文章目录
一、CSPResNeXt
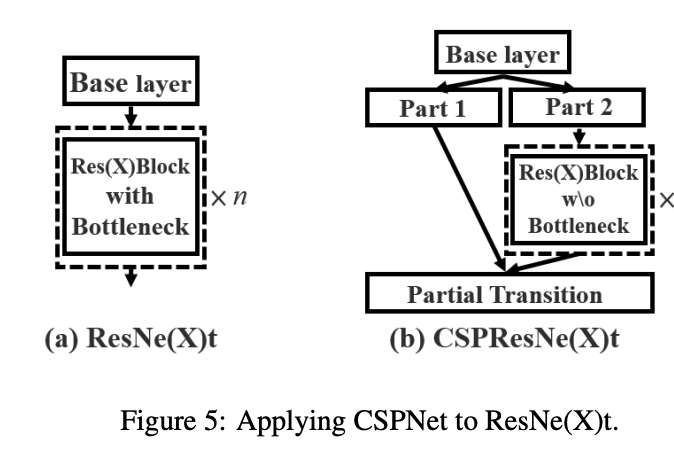
CSPResNeXt 是一种卷积神经网络,我们将跨阶段部分网络 (CSPNet) 方法应用于 ResNeXt。 CSPNet 将基础层的特征图划分为两部分,然后通过跨阶段层次结构将它们合并。 使用拆分和合并策略允许更多的梯度流通过网络。
二、ProxylessNet-Mobile
ProxylessNet-Mobile 是一种通过 ProxylessNAS 神经架构搜索算法学习的卷积神经架构,该算法针对移动设备进行了优化。 它使用 MobileNetV2 中的反向残差块 (MBConvs) 作为其基本构建块。

三、ProxylessNet-CPU
ProxylessNet-CPU 是通过 ProxylessNAS 神经架构搜索算法学习的图像模型,该算法针对 CPU 设备进行了优化。 它使用 MobileNetV2 中的反向残差块 (MBConvs) 作为其基本构建块。

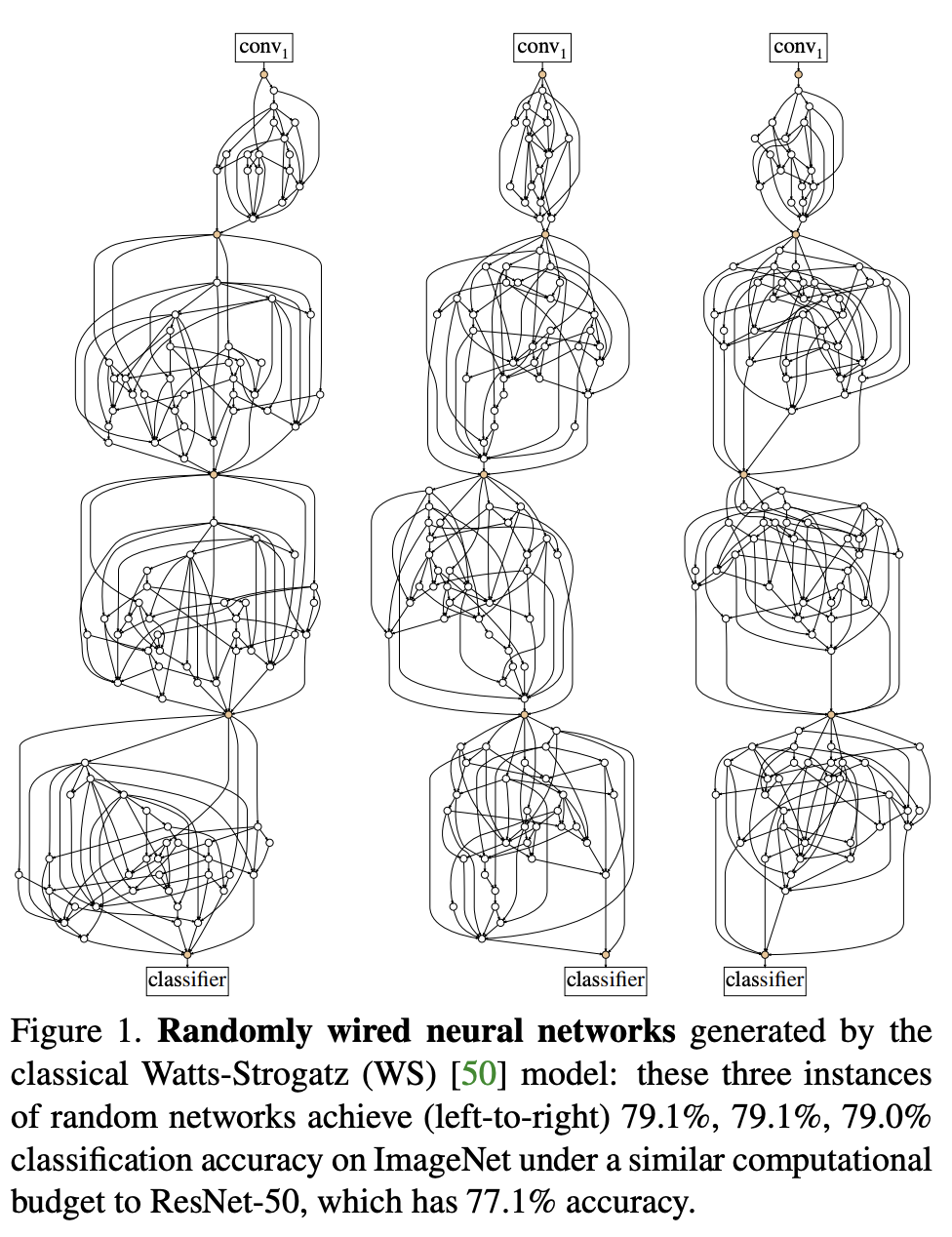
四、RandWire
RandWire 是一种卷积神经网络,由从随机网络生成器采样的随机连线神经网络产生,其中由人类设计的随机过程定义生成。
五、MCKERNEL
McKernel 引入了一个框架,可以在小批量设置中使用内核近似,并使用随机梯度下降 (SGD) 作为深度学习的替代方案。
该核心库于 2014 年开发,作为卡内基梅隆大学和香港城市大学理学硕士论文 [1,2] 的组成部分。 最初的目的是通过编写一个非常高效的 HADAMARD 变换来实现随机厨房水槽(Rahimi 和 Recht 2007)的加速,这是构建的主要瓶颈。 不过,该代码后来在苏黎世联邦理工学院进行了扩展(Curtó 等人于 2017 年在 McKernel 中),提出了一个可以解释内核方法和神经网络的框架。 这篇手稿和相应的论文构成了傅里叶特征和深度学习文献中的第一个用法(如果不是第一个); 后来引起了社区的广泛研究关注和兴趣。
更多信息可以在第一作者在 ICLR 2020 iclr2020_DeCurto 上发表的演讲中找到。
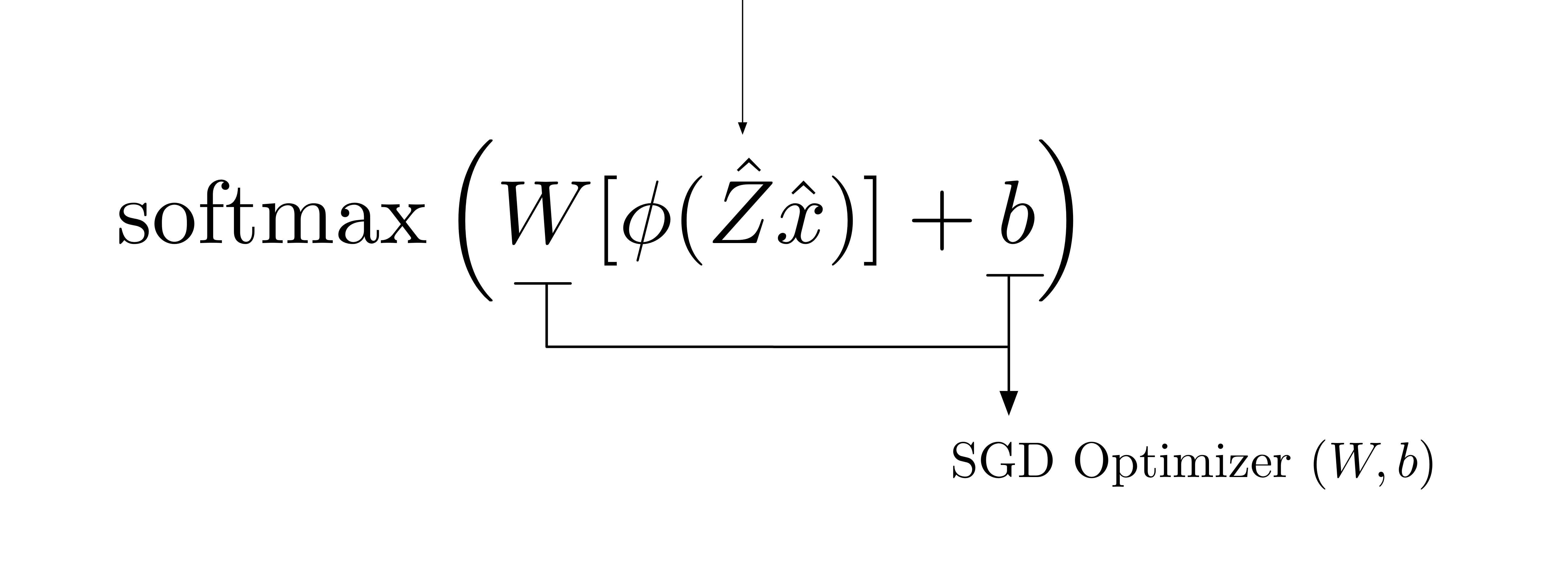
六、Assemble-ResNet
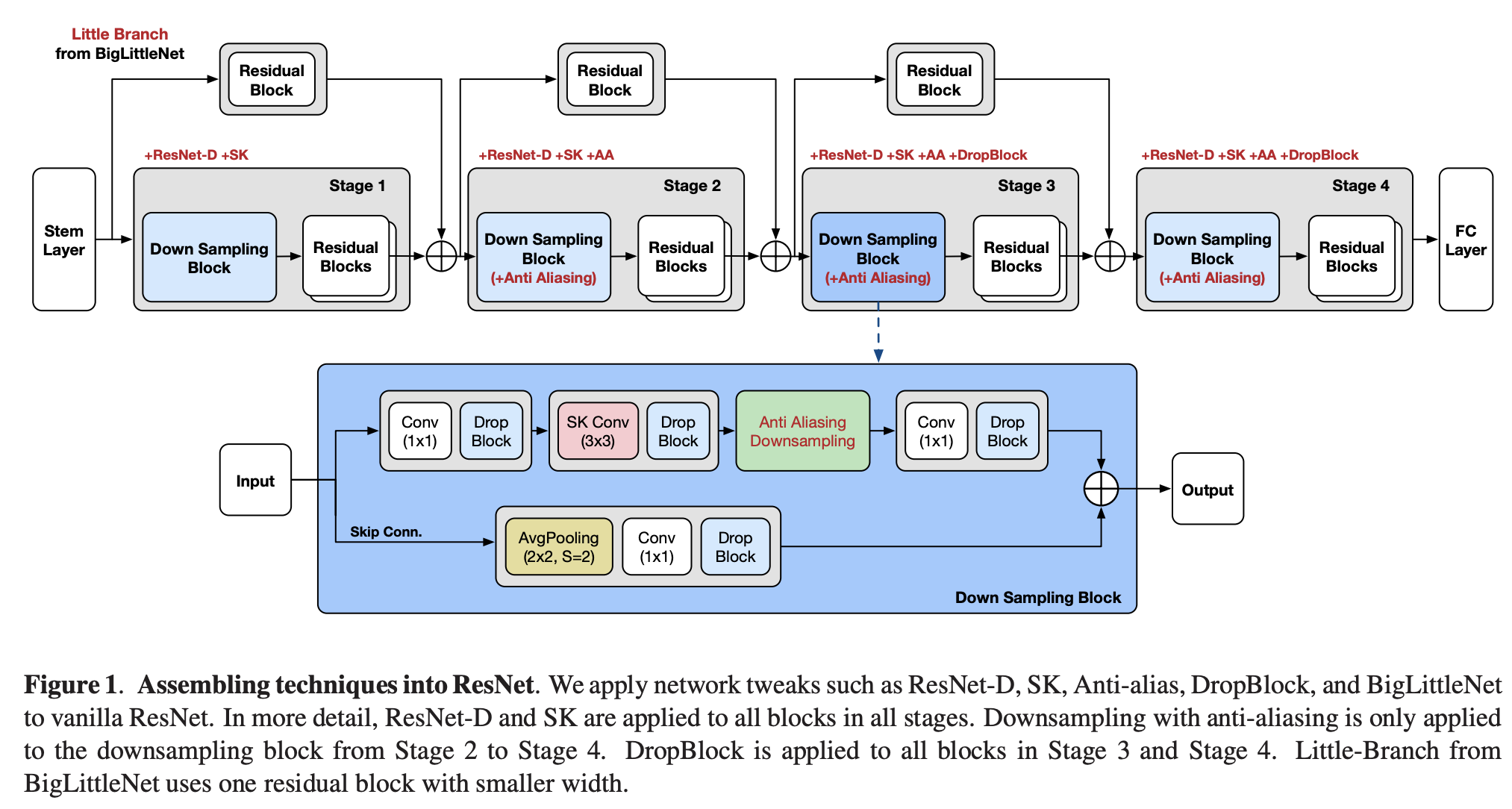
Assemble-ResNet 是对 ResNet 架构的修改,进行了多项调整,包括使用 ResNet-D、通道注意力、抗锯齿下采样和大小网络。
七、Convolution-enhanced image Transformer(CeiT)
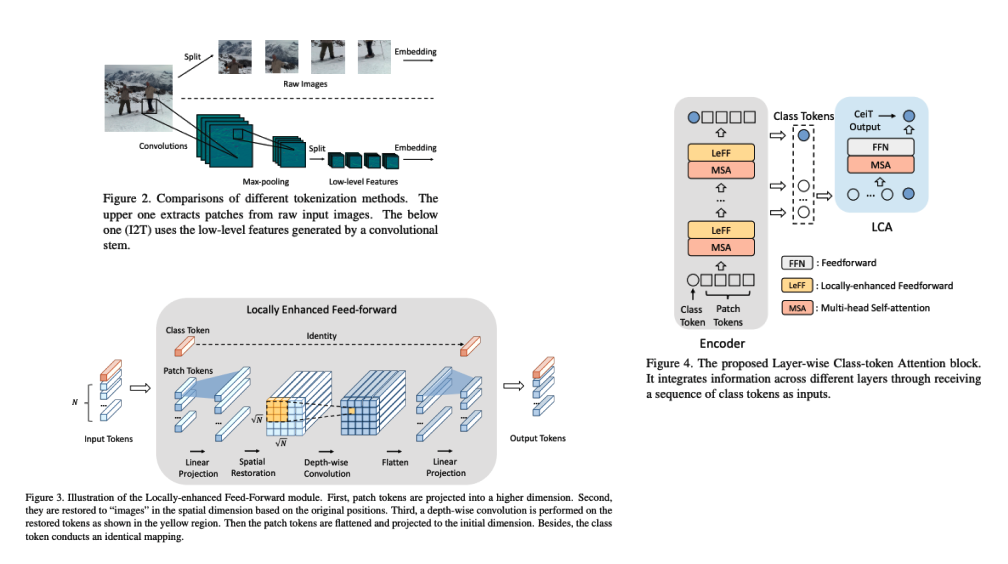
卷积增强图像 Transformer (CeiT) 结合了 CNN 在提取低级特征、加强局部性方面的优势以及 Transformer 在建立远程依赖关系方面的优势。 对原始 Transformer 进行了三处修改:1)我们设计了一个图像到令牌(I2T)模块,该模块从生成的低级特征中提取补丁,而不是直接从原始输入图像进行令牌化; 2)每个编码器块中的前馈网络被替换为局部增强前馈(LeFF)层,该层促进空间维度上相邻标记之间的相关性; 3)分层类令牌注意力(LCA)附加在利用多层表示的 Transformer 的顶部。
八、IICNet
可逆图像转换网络(IICNet)是用于可逆图像转换任务的通用框架。 与之前基于编码器-解码器的方法不同,IICNet 保持基于可逆神经网络 (INN) 的高度可逆结构,以便在转换过程中更好地保留信息。 它使用关系模块和通道挤压层来分别提高 INN 非线性以提取跨图像关系和网络灵活性。

九、RegNetX

十、SCARLET
SCARLET 是一种通过 SCARLET-NAS 神经架构搜索方法学习的卷积神经架构。 这三个变体是 SCARLET-A、SCARLET-B 和 SCARLET-C。 基本构建块是来自 MobileNetV2 的 MBConvs。 还对挤压和激励层进行了实验。

十一、ProxylessNet-GPU
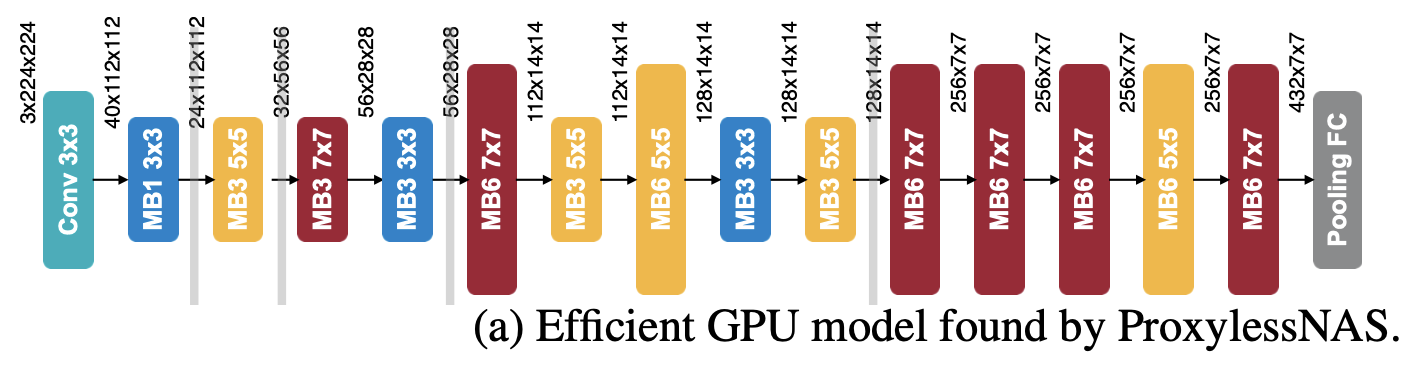
ProxylessNet-GPU 是一种通过 ProxylessNAS 神经架构搜索算法学习的卷积神经网络架构,该算法针对 GPU 设备进行了优化。 它使用 MobileNetV2 中的反向残差块 (MBConvs) 作为其基本构建块。
十二、VATT
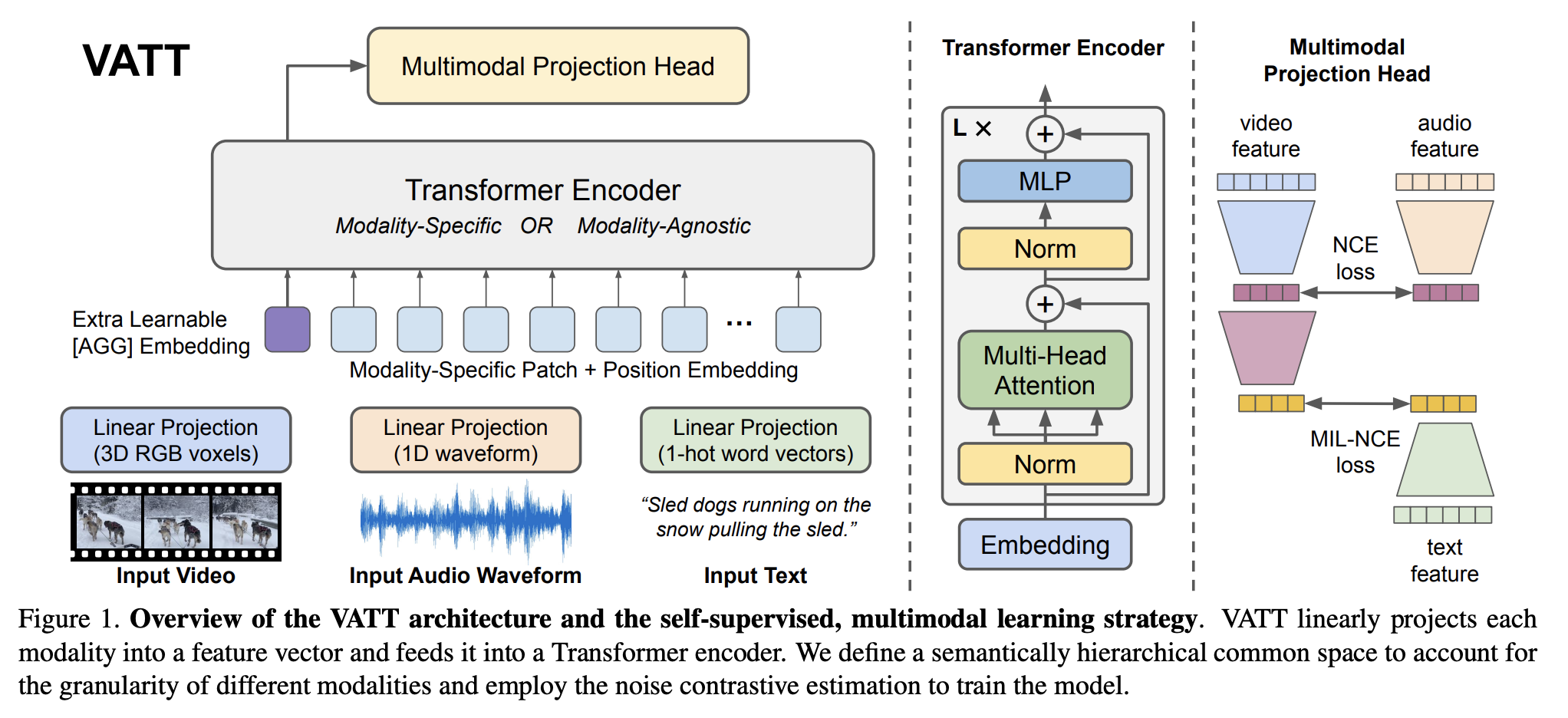
视频-音频-文本 Transformer(VATT)是一个使用无卷积 Transformer 架构从未标记数据中学习多模态表示的框架。 具体来说,它以原始信号作为输入,并提取足够丰富的多维表示,以有利于各种下游任务。 VATT 借用了 BERT 和 ViT 的确切架构,除了为每种模态分别保留的标记化层和线性投影。 该设计遵循与 ViT 相同的精神,对架构进行最小的更改,以便学习的模型可以将其权重转移到各种框架和任务中。
VATT 将每种模态线性投影到特征向量中,并将其输入到 Transformer 编码器中。 定义语义分层公共空间来考虑不同模态的粒度,并采用噪声对比估计来训练模型。
十三、GPU-Efficient Network
GENet(或 GPU 高效网络)是通过神经架构搜索找到的一系列高效模型。 搜索发生在几种类型的卷积块上,其中包括深度卷积、批量归一化、ReLU 和反向瓶颈结构。
十四、DELG
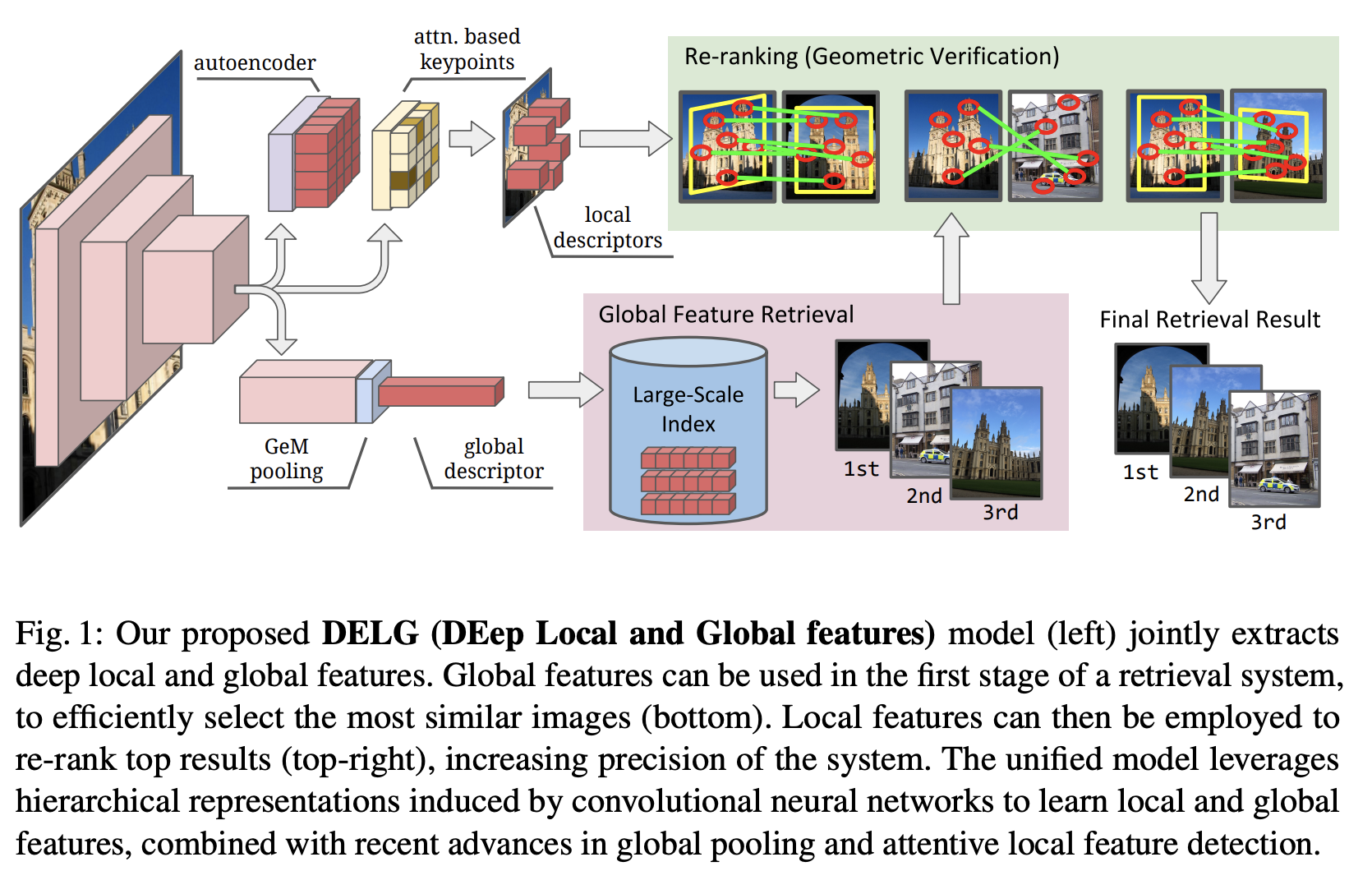
DELG 是一种用于图像检索的卷积神经网络,结合了全局特征的广义均值池和局部特征的细心选择。 通过仔细平衡两个头之间的梯度流,可以端到端地学习整个网络——只需要图像级标签。 这样可以通过在单个模型中提取图像的全局特征、检测到的关键点和局部描述符来进行有效的推理。
该模型是通过利用 CNN 中出现的分层图像表示来实现的,该表示与广义均值池和局部特征检测相结合。 其次,采用卷积自动编码器模块,可以成功学习低维局部描述符。 这可以很容易地集成到统一模型中,并且避免了常用的后处理学习步骤(例如 PCA)的需要。 最后,使用一个程序,仅使用图像级监督即可对所提出的模型进行端到端训练。 这需要在反向传播期间仔细控制全局和本地网络头之间的梯度流,以避免破坏所需的表示。
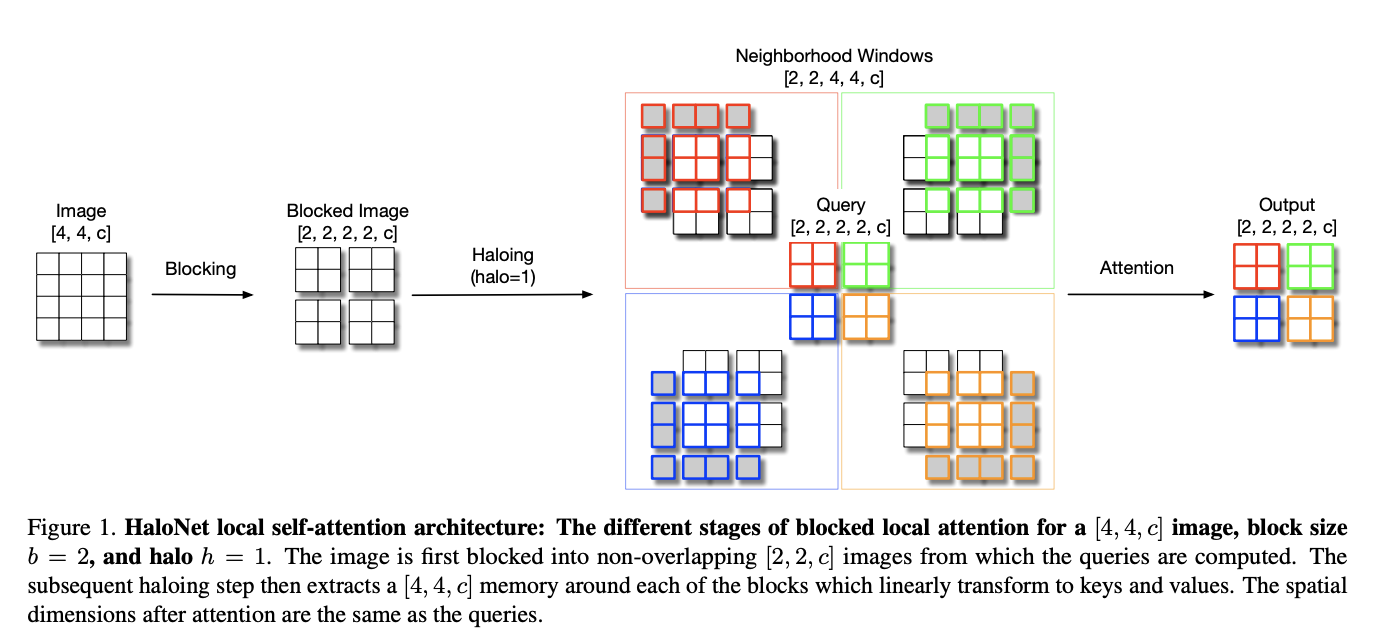
十五、HaloNet
HaloNet 是一种基于自注意力的模型,用于高效图像分类。 它依赖于局部自注意力架构,可以有效地映射到带有光环的现有硬件。 该公式打破了平移等方差,但作者观察到,与常规自注意力中使用的集中局部自注意力相比,它提高了吞吐量和准确性。 该方法还利用跨步自注意力下采样操作进行多尺度特征提取。