文章目录
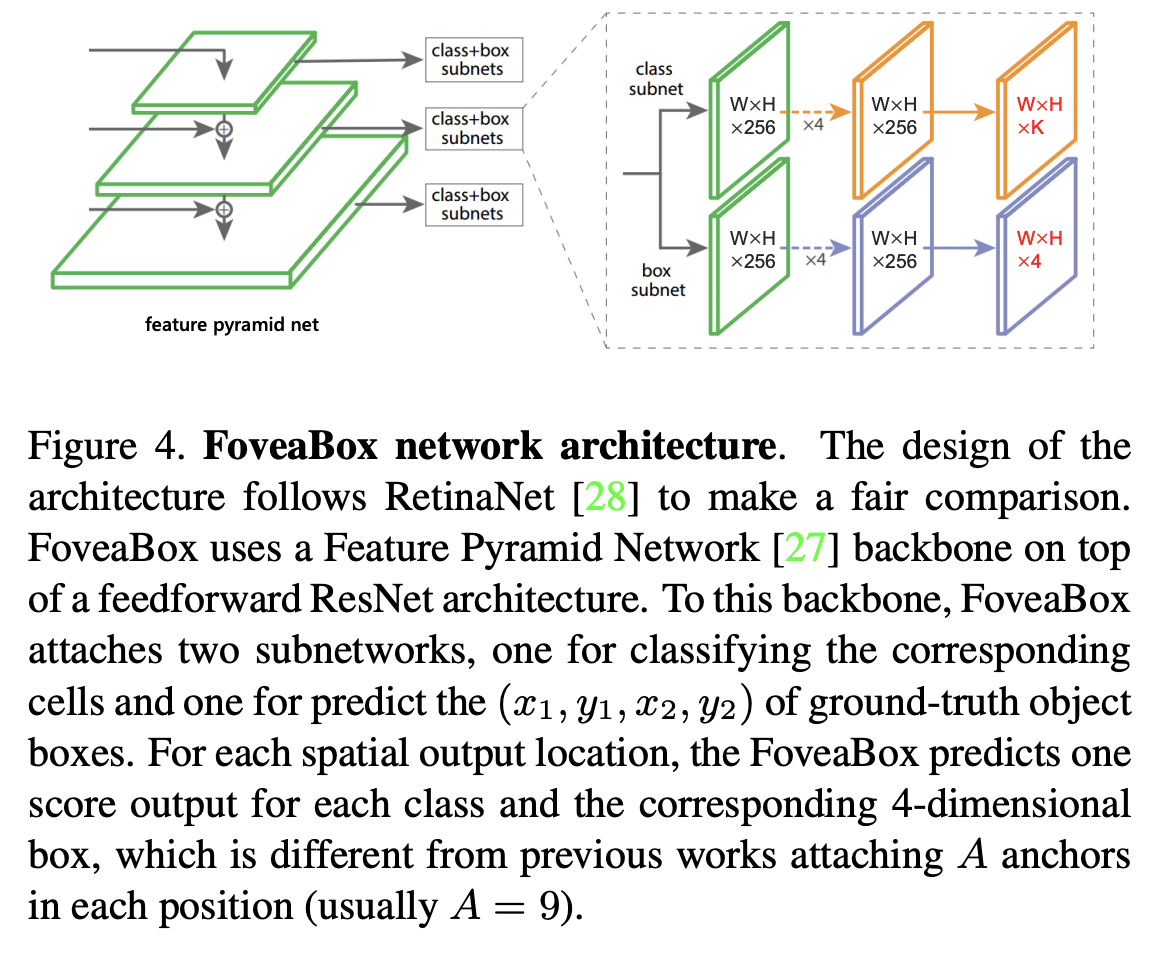
三十一、FoveaBox
FoveaBox 是用于目标检测的无锚框架。 FoveaBox 没有使用预定义的锚点来枚举可能的位置、比例和纵横比来搜索对象,而是直接学习对象存在的可能性和边界框坐标,而无需锚点参考。 这是通过以下方式实现的:(a)预测对象存在可能性的类别敏感语义图,以及(b)为可能包含对象的每个位置生成类别不可知的边界框。 目标框的尺度自然地与每个输入图像的特征金字塔表示相关联
它是一个单一的、统一的网络,由一个主干网络和两个特定于任务的子网络组成。 主干网负责计算整个输入图像上的卷积特征图,是一个现成的卷积网络。 第一个子网对主干网的输出执行每像素分类; 第二个子网对相应位置执行边界框预测。
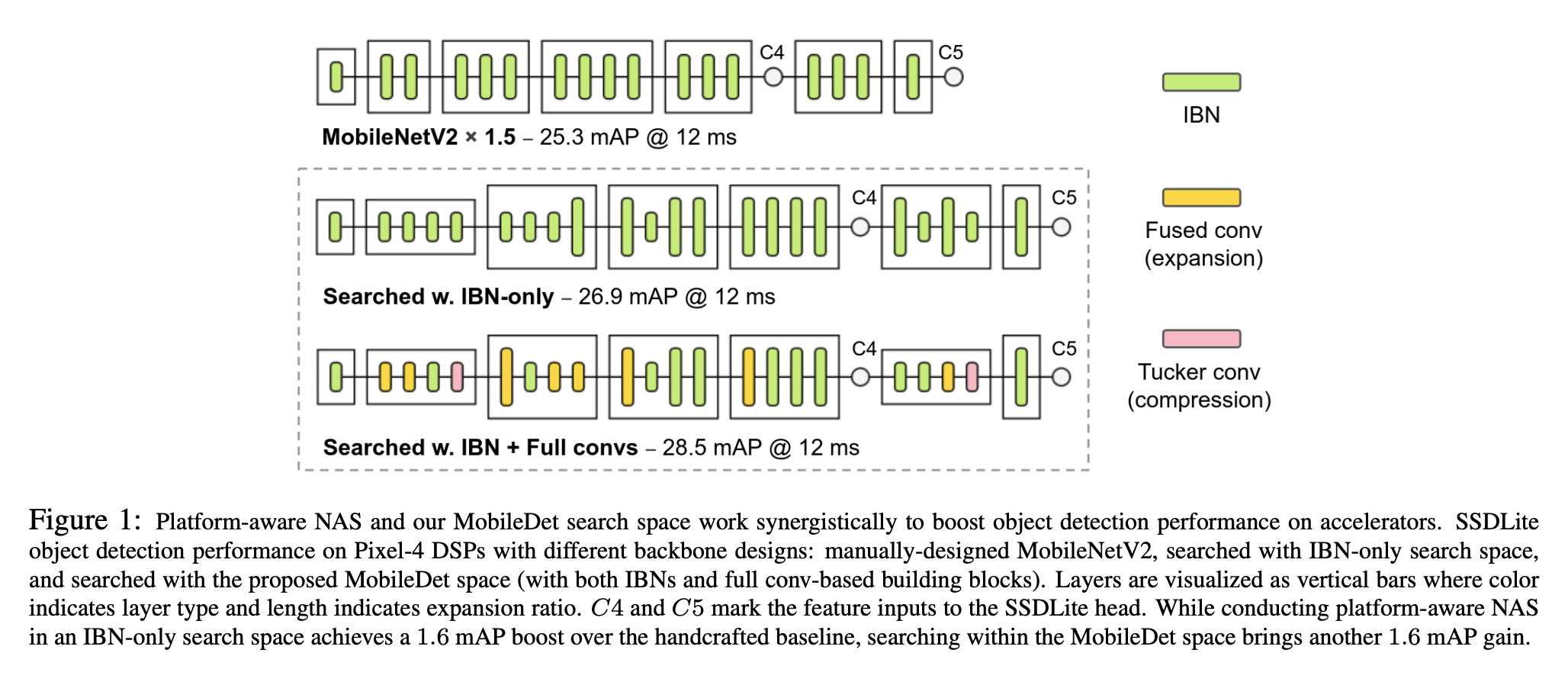
三十二、MobileDet
MobileDet 是为移动加速器开发的对象检测模型。 MobileDets 在 EdgeTPU 和 DSP 上广泛使用常规卷积,特别是在网络的早期阶段,深度卷积往往效率较低。 这有助于提高加速器上对象检测的延迟与准确性权衡,前提是它们通过神经架构搜索战略性地放置在网络中。 通过在搜索空间中结合常规卷积并直接优化用于对象检测的网络架构,获得了一系列高效的对象检测模型。
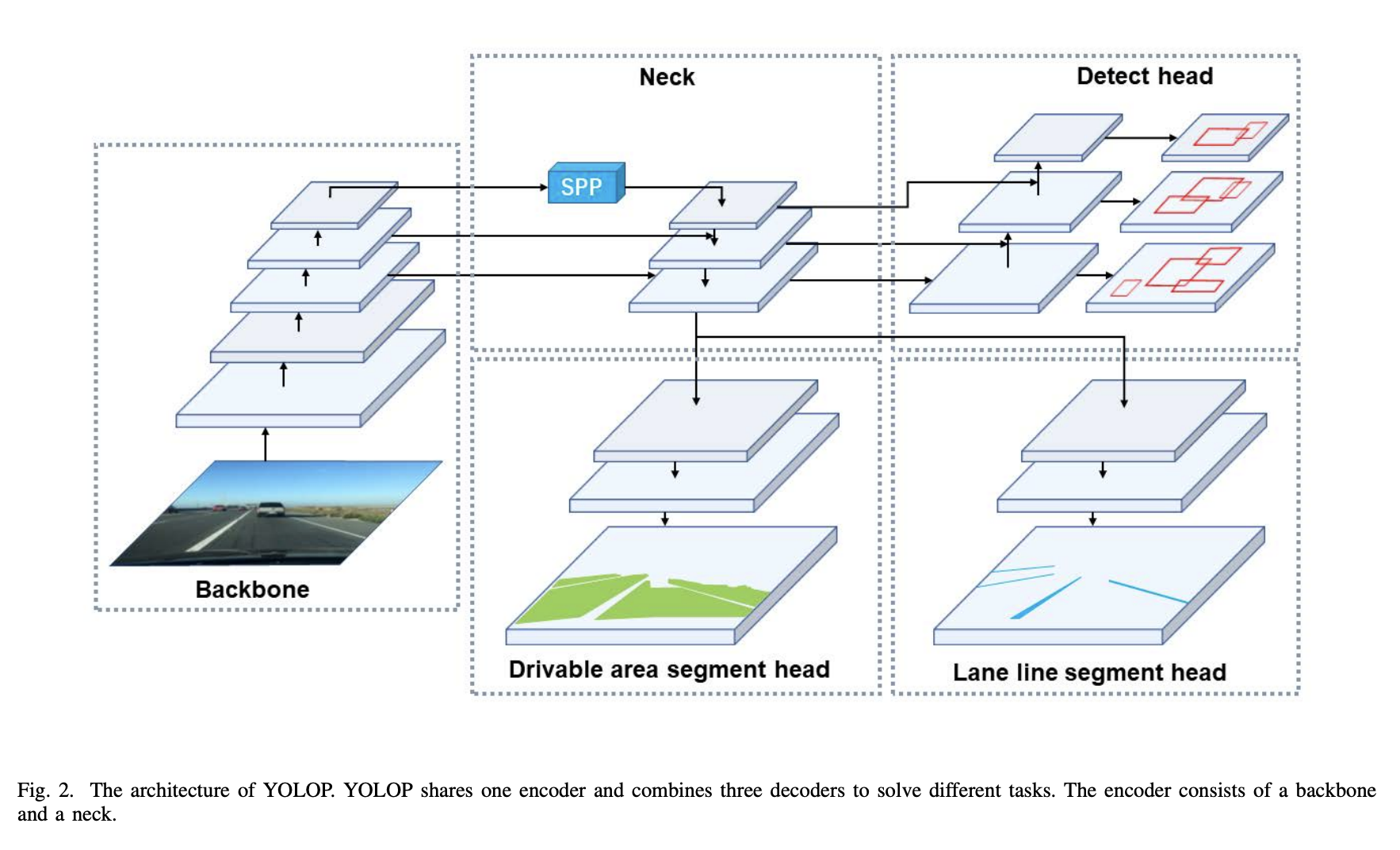
三十三、YOLOP
YOLOP 是一个全景驾驶感知网络,用于同时处理交通对象检测、可驾驶区域分割和车道检测。 它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。 它可以被认为是特斯拉自动驾驶汽车 HydraNet 模型的轻量级版本。
使用来自 Scaled-yolov4 的轻量级 CNN 作为编码器来从图像中提取特征。 然后这些特征图被馈送到三个解码器以完成各自的任务。 检测解码器基于当前性能最好的单级检测网络YOLOv4,主要有两个原因:(1)单级检测网络比两级检测网络更快。 (2)单级检测器的基于网格的预测机制与其他两个语义分割任务更相关,而实例分割通常与基于区域的检测器结合,如Mask R-CNN。 编码器输出的特征图融合了不同级别和尺度的语义特征,我们的分割分支可以使用这些特征图来完成逐像素语义预测。
三十四、Context-aware Visual Attention-based (CoVA) webpage object detection pipeline

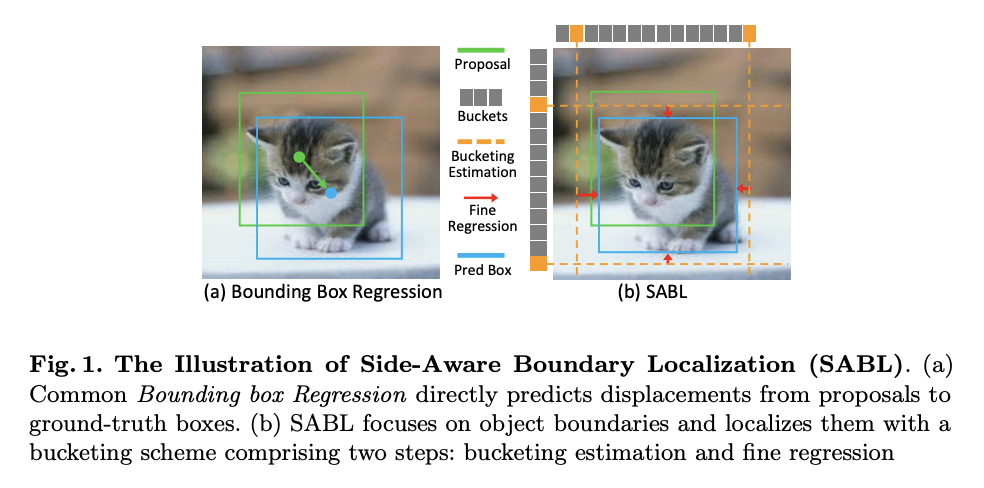
三十五、Side-Aware Boundary Localization
侧面感知边界定位(SABL)是一种在目标检测中精确定位的方法,其中边界框的每一侧分别使用专用网络分支进行本地化。 根据经验,作者观察到,当他们手动注释对象的边界框时,将框的每一侧与对象边界对齐通常比在调整大小时移动整个框要容易得多。 受这一观察的启发,在 SABL 中,边界框的每一侧都根据其周围的上下文分别定位。
如图所示,作者设计了一种分桶方案来提高定位精度。 对于边界框的每一侧,该方案将目标空间划分为多个桶,然后通过两个步骤确定边界框。 具体来说,它首先搜索正确的存储桶,即边界所在的存储桶。 利用所选桶的中心线作为粗略估计,然后通过预测偏移来执行精细回归。 即使存在较大方差的位移,该方案也可以实现非常精确的定位。 此外,为了在非极大值抑制过程中保留精确定位的边界框,作者还建议根据分桶置信度调整分类分数,从而进一步提高性能。
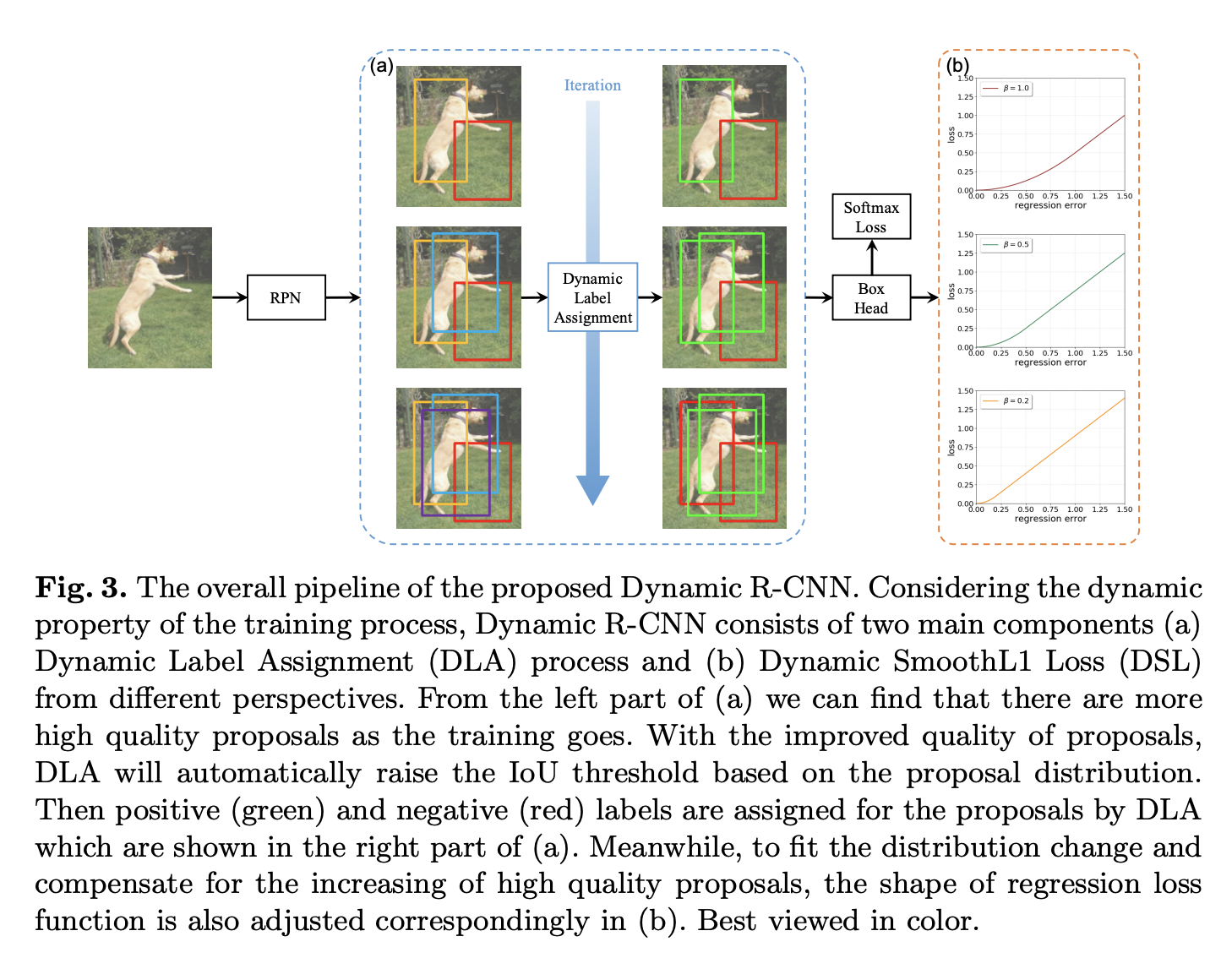
三十六、Dynamic R-CNN
Dynamic R-CNN 是一种目标检测方法,它根据训练期间提案的统计数据自动调整标签分配标准(IoU 阈值)和回归损失函数的形状(Smooth L1 Loss 的参数)。 其动机是,在之前的两阶段目标检测器中,固定网络设置和动态训练过程之间存在不一致问题。 例如,固定的标签分配策略和回归损失函数无法适应提案的分布变化,从而不利于训练高质量的检测器。
它由两个组件组成:动态标签分配和动态平滑 L1 损失,分别是为分类和回归分支设计的。
对于动态标签分配,我们希望我们的模型能够区分高 IoU 提案,因此我们根据训练过程中的提案分布逐渐调整正/负样本的 IoU 阈值。 具体来说,我们将阈值设置为提案的 IoU 一定百分比,因为它可以反映整体分布的质量。
对于Dynamic Smooth L1 Loss,我们希望改变回归损失函数的形状,以自适应地拟合误差的分布变化,保证高质量样本对训练的贡献。 这是通过调整来实现的在Smooth L1 Loss中基于回归损失函数的误差分布,其中实际上控制了小误差梯度的大小。
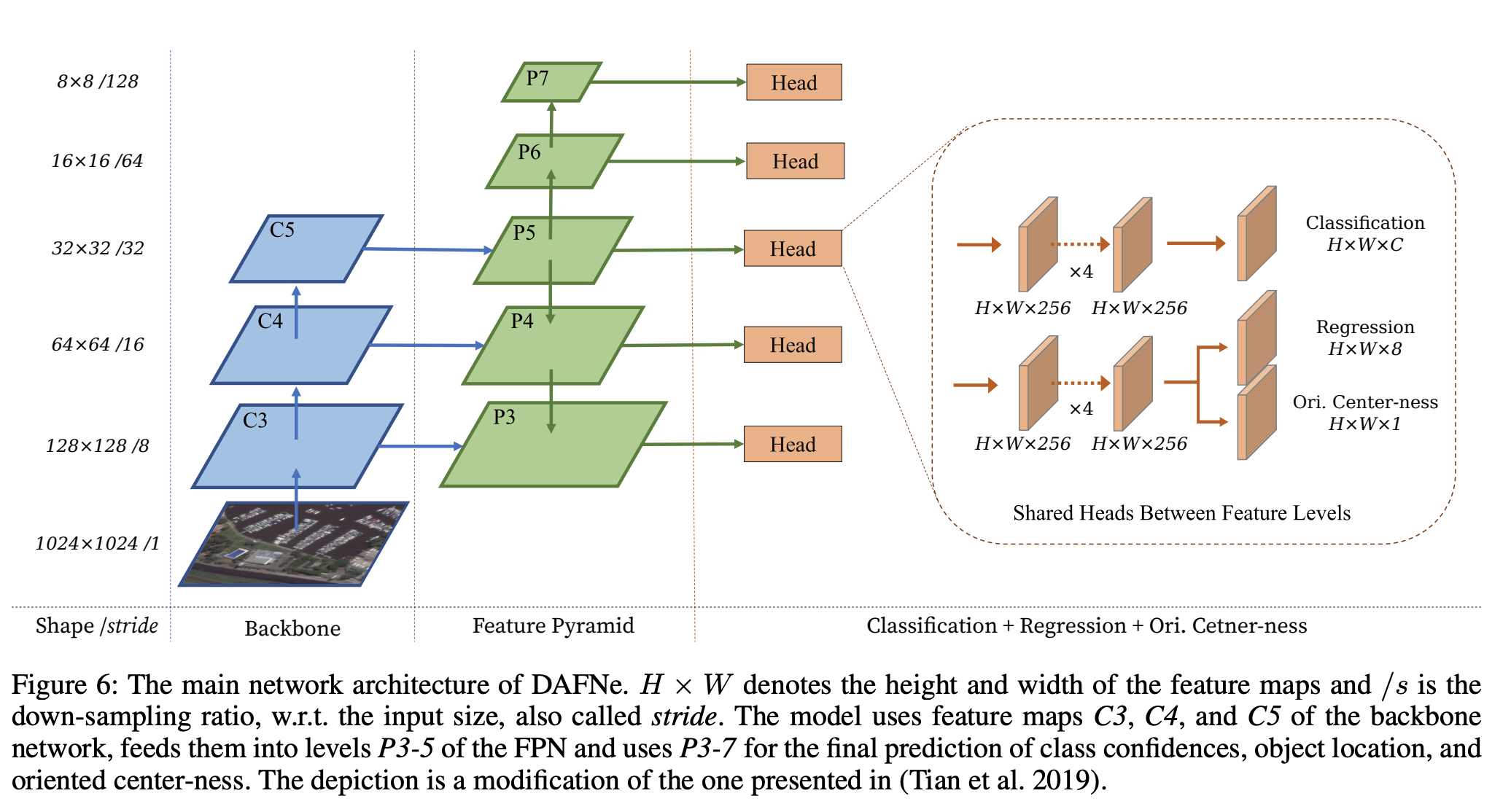
三十七、DAFNe
DAFNe 是一种用于定向目标检测的密集单阶段无锚深度模型。 它是一种深度神经网络,可对输入图像的密集网格进行预测,其架构设计更简单,并且比两阶段网络更容易优化。 此外,它通过避免使用边界框锚点来降低预测复杂性。 这使得能够更紧密地适应定向对象,从而更好地分离边界框,特别是在密集对象分布的情况下。 此外,它引入了中心函数到任意四边形的方向感知泛化,考虑了对象的方向,并相应地准确地降低了低质量预测的权重
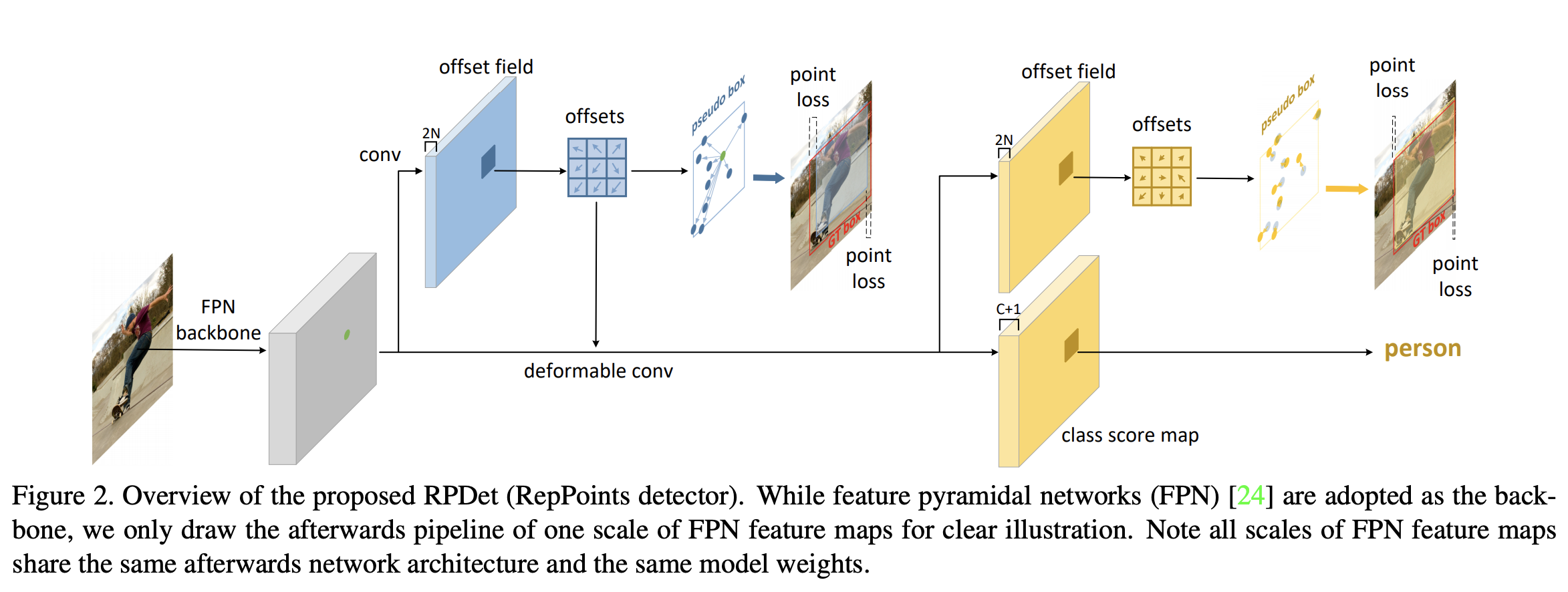
三十八、RPDet
RPDet(或 RepPoints Detector)是一种基于可变形卷积的无锚、两阶段目标检测模型。 代表点充当整个检测系统的基本对象表示。 从中心点开始,通过中心点上的回归偏移获得第一组 RepPoints。 这些 RepPoints 的学习由两个目标驱动:1)诱导伪框和地面实况边界框之间的左上角和右下点距离损失; 2)后续阶段的物体识别损失。
三十九、RetinaNet-RS
RetinaNet-RS是通过基于改变输入分辨率和ResNet主干深度的模型缩放方法产生的对象检测模型。 对于 RetinaNet,我们将输入分辨率从 512 扩大到 768,将 ResNet 主干深度从 50 扩大到 152。由于 RetinaNet 执行密集的单阶段目标检测,作者发现扩大输入分辨率会导致大分辨率特征图,因此需要处理更多锚点 。 这导致更高容量的密集预测头和昂贵的 NMS。 对于 RetinaNet,缩放在输入分辨率为 768 × 768 时停止。

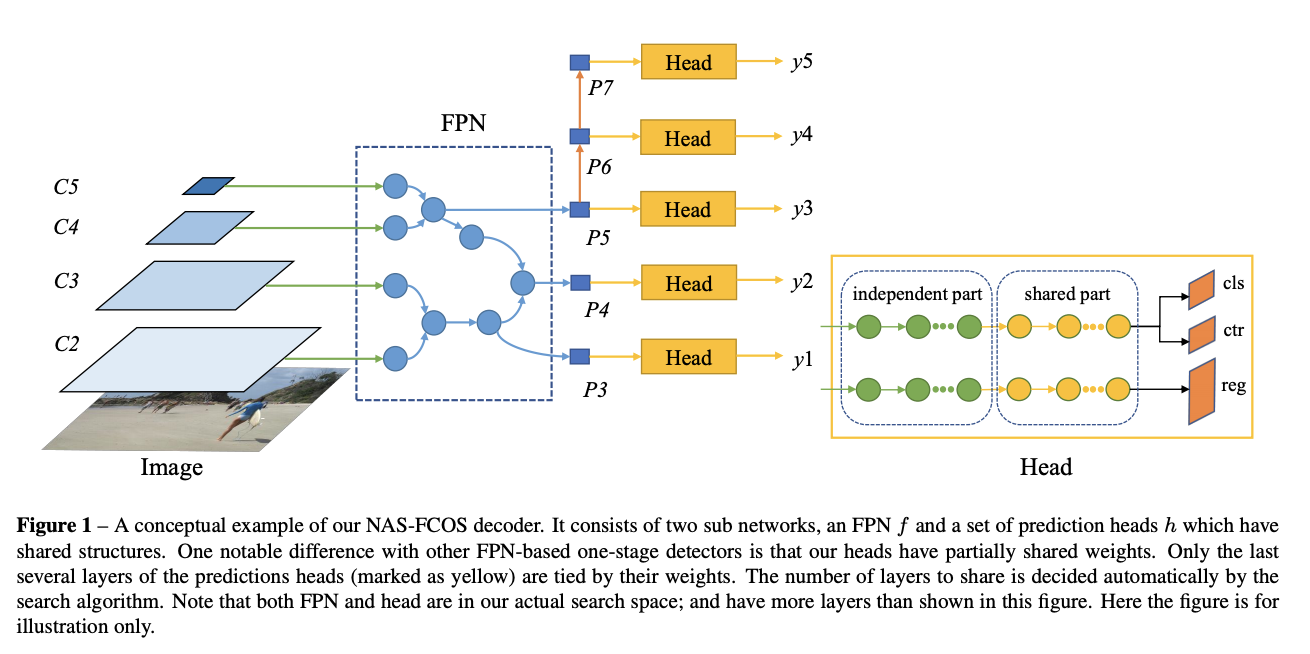
四十、NAS-FCOS
NAS-FCOS由两个子网络组成,一个是FPN f和一组预测头h具有共享结构。 与其他基于 FPN 的一级检测器的一个显着区别是我们的头部具有部分共享的权重。 只有预测头的最后几层(标记为黄色)与其权重相关。 共享的层数由搜索算法自动决定。 请注意,FPN 和 head 都在我们实际的搜索空间中; 并且具有比该图中所示更多的层。
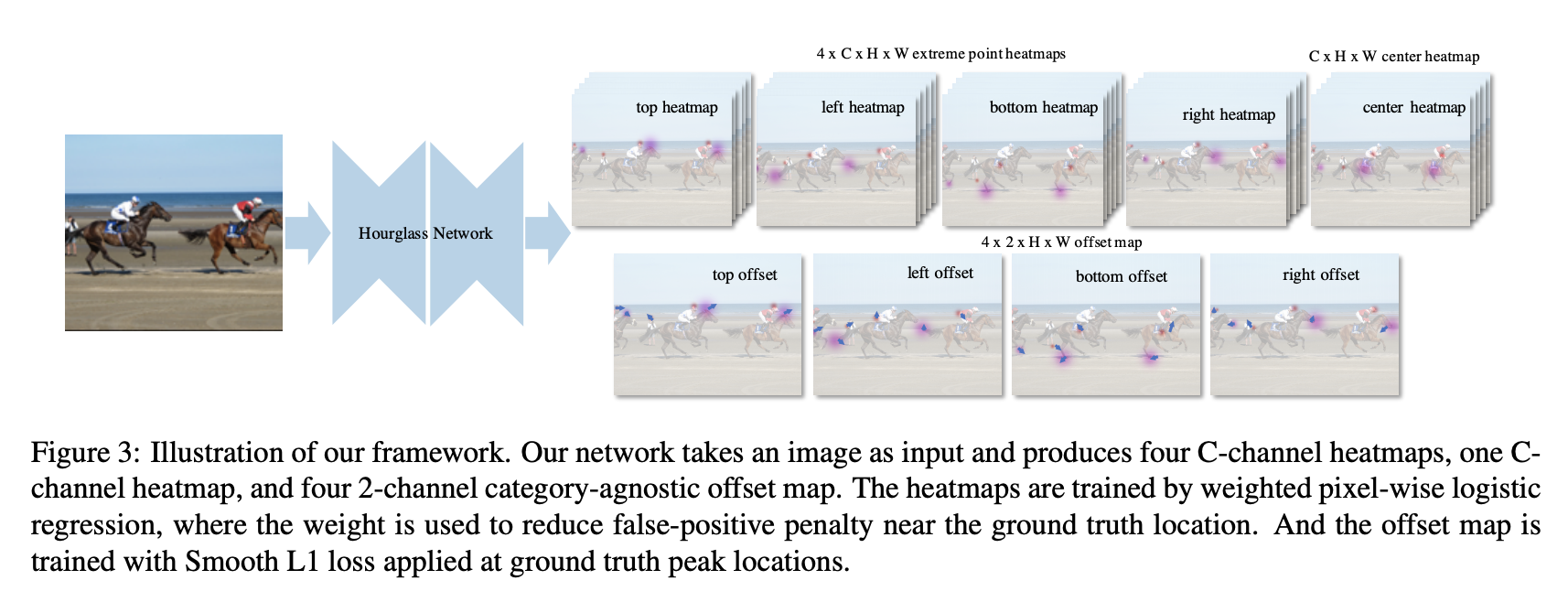
四十一、ExtremeNet
xtremeNet 是一个自下而上的对象检测框架,可检测对象的四个极值点(最顶部、最左侧、最底部、最右侧)。 它使用关键点估计框架通过预测每个对象类别的四个多峰热图来查找极值点。 此外,它为每个类别使用一个热图来预测对象中心,作为 x 和 y 维度上两个边界框边缘的平均值。 我们使用纯粹基于几何的方法将极值点分组为对象。 我们将四个极值点分组,每个图中一个,当且仅当它们的几何中心在中心热图中预测的分数高于预定义的阈值时,我们枚举所有极值点预测的组合,并选择有效的。
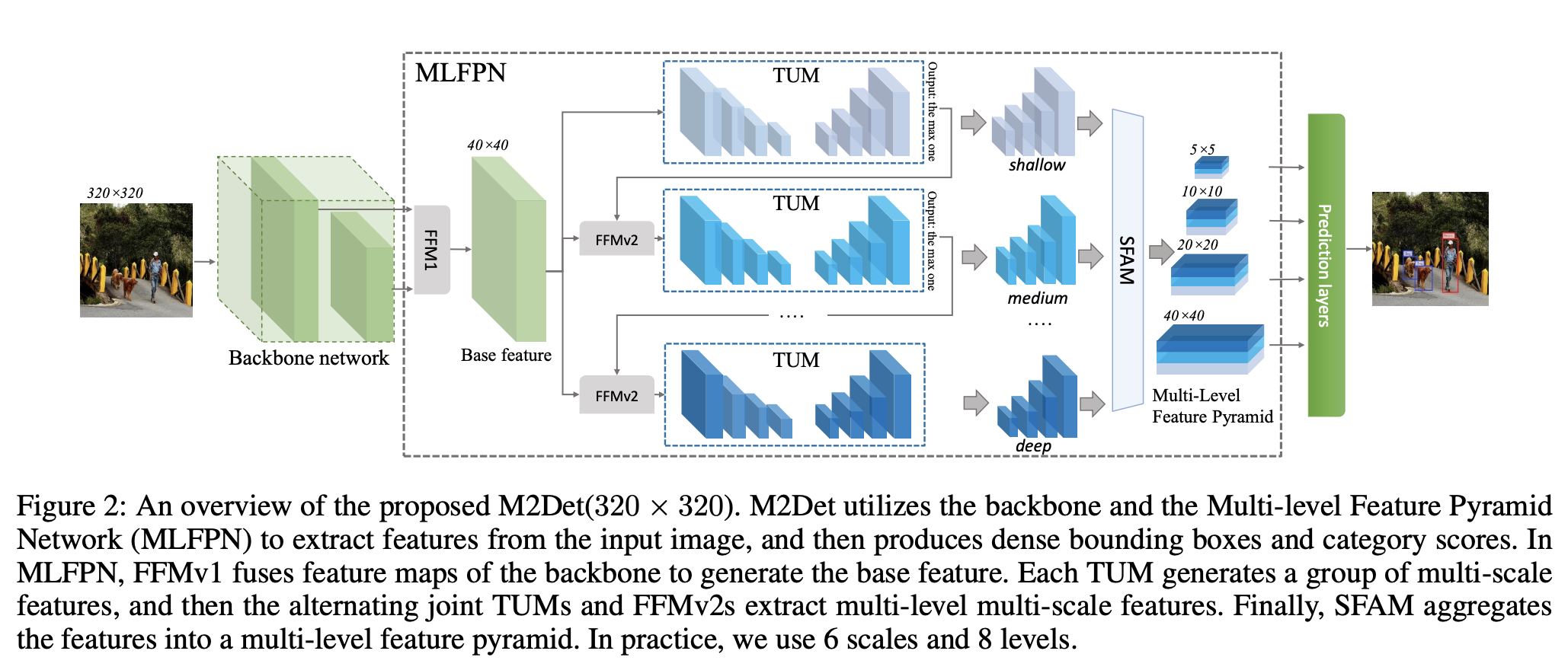
四十二、M2Det
M2Det 是一种单阶段目标检测模型,利用多级特征金字塔网络 (MLFPN) 从输入图像中提取特征,然后类似于 SSD,根据学习到的特征生成密集的边界框和类别分数,然后 非极大值抑制(NMS)操作以产生最终结果。
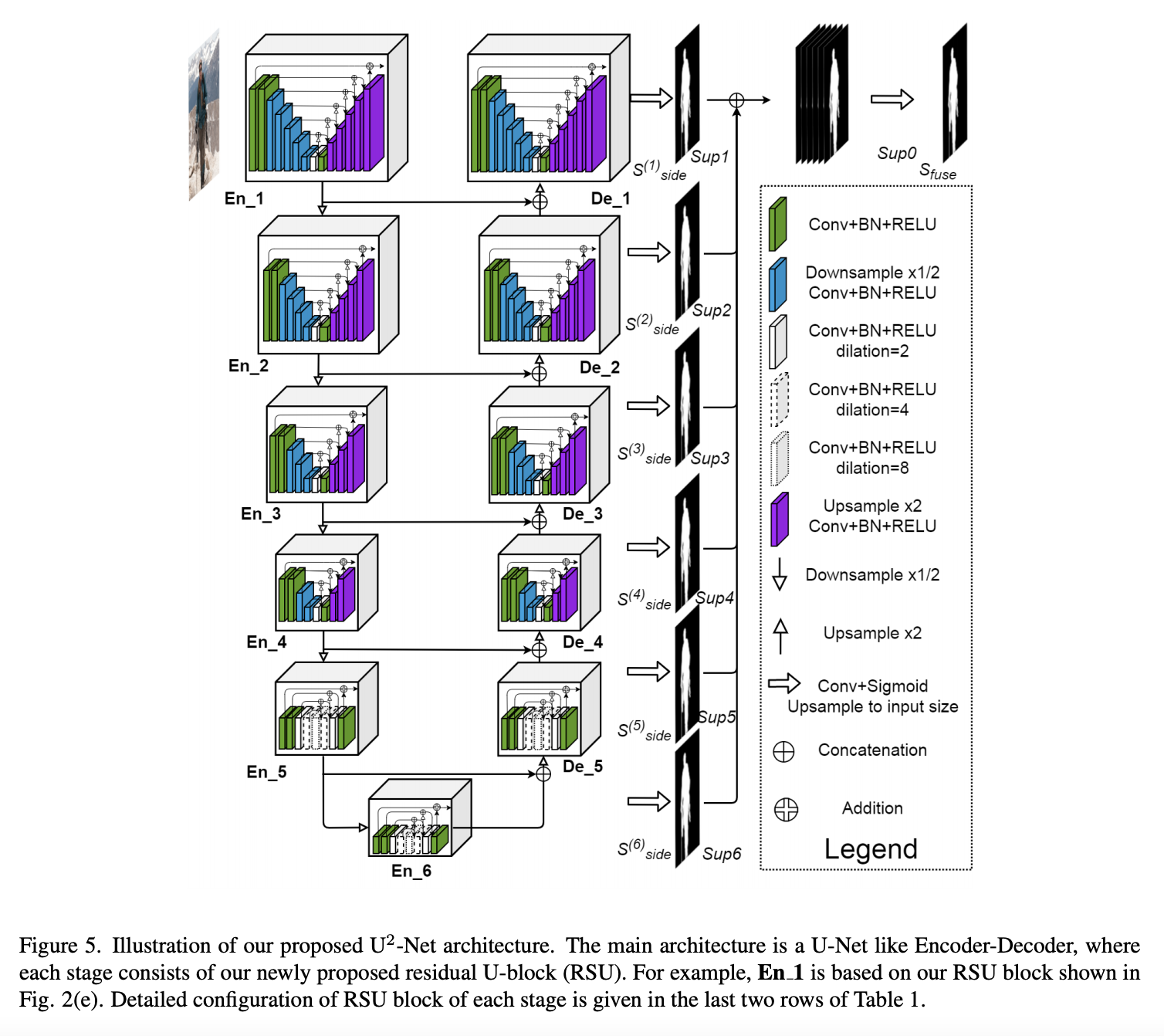
四十三、U2-Net
U2-Net 是一种两级嵌套 U 结构架构,专为显着目标检测(SOD)而设计。 该架构允许网络更深入,获得高分辨率,而不会显着增加内存和计算成本。 这是通过嵌套的 U 型结构实现的:在底层,采用新颖的 ReSidual U 型块(RSU)模块,能够在不降低特征图分辨率的情况下提取阶段内多尺度特征; 在顶层,有一个类似 U-Net 的结构,其中每个阶段都由 RSU 块填充。
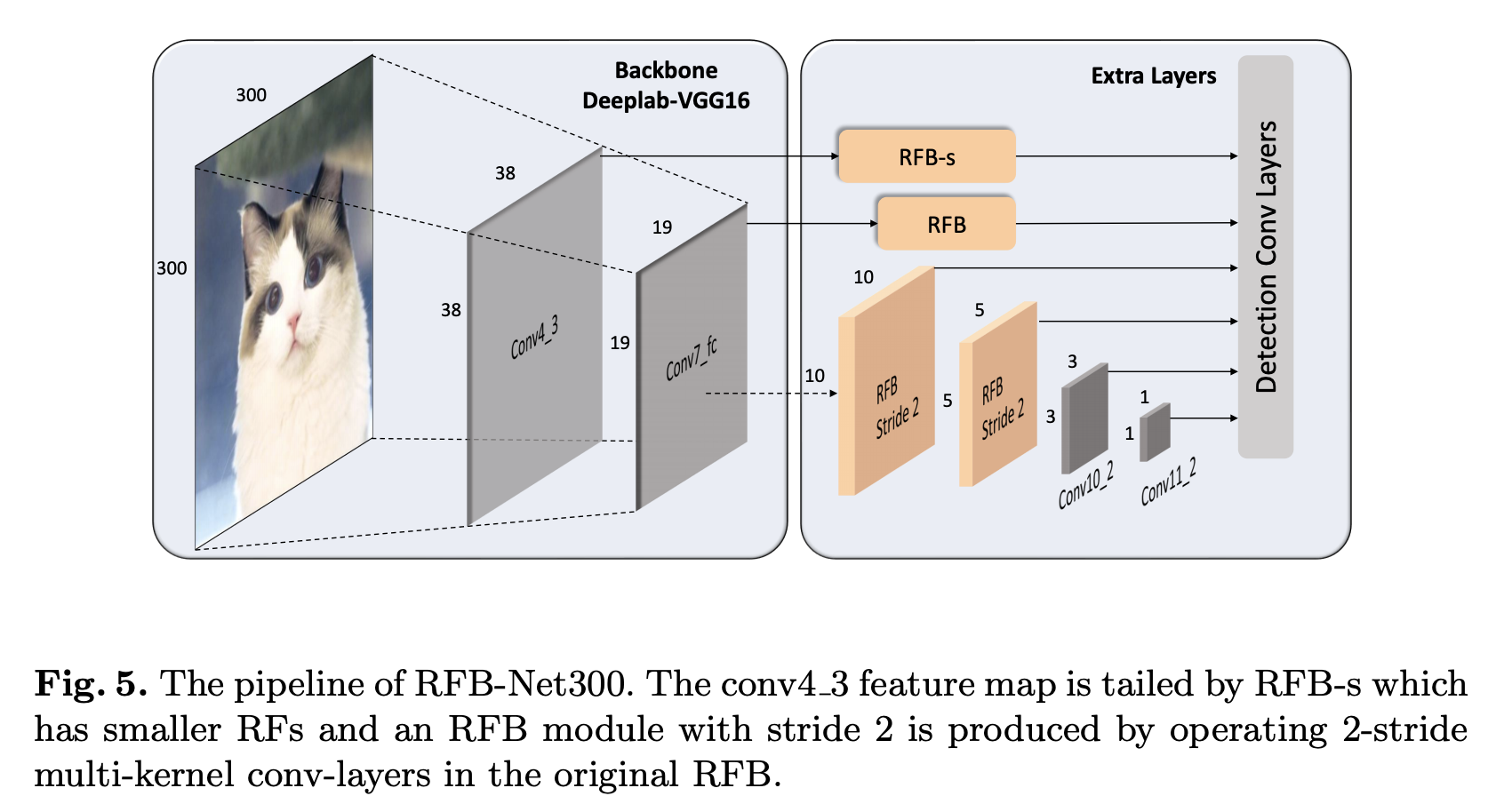
四十四、RFB Net
RFB Net 是一种利用感受野块模块的单级物体检测器。 它采用 VGG16 主干,其他方面与 SSD 架构非常相似。
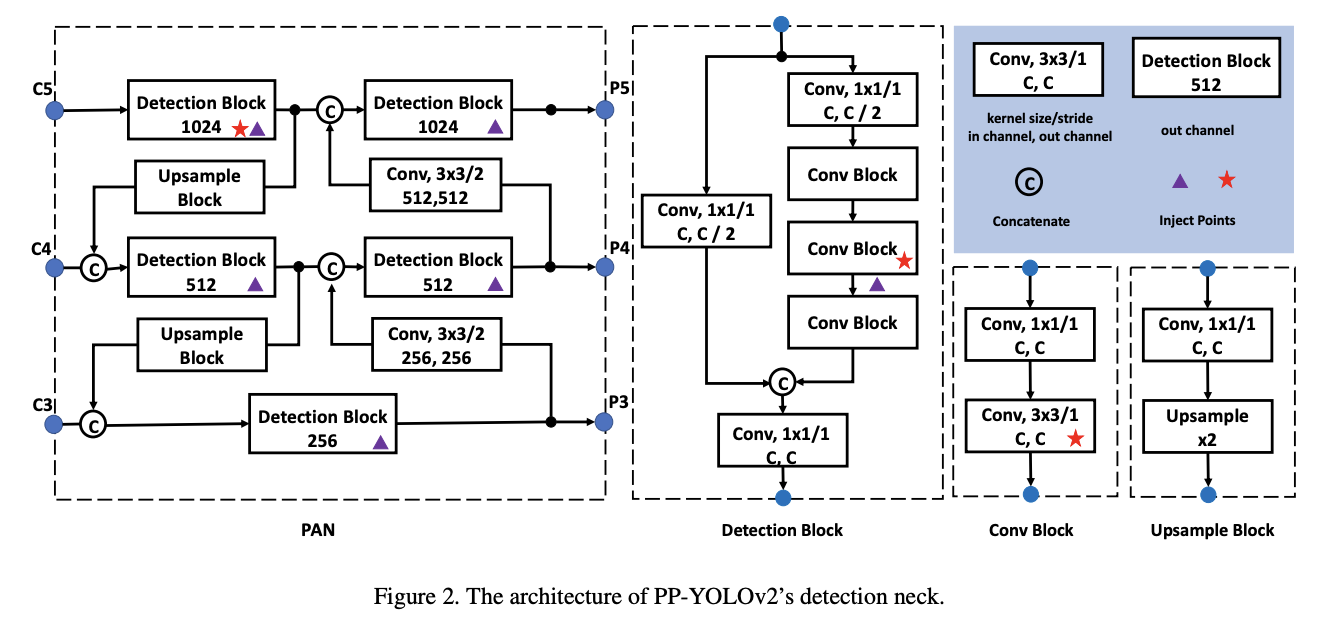
四十五、PP-YOLOv2
PP-YOLOv2 是一种在 PP-YOLO 的基础上进行扩展的目标检测器,并进行了多项改进:
FPN 包含一个路径聚合网络来组成自下而上的路径。
使用 Mish 激活函数。
输入大小被扩展。
IoU 感知分支是使用软标签格式计算的。