文章目录
一、Diffusion
扩散模型通过逐渐去除信号中的噪声来生成样本,其训练目标可以表示为重新加权的变分下界(https://arxiv.org/abs/2006.11239)。
二、Guided Language to Image Diffusion for Generation and Editing(GLIDE)
GLIDE 是一种基于文本引导扩散模型的生成模型,可生成更加逼真的图像。 引导扩散应用于文本条件图像合成,并且该模型能够处理自由形式的提示。 扩散模型使用文本编码器来调节自然语言描述。 除了零样本生成之外,该模型还提供编辑功能,允许迭代改进模型样本以匹配更复杂的提示。 该模型经过微调以执行图像修复。
三、classifier-guidance
四、Blended Diffusion
混合扩散可实现自然图像的零样本本地文本引导图像编辑。 给定输入图像,输入掩码和目标指导文本该方法能够改变图像内与引导文本相对应的遮蔽区域。 未遮蔽的区域保持不变。

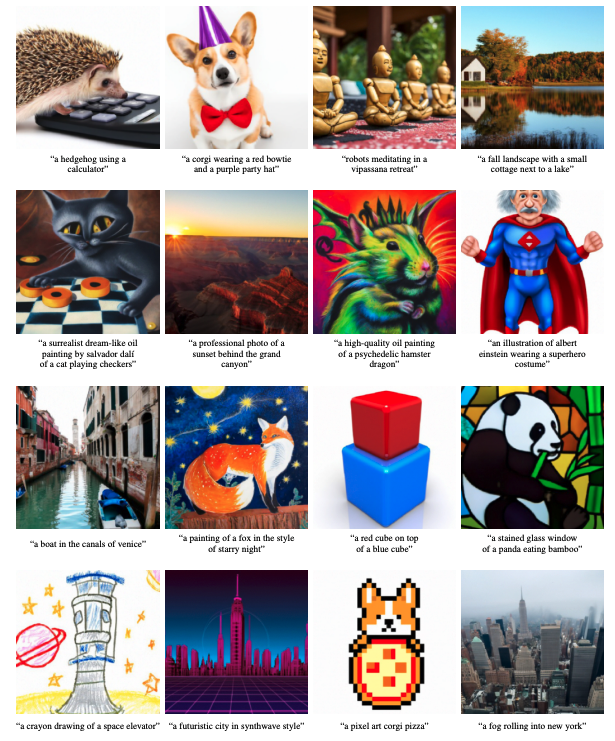
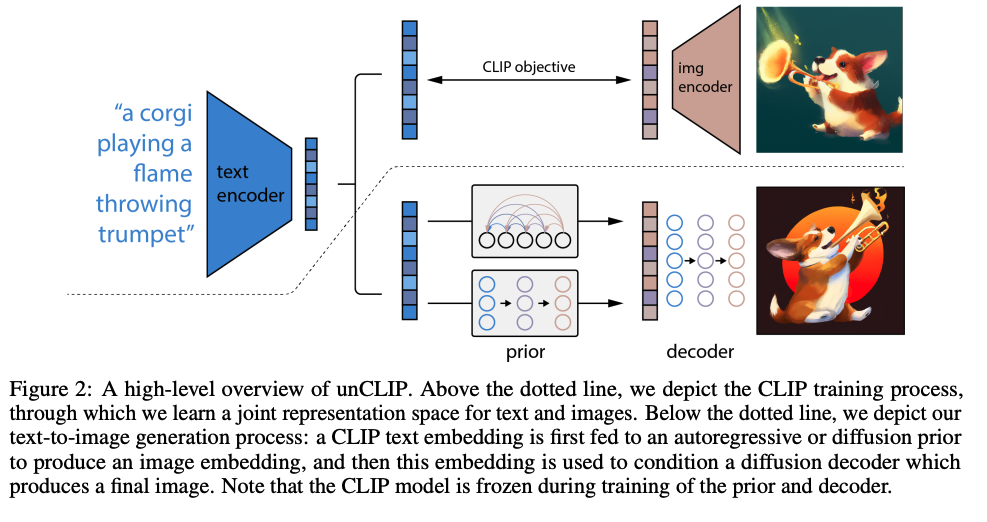
五、DALL·E 2
DALL·E 2 是一种生成式文本到图像模型,由两个主要组件组成:先验模型(在给定文本标题的情况下生成 CLIP 图像嵌入)和解码器(根据图像嵌入生成图像)。
六、AltDiffusion
在这项工作中,我们提出了一种概念上简单而有效的方法来训练强大的双语多模态表示模型。 从OpenAI发布的预训练多模态表示模型CLIP开始,我们将其文本编码器更换为预训练的多语言文本编码器XLM-R,并通过由教师学习和对比学习组成的两阶段训练模式来对齐语言和图像表示。 我们通过评估广泛的任务来验证我们的方法。 我们在 ImageNet-CN、Flicker30k-CN 和 COCO-CN 等一系列任务上设置了新的最先进性能。 此外,我们在几乎所有任务上都使用 CLIP 获得了非常接近的性能,这表明人们可以简单地改变 CLIP 中的文本编码器以获得扩展功能,例如多语言理解。 我们的模型和代码可在 https://github.com/FlagAI-Open/FlagAI 获取。

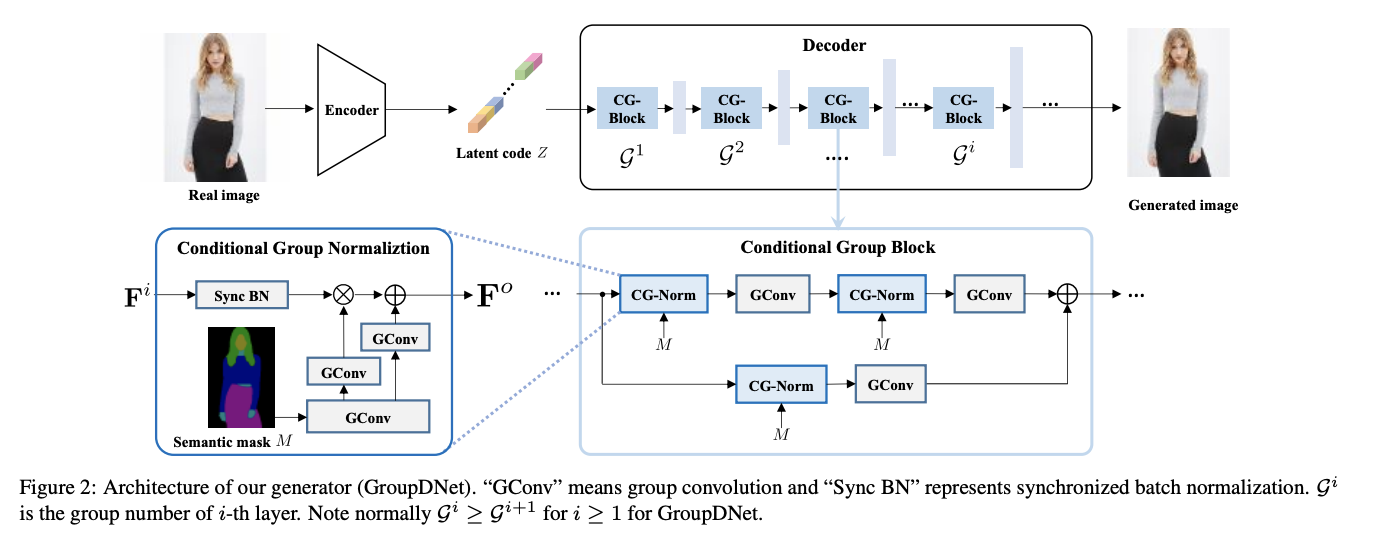
七、Group Decreasing Network
组递减网络(Group Decreasing Network,简称 GroupDNet)是一种用于多模态图像合成的卷积神经网络。 GroupDNet 包含 1 个编码器和 1 个解码器。 受 VAE 和 SPADE 思想的启发,编码器产生一个潜在的代码应该遵循高斯分布在训练中。 测试时,编码器被丢弃。 从高斯分布中随机采样的代码替代。 为了实现这一点,使用重新参数化技巧在训练期间启用可微分的损失函数。 具体来说,编码器通过两个全连接层预测均值向量和方差向量来表示编码分布。 编码分布和高斯分布之间的差距可以通过施加 KL 散度损失来最小化。
八、Make-A-Scene
Make-A-Scene 是一种文本到图像的方法,它 (i) 实现了一种与场景形式的文本互补的简单控制机制,(ii) 引入了通过采用关键领域特定知识来改进标记化过程的元素 图像区域(面部和显着物体),以及 (iii) 针对变压器用例采用无分类器指导。

九、Iterative Inpainting
十、Differential Diffusion
差分扩散是图像到图像扩散模型的增强,它增加了通过变化图控制应用于每个图像片段的变化量的能力。