文章目录
一、MnasNet
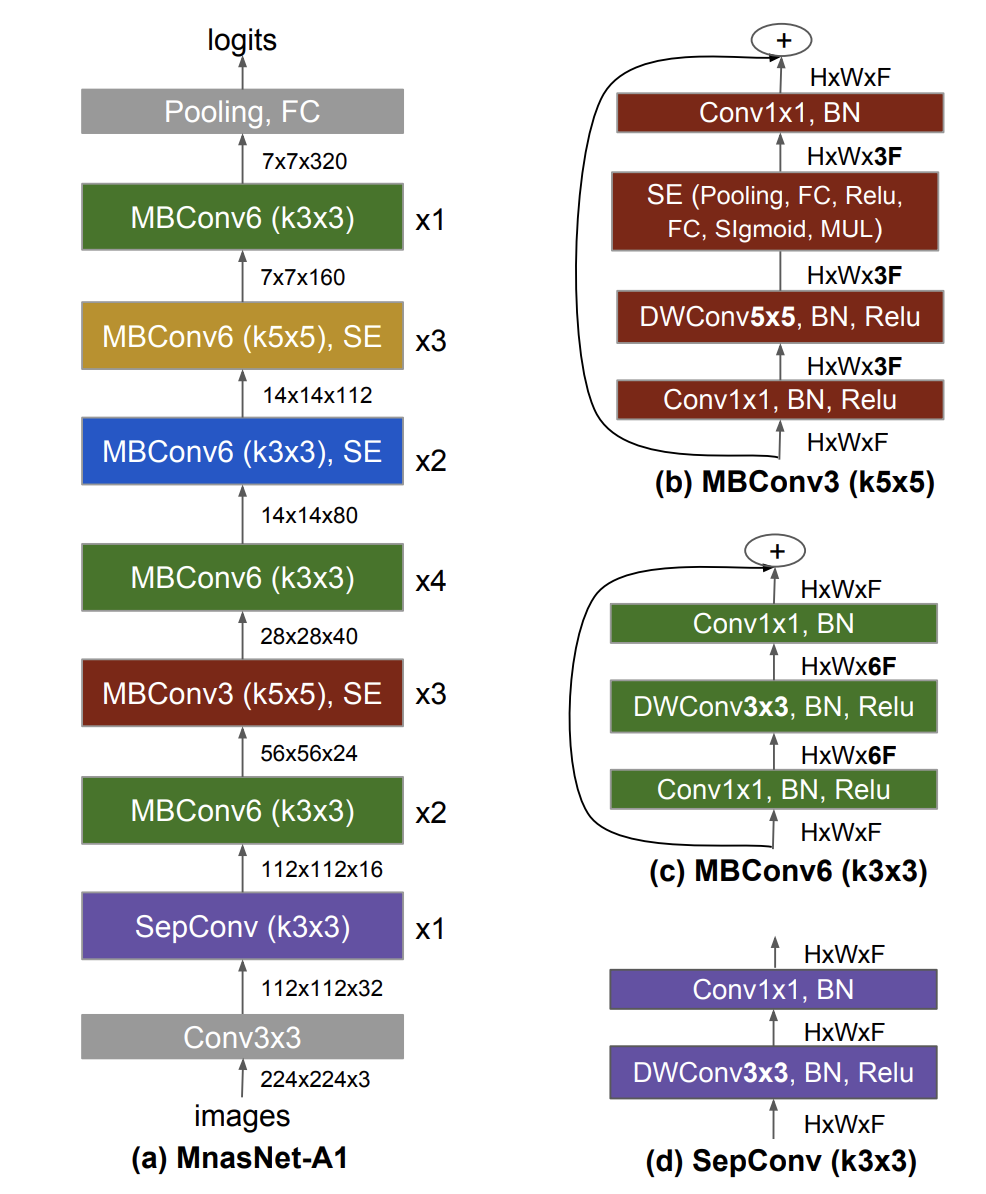
MnasNet 是一种针对移动设备优化的卷积神经网络,是通过移动神经架构搜索发现的,它明确地将模型延迟纳入主要目标,以便搜索可以识别在准确性和延迟之间实现良好权衡的模型。 主要构建块是反转残差块(来自 MobileNetV2)。
二、GhostNet
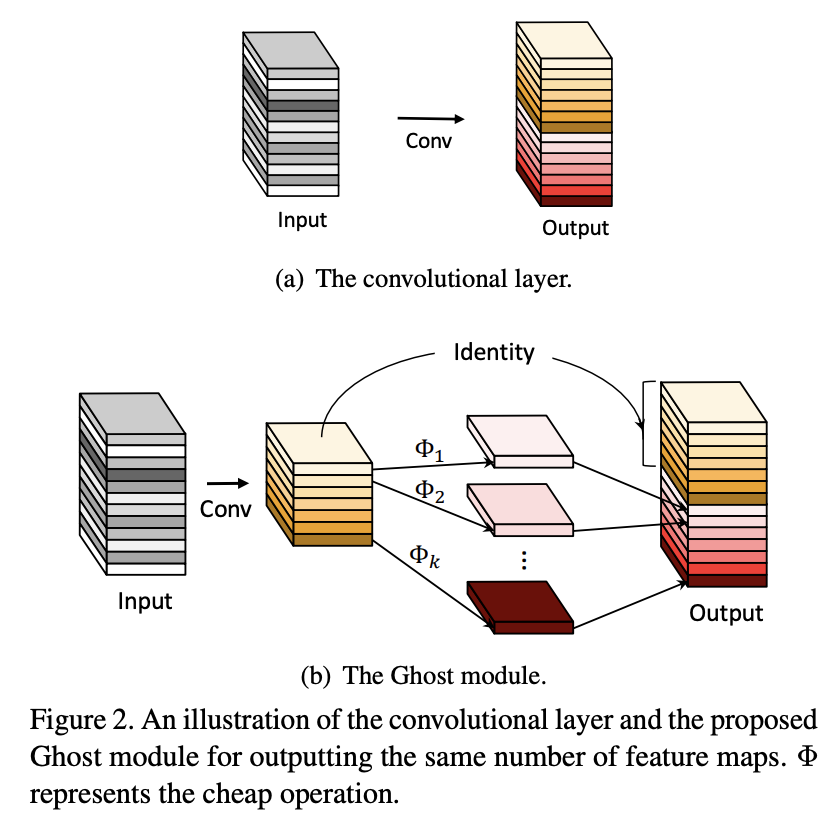
GhostNet 是一种使用 Ghost 模块构建的卷积神经网络,旨在通过使用更少的参数生成更多的特征(从而提高效率)。
GhostNet主要由一堆Ghost瓶颈组成,以Ghost模块为构建块。 第一层是具有 16 个滤波器的标准卷积层,然后是一系列通道逐渐增加的 Ghost 瓶颈。 这些 Ghost 瓶颈根据其输入特征图的大小分为不同的阶段。 所有 Ghost 瓶颈均采用 stride=1,但每个阶段的最后一个瓶颈均采用 stride=2。 最后利用全局平均池化和卷积层将特征图转换为1280维特征向量以进行最终分类。 挤压和激励(SE)模块也应用于一些幽灵瓶颈中的残留层。
与 MobileNetV3 相比,GhostNet 由于延迟较大而没有使用 Hard-swish 非线性函数。
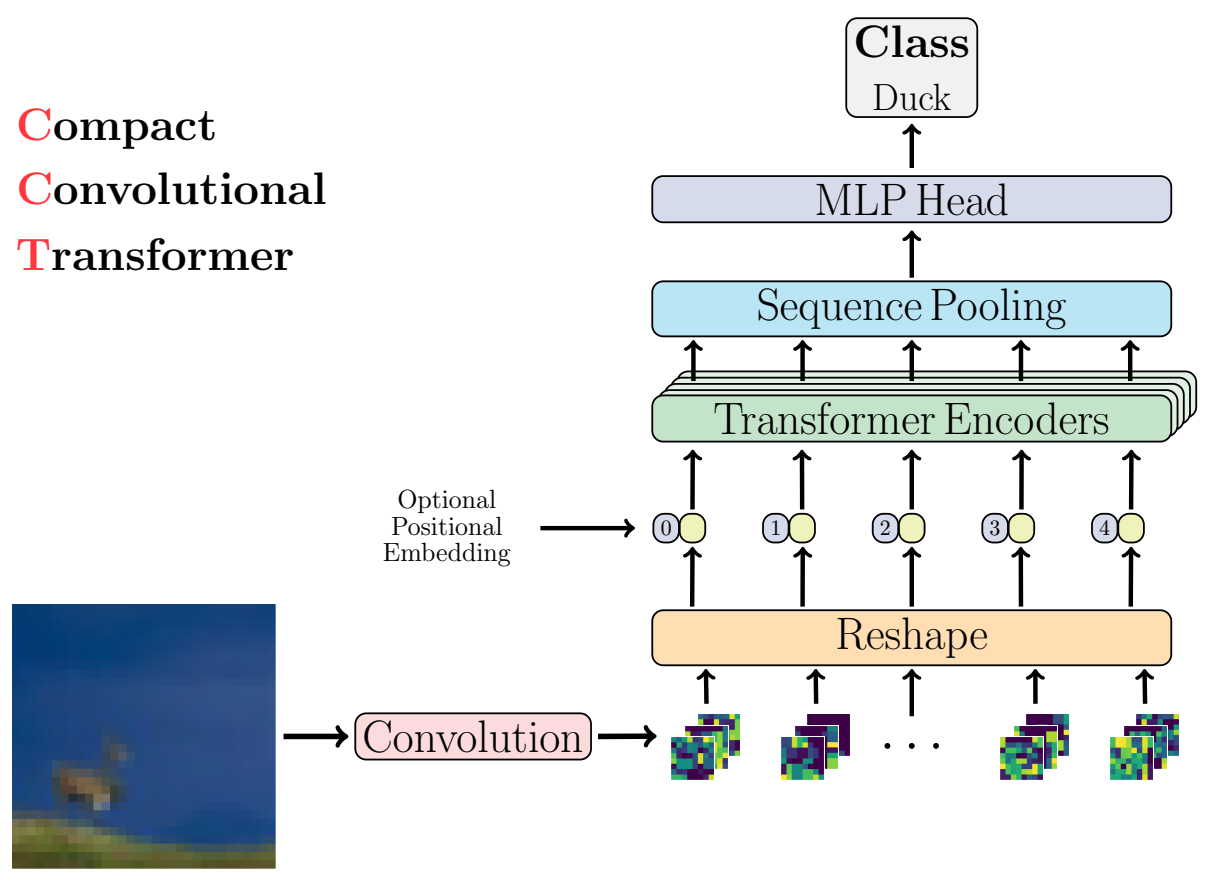
三、Compact Convolutional Transformers(CCT)
紧凑卷积变压器利用序列池并用卷积嵌入替换补丁嵌入,从而实现更好的归纳偏差并使位置嵌入成为可选。 CCT 比 ViT-Lite(较小的 ViT)实现了更好的精度,并增加了输入参数的灵活性。
四、NesT
NesT 堆叠规范的 Transformer 层,对每个图像块独立进行局部自注意力,然后分层“嵌套”它们。 空间相邻块之间的处理信息的耦合是通过每两个层次结构之间所提出的块聚合来实现的。 整体的层次结构可以由两个关键的超参数决定:补丁大小和块层次结构的数量。 每个层次结构内的所有块共享一组参数。 给定图像输入,每个图像都线性投影到嵌入。 所有嵌入都被划分为块并展平以生成最终输入。 每个 Transformer 层均由多头自关注 (MSA) 层组成,后跟具有跳跃连接和层归一化功能的前馈全连接网络 (FFN)。 添加位置嵌入以在馈入块之前对空间信息进行编码。 最后,构建了一个具有块聚合的嵌套层次结构——每四个空间连接的块合并为一个。

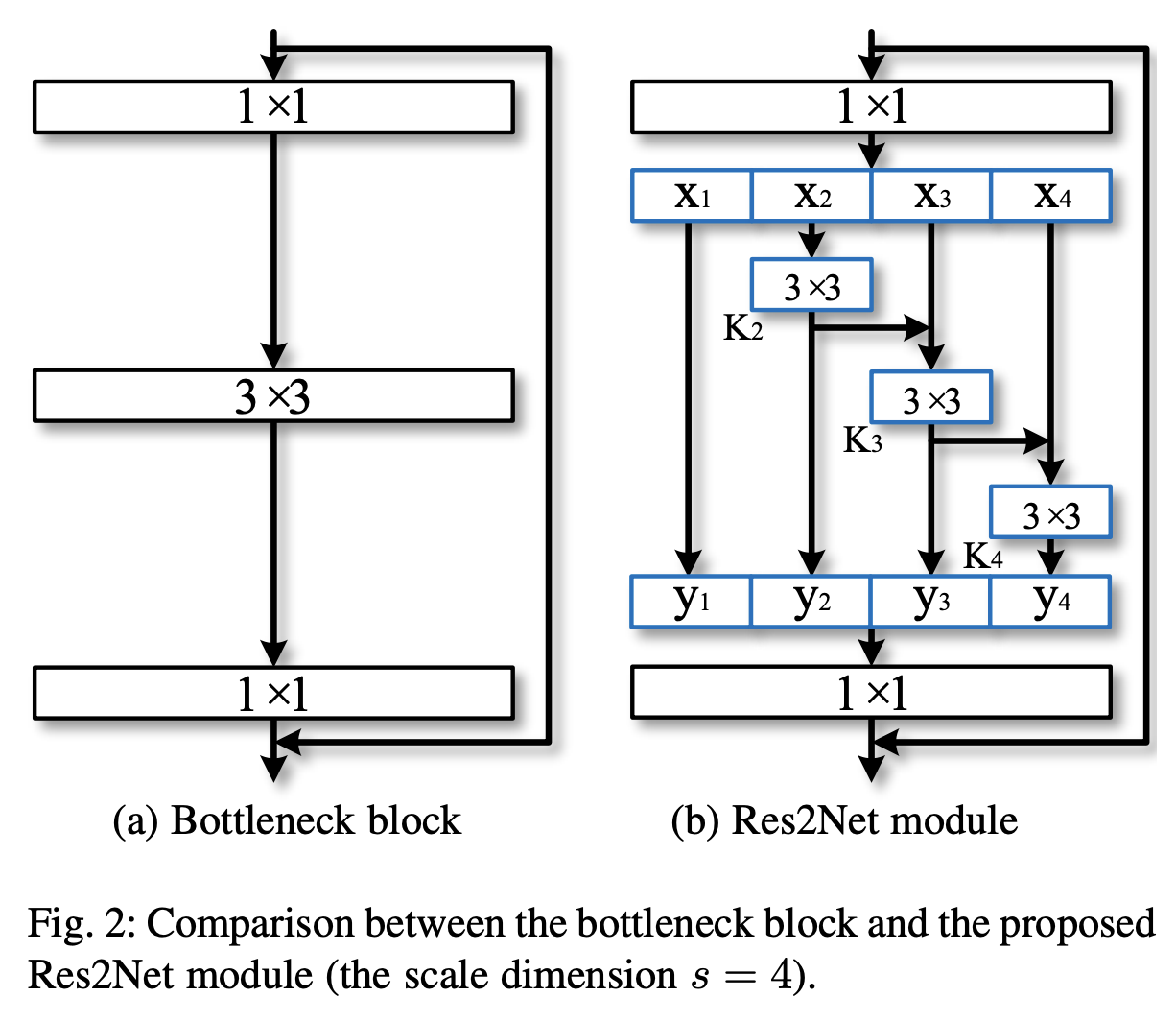
五、Res2Net
Res2Net 是一种采用瓶颈残差块变体的图像模型。 动机是能够表示多个尺度的特征。 这是通过一种新颖的 CNN 构建块实现的,该构建块在单个残差块内构建分层的类残差连接。 这代表了粒度级别的多尺度特征,并增加了每个网络层的感受野范围。
六、EfficientNetV2
EfficientNetV2是一类卷积神经网络,与之前的模型相比,具有更快的训练速度和更好的参数效率。 为了开发这些模型,作者结合了训练感知神经架构搜索和缩放,以共同优化训练速度。 这些模型是从富含新操作(例如 Fused-MBConv)的搜索空间中搜索的。
从架构上来说,主要区别是:
EfficientNetV2 在早期层中广泛使用 MBConv 和新添加的 fused-MBConv。
EfficientNetV2 更喜欢 MBConv 的较小扩展比,因为较小的扩展比往往具有较少的内存访问开销。
EfficientNetV2 更喜欢较小的 3x3 内核尺寸,但它增加了更多层来补偿较小内核尺寸导致的感受野减小。
EfficientNetV2 完全删除了原始 EfficientNet 中的最后一个 stride-1 阶段,这可能是由于其较大的参数大小和内存访问开销。
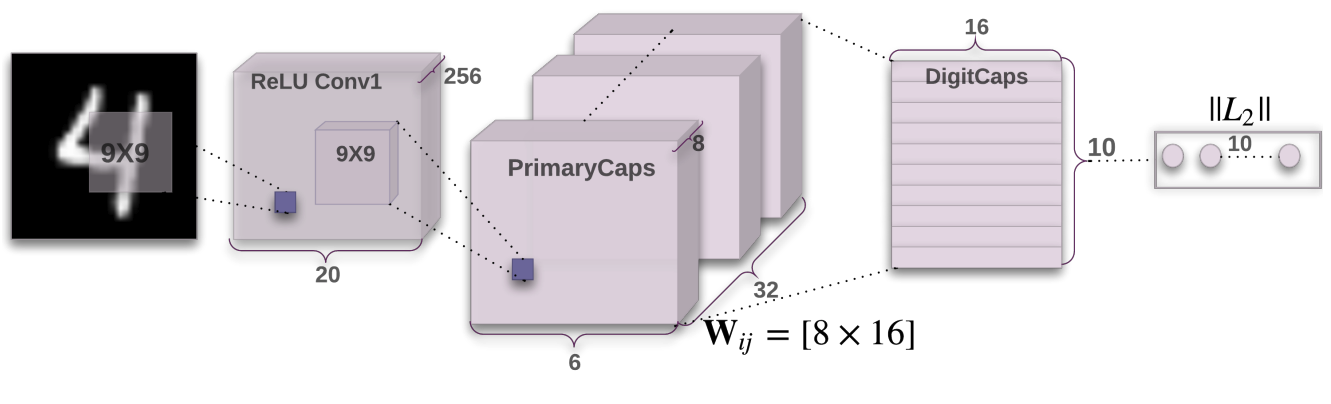
七、Capsule Network
胶囊网络是一种机器学习系统,是一种人工神经网络,可用于更好地建模层次关系。 该方法试图更接近地模仿生物神经组织。
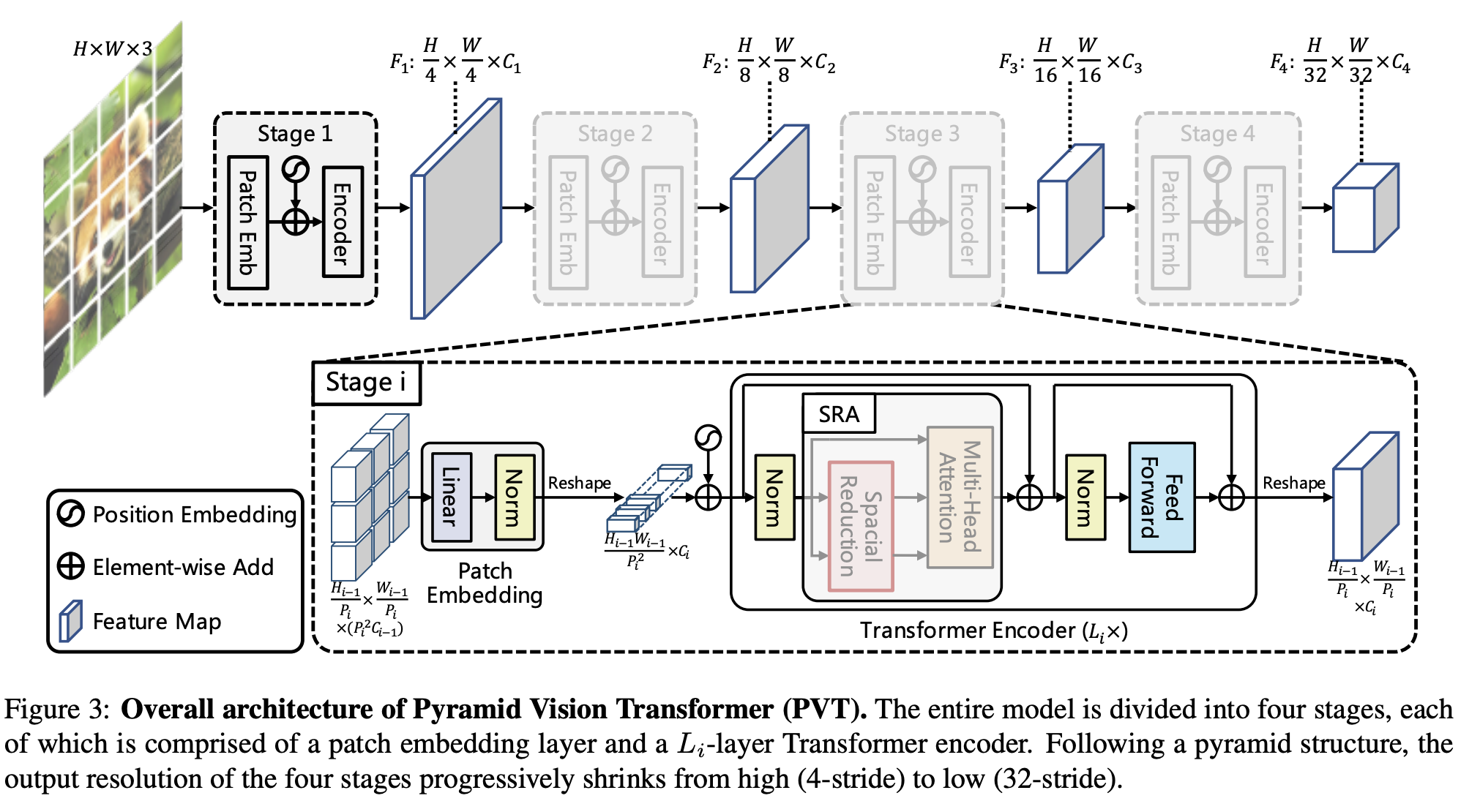
八、Pyramid Vision Transformer
PVT(金字塔视觉变压器)是一种视觉变压器,利用金字塔结构使其成为密集预测任务的有效骨干。 具体来说,它允许使用更细粒度的输入(每个补丁 4 x 4 像素),同时随着 Transformer 的加深而缩小其序列长度,从而降低计算成本。 此外,空间减少注意(SRA)层用于进一步减少学习高分辨率特征时的资源消耗。
整个模型分为四个阶段,每个阶段由一个补丁嵌入层和一个层 Transformer 编码器。 按照金字塔结构,四个阶段的输出分辨率从高(4 步幅)逐渐缩小到低(32 步幅)。
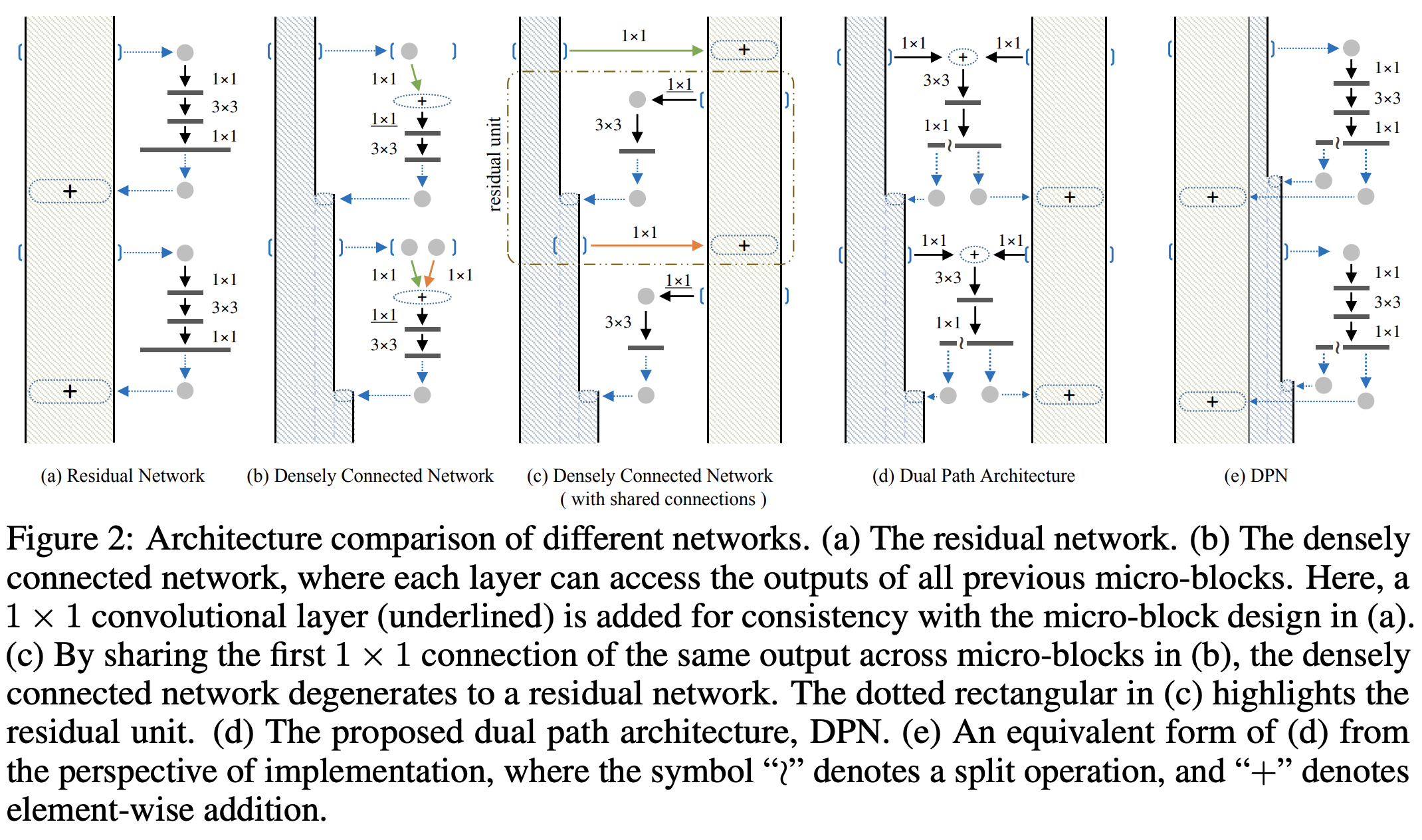
九、Dual Path Network(DPN)
双路径网络(DPN)是一种卷积神经网络,它在内部呈现出一种新的连接路径拓扑。 直觉是 ResNets 支持特征重用,而 DenseNet 支持新特征探索,两者对于学习良好的表示都很重要。 为了享受两种路径拓扑的优势,双路径网络共享通用功能,同时保持通过双路径架构探索新功能的灵活性。
我们制定这样的双路径架构如下:
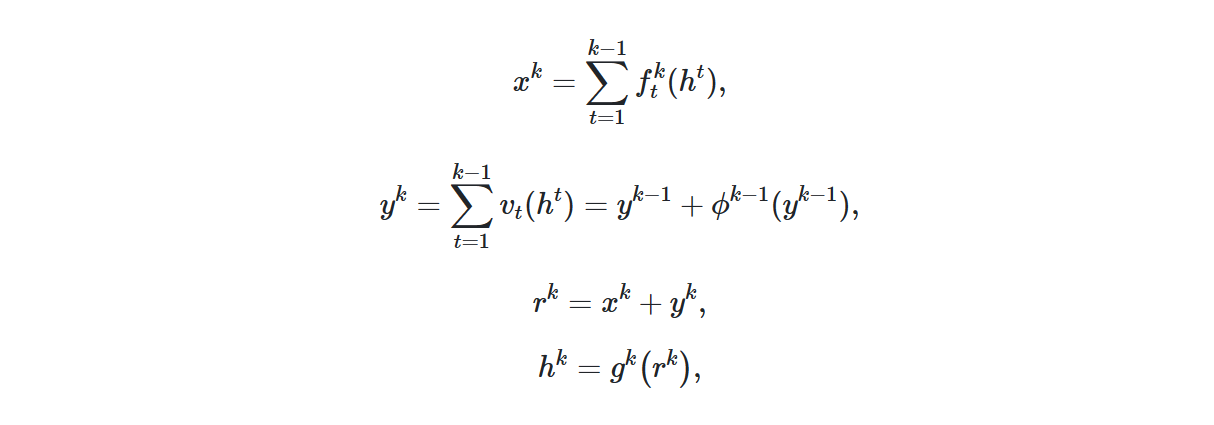
十、Dense Prediction Transformer(DPT)
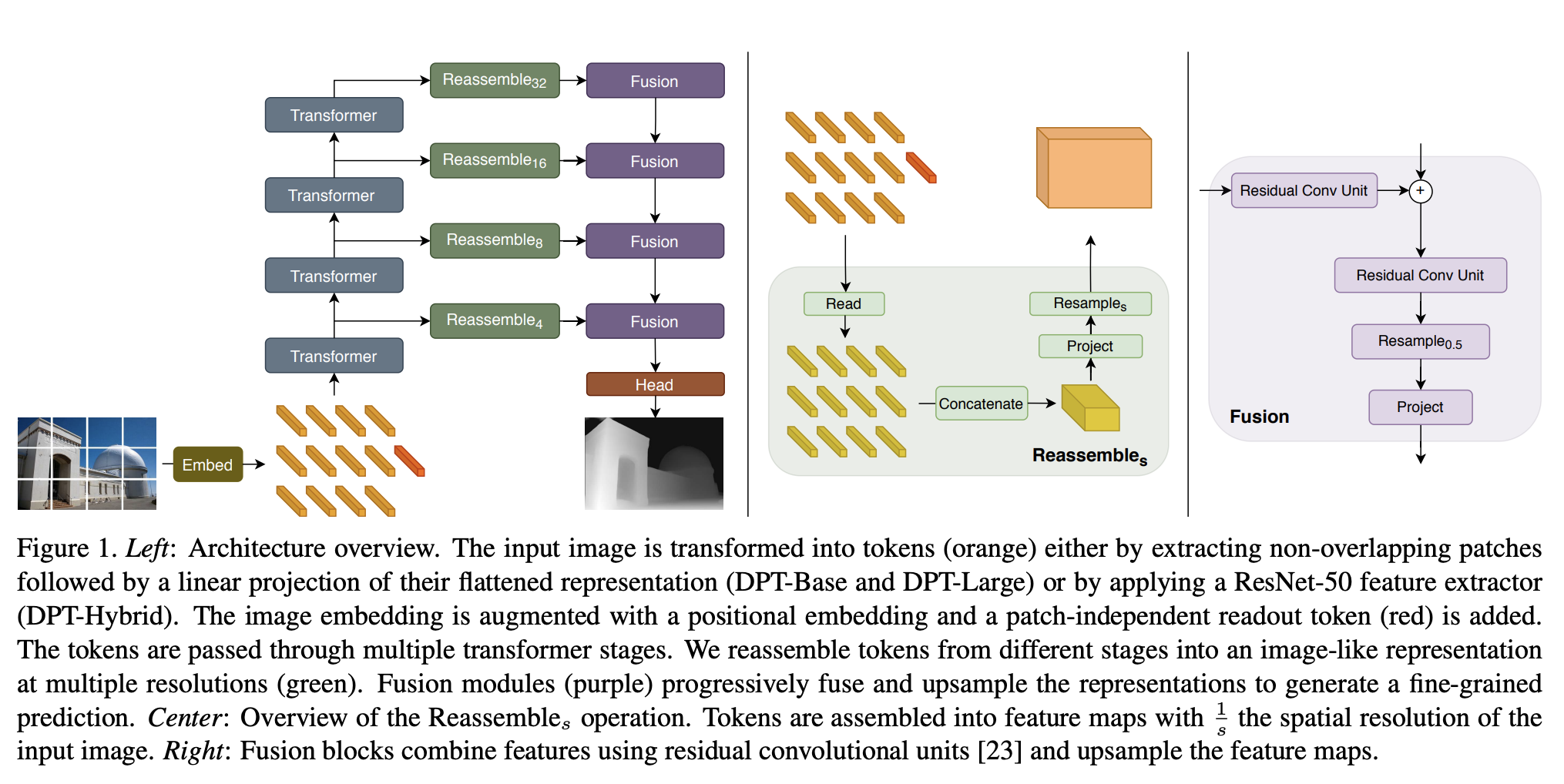
密集预测变压器(DPT)是一种用于密集预测任务的视觉变压器。
通过提取非重叠斑块,然后对其展平表示(DPT-Base 和 DPT-Large)进行线性投影,或者通过应用 ResNet-50 特征提取器(DPT-Hybrid),将输入图像转换为标记(橙色)。 图像嵌入通过位置嵌入得到增强,并添加了与补丁无关的读出标记(红色)。 令牌通过多个变压器阶段。 令牌从不同阶段重新组装成多种分辨率的类似图像的表示(绿色)。 融合模块(紫色)逐步融合和上采样表示以生成细粒度的预测。
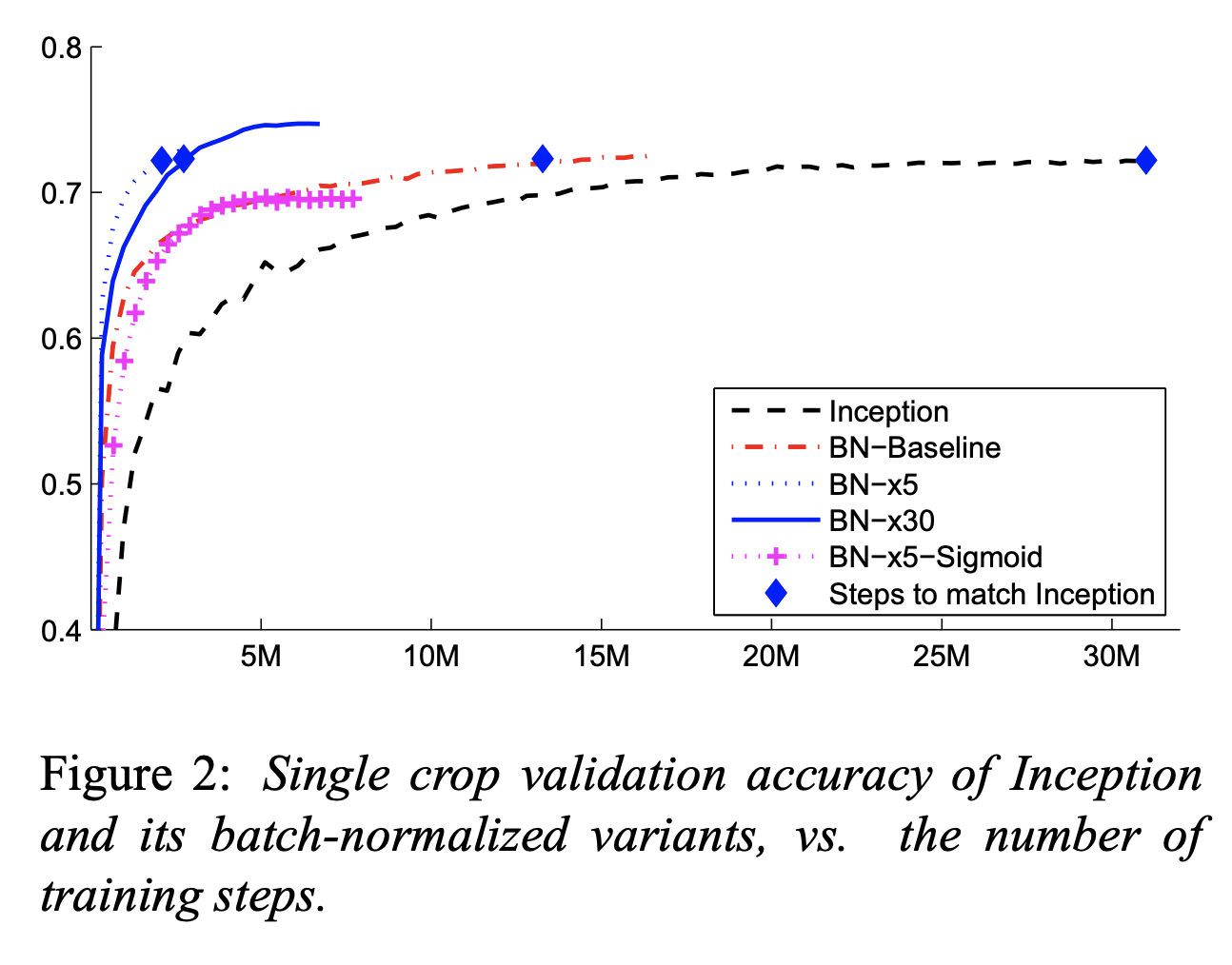
十一、Inception v2
Inception v2 是第二代 Inception 卷积神经网络架构,特别使用批量归一化。 由于批量标准化的好处,其他更改包括删除 dropout 和删除本地响应标准化。
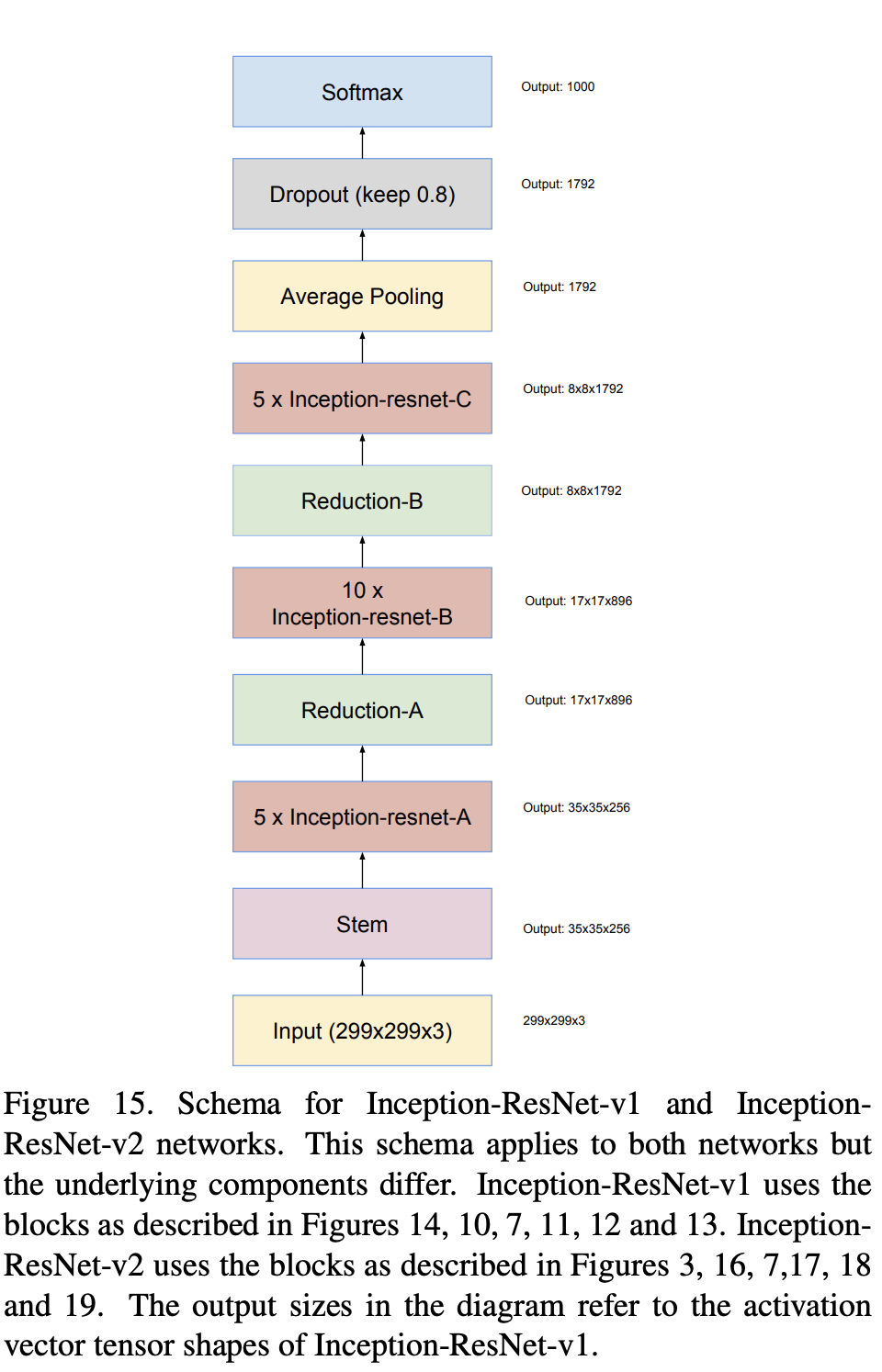
十二、Inception-ResNet-v2
Inception-ResNet-v2 是一种卷积神经架构,它建立在 Inception 系列架构的基础上,但合并了残差连接(取代了 Inception 架构的滤波器级联阶段)。
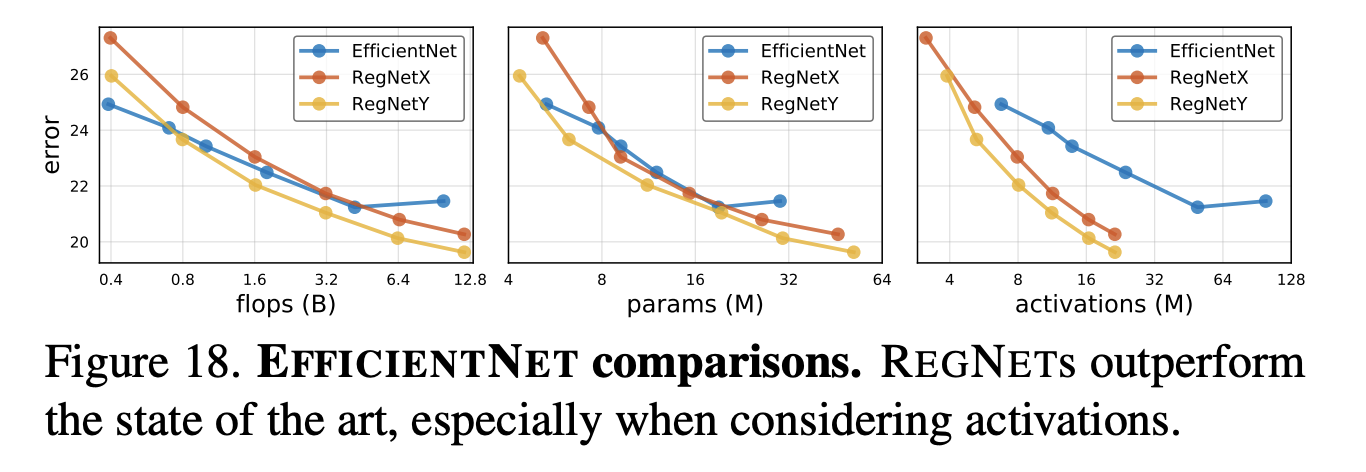
十三、RegNetY

对于 RegNetY,我们做了一项更改,即包含挤压和激励模块。
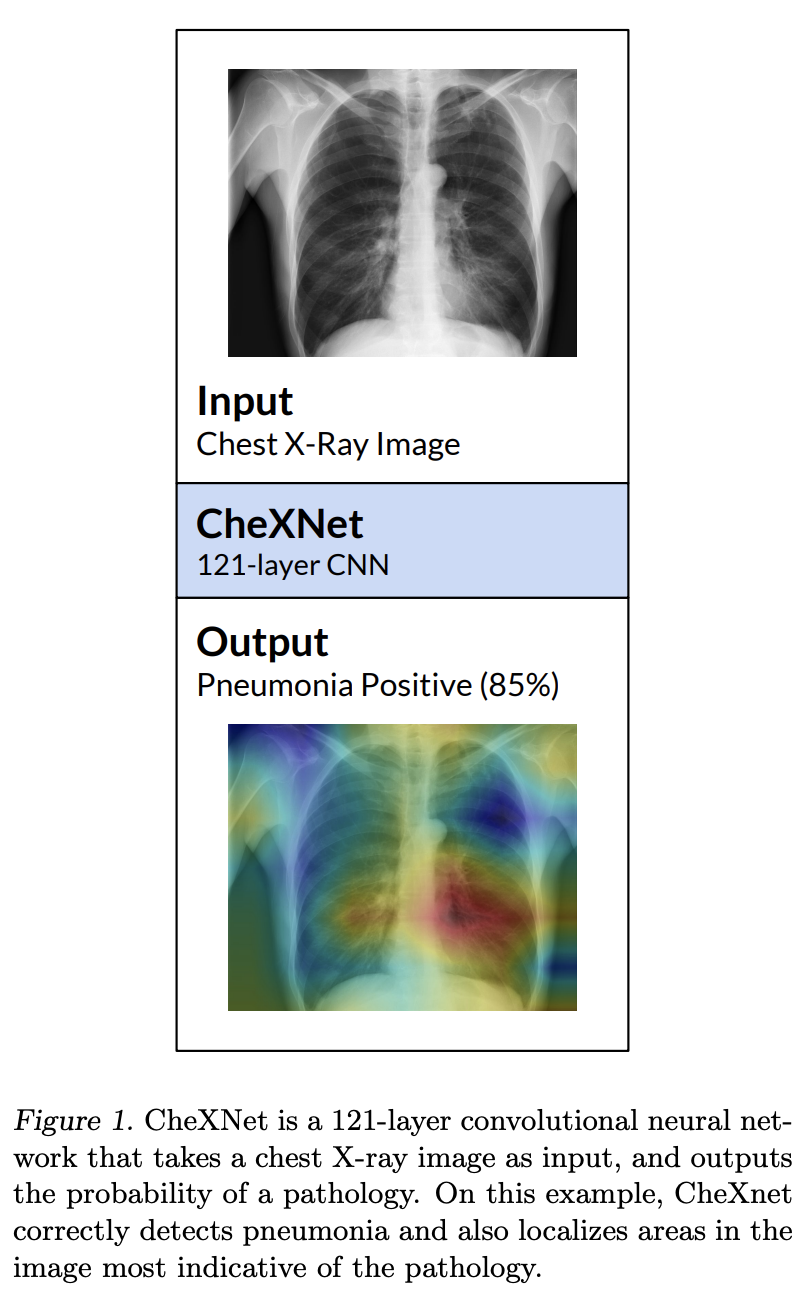
十四、CheXNet
CheXNet 是一个在 ChestX-ray14 上训练的 121 层 DenseNet,用于肺炎检测。
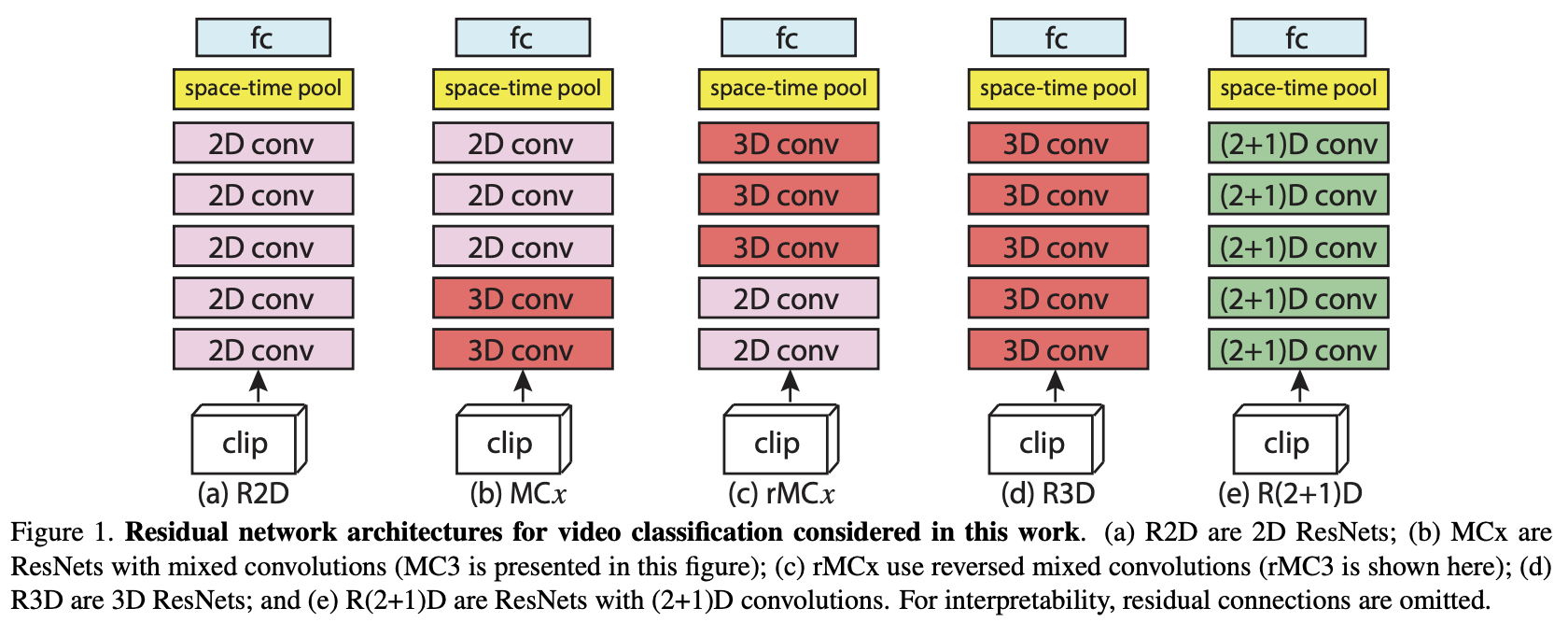
十五、R(2+1)D
R(2+1)D 卷积神经网络是一种用于动作识别的网络,它在 ResNet 启发的架构中采用 R(2+1)D 卷积。 与常规 3D 卷积相比,使用这些卷积可以降低计算复杂性,防止过度拟合,并引入更多非线性,从而可以对更好的函数关系进行建模。