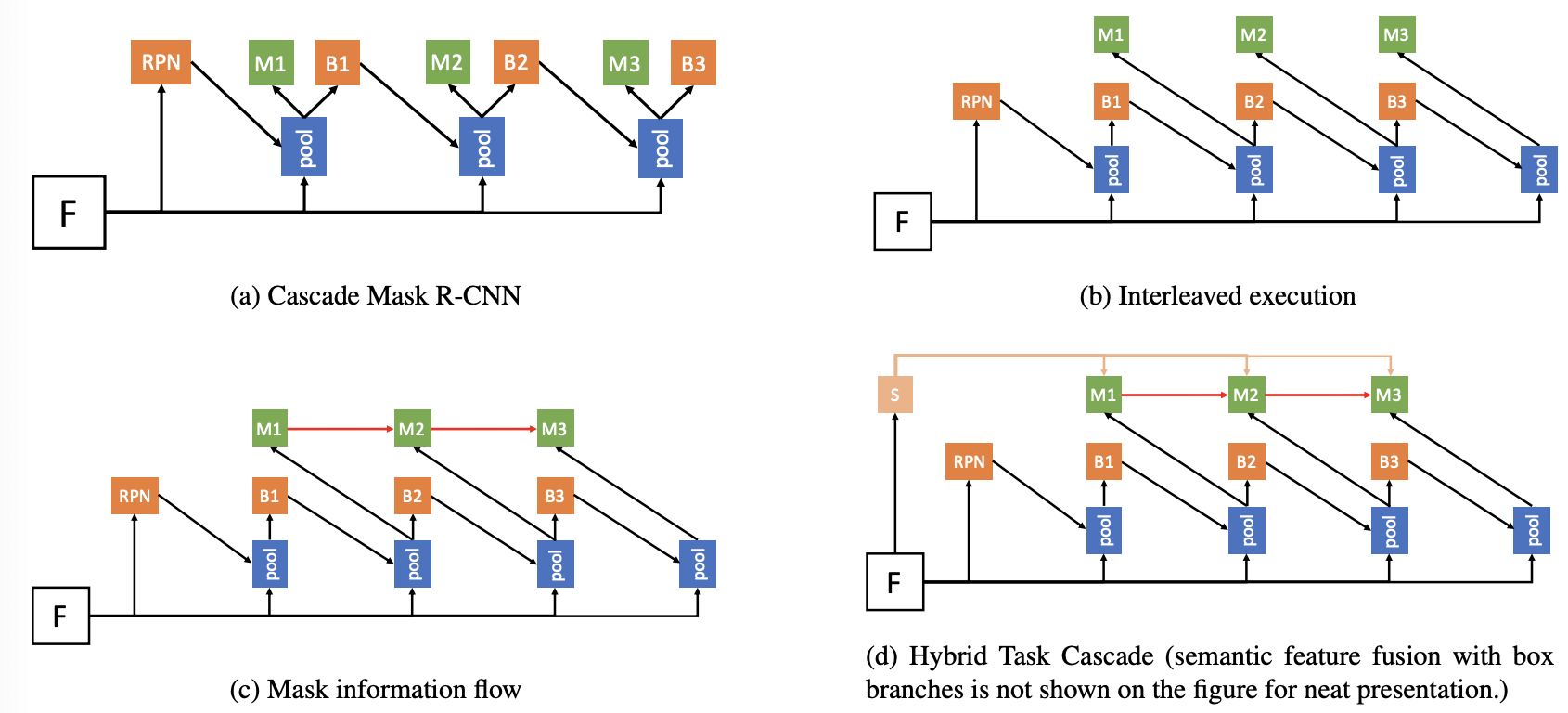
十五、Hybrid Task Cascade
混合任务级联(HTC)是实例分割中级联的框架。 它与Cascade Mask R-CNN有两个重要的区别:(1)不是分别对检测和分割两个任务进行级联细化,而是将它们交织在一起进行联合多阶段处理; (2)它采用全卷积分支来提供空间上下文,这可以帮助区分坚硬的前景和杂乱的背景。