文章目录
一、ShuffleNet Block
ShuffleNet 块是一种图像模型块,它利用通道洗牌操作以及深度卷积来实现高效的架构设计。 它被提议作为 ShuffleNet 架构的一部分。 起点是 ResNets 中的残差块单元,然后使用逐点组卷积和通道洗牌操作对其进行修改。

二、Efficient Spatial Pyramid
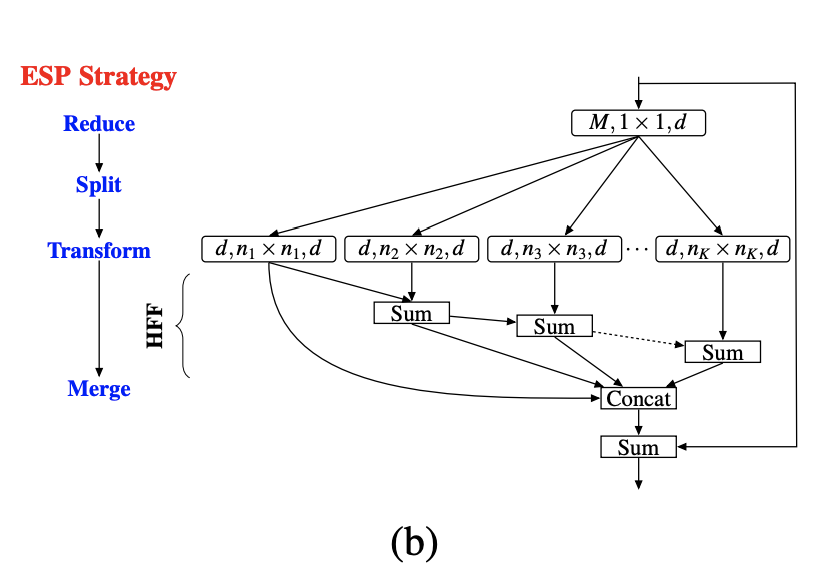
高效空间金字塔 (ESP) 是基于分解原理的图像模型块,它将标准卷积分解为两个步骤:(1) 逐点卷积和 (2) 扩张卷积的空间金字塔。 逐点卷积有助于减少计算量,而扩张卷积的空间金字塔对特征图进行重新采样,以从大的有效感受野中学习表示。 与 ResNeXt 模块和 Inception 模块等其他图像模块相比,这可以提高效率。
三、Hourglass Module
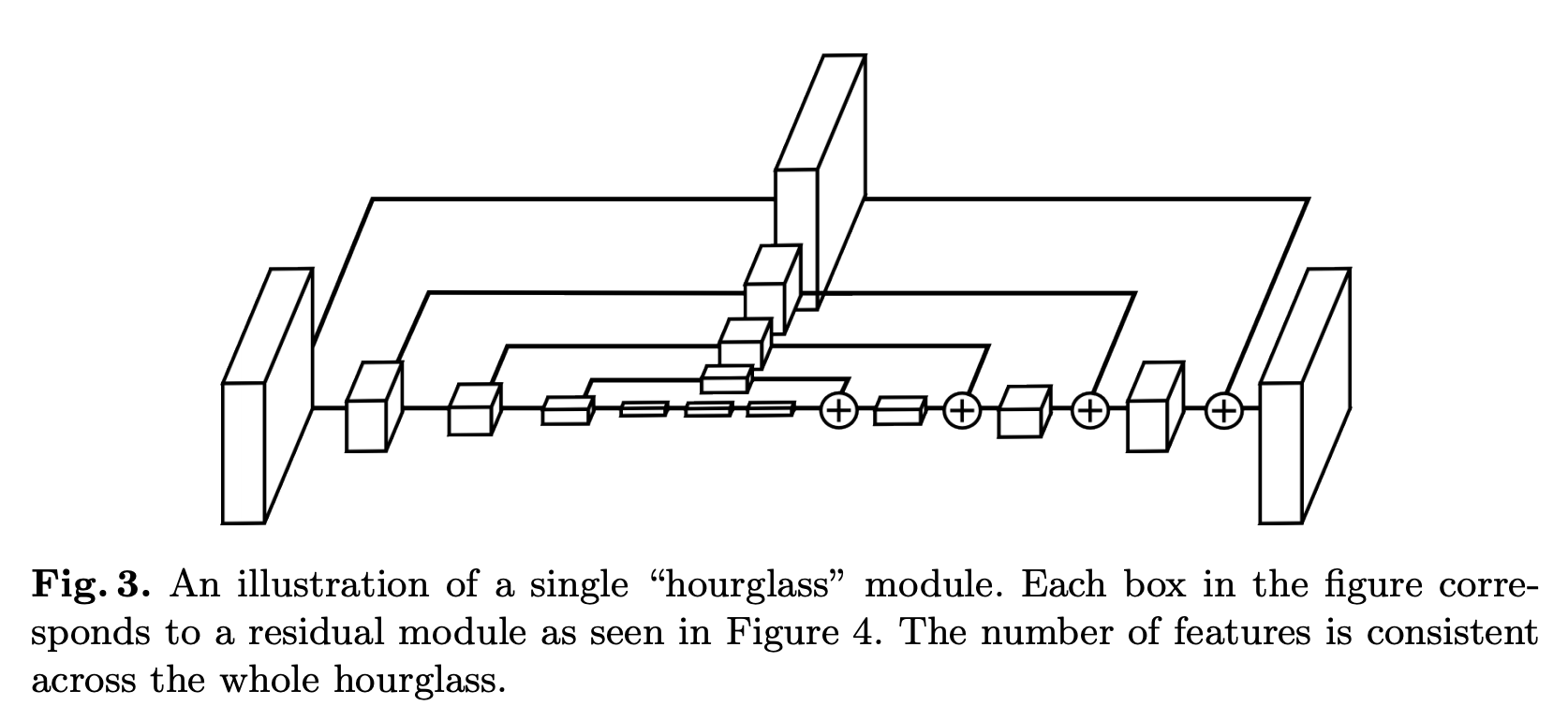
沙漏模块是一个图像块模块,主要用于姿态估计任务。 沙漏设计的动机是捕捉各个尺度的信息的需要。 虽然局部证据对于识别面部和手等特征至关重要,但最终的姿势估计需要对全身有连贯的理解。 人的方向、四肢的排列以及相邻关节的关系是在图像中的不同尺度下最好识别的众多线索之一。 沙漏是一种简单、最小的设计,能够捕获所有这些特征并将它们组合在一起以输出像素级预测。
网络必须有某种机制来有效地处理和整合跨尺度的特征。 Hourglass 使用具有跳跃层的单个管道来保留每个分辨率的空间信息。 网络达到 4x4 像素的最低分辨率,允许应用更小的空间滤波器来比较图像整个空间的特征。
沙漏的设置如下:卷积层和最大池化层用于将特征处理至非常低的分辨率。 在每个最大池化步骤中,网络会分支并以原始预池化分辨率应用更多卷积。 达到最低分辨率后,网络开始自上而下的上采样序列和跨尺度的特征组合。 为了汇集两个相邻分辨率的信息,我们对较低分辨率进行最近邻上采样,然后对两组特征进行元素相加。 沙漏的拓扑是对称的,因此对于向下的每一层,都有一个相应的向上层。
达到网络的输出分辨率后,应用两轮连续的 1x1 卷积来产生最终的网络预测。 网络的输出是一组热图,其中对于给定的热图,网络预测每个像素处存在关节的概率。
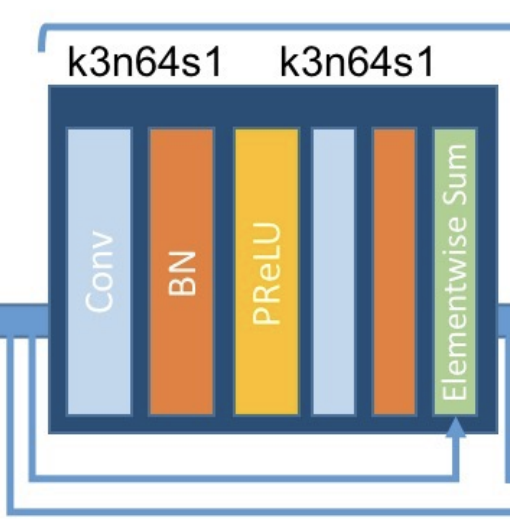
四、SRGAN Residual Block
SRGAN Residual Block是SRGAN生成器中用于图像超分辨率的残差块。 它与标准残差块类似,尽管它使用 PReLU 激活函数来帮助训练(防止 GAN 训练期间出现稀疏梯度)。
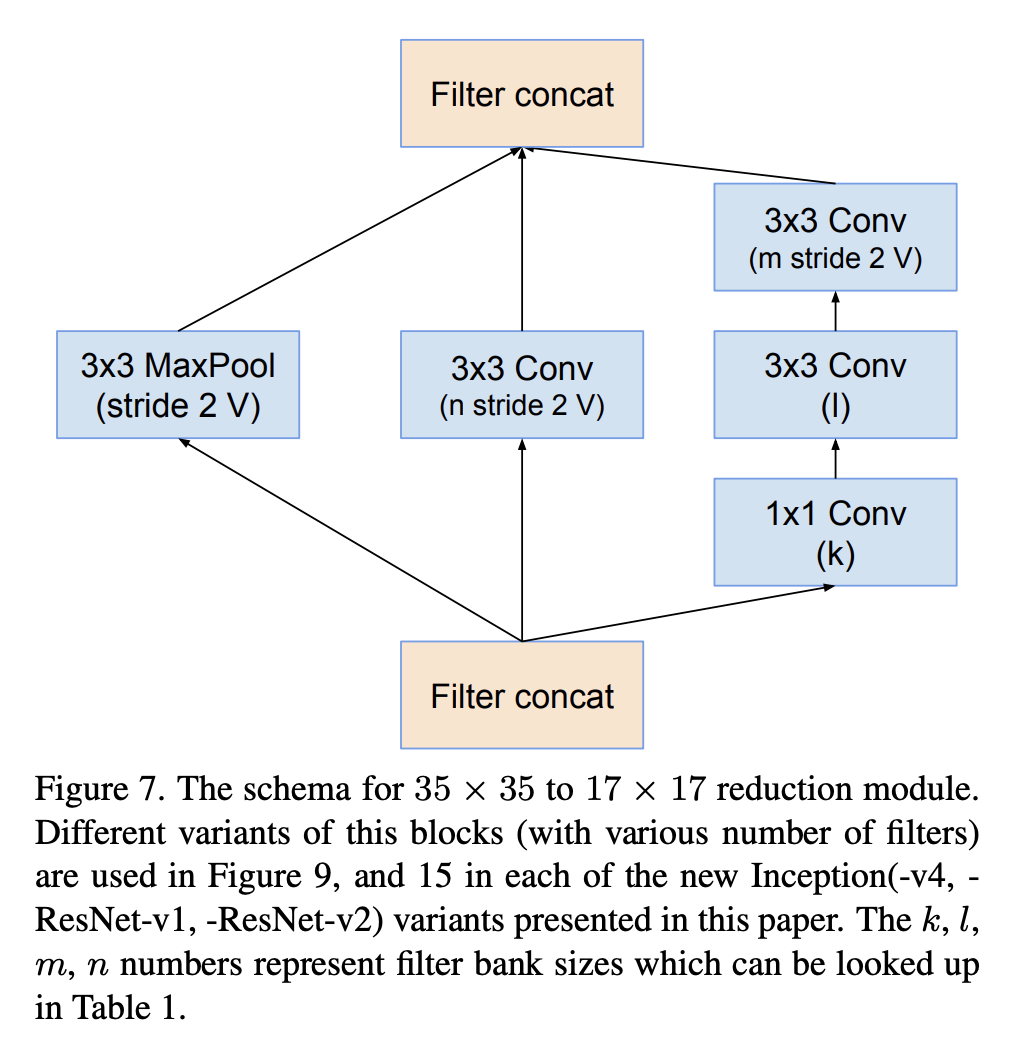
五、Reduction-A
Reduction-A 是 Inception-v4 架构中使用的图像模型块。
六、Ghost Module
Ghost 模块是卷积神经网络的图像块,旨在通过使用更少的参数生成更多的特征。 具体来说,深度神经网络中的普通卷积层分为两部分。 第一部分涉及普通卷积,但其总数是受控制的。 给定第一部分的内在特征图,应用一系列简单的线性运算来生成更多特征图。



七、ENet Initial Block
ENet初始块是ENet语义分割架构中使用的图像模型块。 Max Pooling 使用不重叠的 2 × 2 窗口进行,卷积有 13 个滤波器,串联后总计达 16 个特征图。 这很大程度上受到了 Inception 模块的启发。
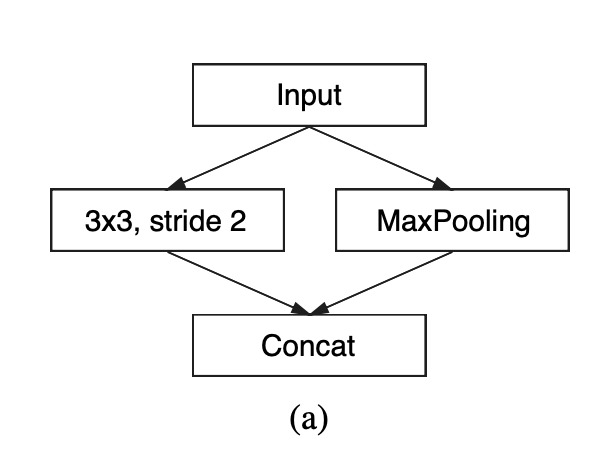
八、ENet Bottleneck
ENet Bottleneck 是 ENet 语义分割架构中使用的图像模型块。 每个块由三个卷积层组成:降维的 1 × 1 投影、主卷积层和 1 × 1 扩展。 我们将 Batch Normalization 和 PReLU 放置在所有卷积之间。 如果瓶颈是下采样,则将最大池化层添加到主分支。 此外,第一个 1 × 1 投影被替换为在两个维度上步长均为 2 的 2 × 2 卷积。 我们对激活进行零填充,以匹配特征图的数量。

九、ENet Dilated Bottleneck
ENet Dilated Bottleneck 是 ENet 语义分割架构中使用的图像模型块。 它与常规 ENet Bottleneck 相同,但采用扩张卷积。
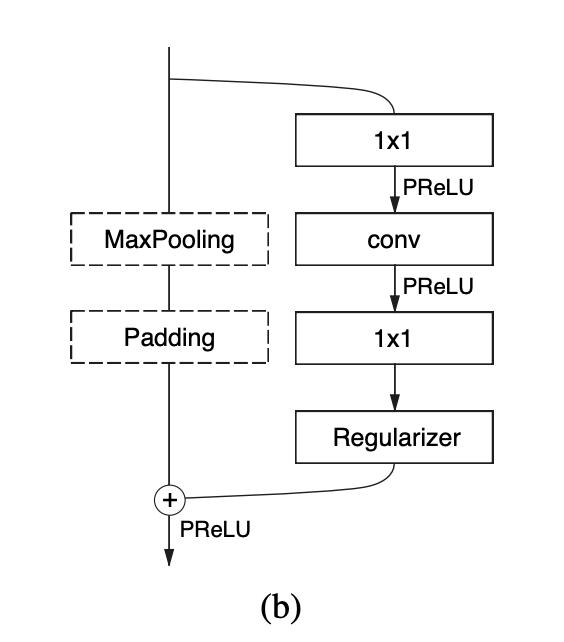
十、Res2Net Block
Res2Net 块是一种图像模型块,可在单个残差块内构建分层的类残差连接。 它被提议作为 Res2Net CNN 架构的一部分。
该块表示粒度级别的多尺度特征,并增加每个网络层的感受野范围。 这过滤器通道被替换为一组较小的过滤器组,每个过滤器组具有渠道。 这些较小的滤波器组以类似分层残差的方式连接,以增加输出特征可以表示的尺度数量。 具体来说,我们将输入特征图分为几组。 一组过滤器首先从一组输入特征图中提取特征。 然后,前一组的输出特征与另一组输入特征图一起发送到下一组过滤器。
这个过程重复几次,直到处理完所有输入特征图。 最后,将所有组的特征图连接起来并发送到另一组过滤器将信息完全融合。 随着输入特征转换为输出特征的任何可能路径,每当它通过一个过滤器,由于组合效应而产生许多等效的特征尺度。
思考这些块的一种方式是,它们除了现有的深度、宽度和基数维度之外,还暴露了新的维度、规模。
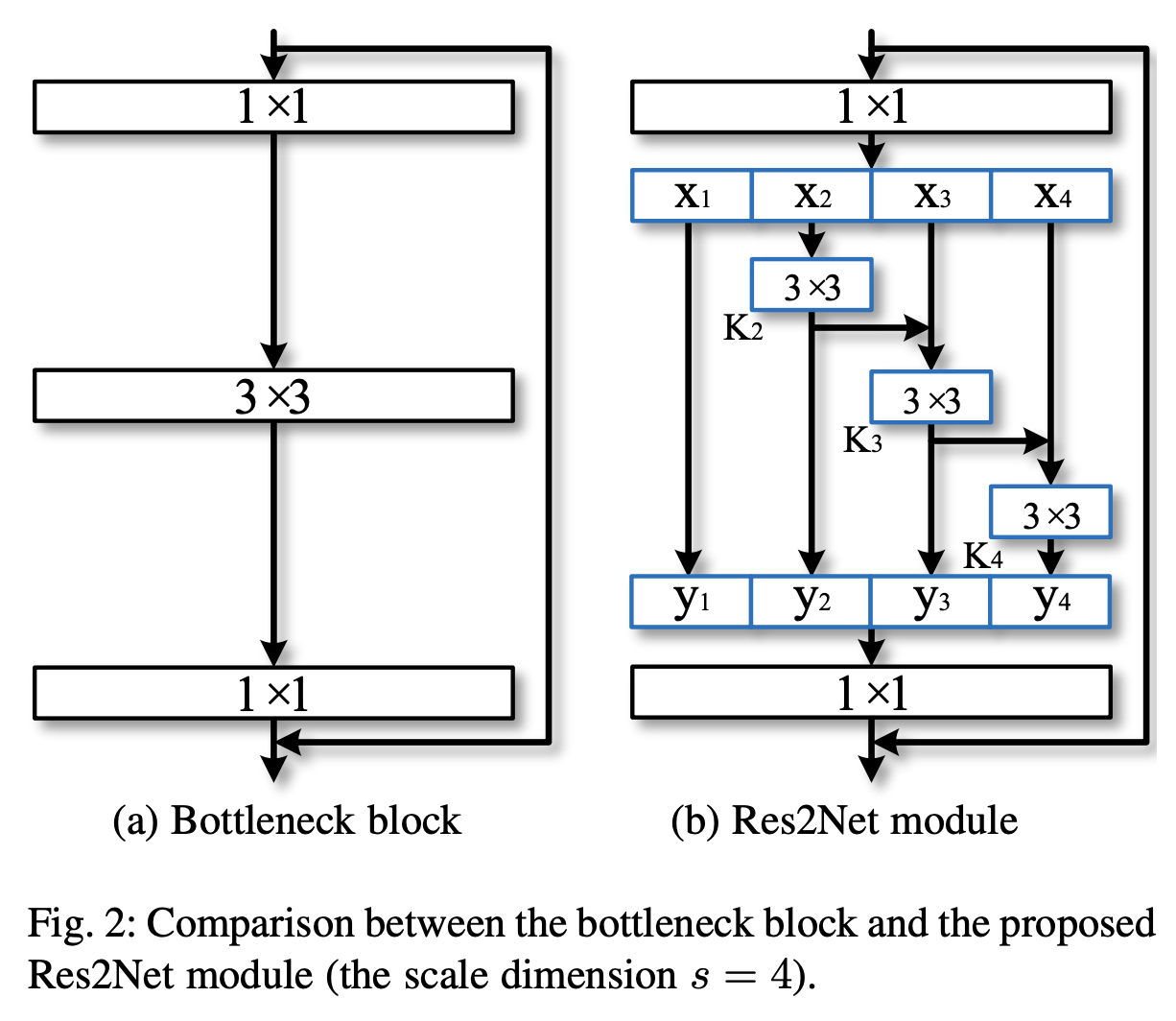
十一、Ghost Bottleneck
Ghost BottleNeck 是一个跳过连接块,类似于 ResNet 中的基本残差块,其中集成了多个卷积层和快捷方式,但改为堆叠 Ghost 模块(两个堆叠的 Ghost 模块)。 它被提议作为 GhostNet CNN 架构的一部分。
第一个 Ghost 模块充当扩展层,增加通道数量。 输出通道数与输入通道数之比称为扩展比。 第二个 Ghost 模块减少了通道数量以匹配快捷路径。 然后将快捷方式连接在这两个 Ghost 模块的输入和输出之间。 批量归一化 (BN) 和 ReLU 非线性在每一层之后应用,但按照 MobileNetV2 的建议,在第二个 Ghost 模块之后不使用 ReLU。 上述 Ghost 瓶颈是针对 stride=1 的情况。 对于stride=2的情况,捷径由下采样层实现,并在两个Ghost模块之间插入stride=2的深度卷积。 实际上,这里的 Ghost 模块中的主要卷积是逐点卷积,以提高其效率。
十二、ShuffleNet V2 Block
huffleNet V2 Block 是 ShuffleNet V2 架构中使用的图像模型块,其中速度是优化的指标(而不是像 FLOPs 这样的间接指标)。 它使用一个称为通道分割的简单运算符。 在每个单元的开始,输入
特征通道分为两个分支,分别。 G3 之后,一个分支仍然作为标识。 另一个分支由具有相同输入和输出通道的三个卷积组成,以满足 G1。 他们俩与原始的 ShuffleNet 不同,卷积不再是分组的。 这部分是为了遵循 G2,部分是因为分割操作已经产生了两个组。 卷积后,两个分支被连接起来。 因此,通道数保持不变(G1)。 然后使用与 ShuffleNet 中相同的“通道洗牌”操作来实现两个分支之间的信息通信。
通道分割背后的动机是使用逐点组卷积和瓶颈结构的替代架构会导致内存访问成本增加。 此外,更多的网络碎片与组卷积会降低并行性(对 GPU 不太友好),并且逐元素加法操作虽然具有较低的 FLOP,但具有较高的内存访问成本。 通道分割是一种替代方案,我们可以维护大量等宽的通道(等宽可以最大限度地减少内存访问成本),而无需使用密集的卷积或太多的组。

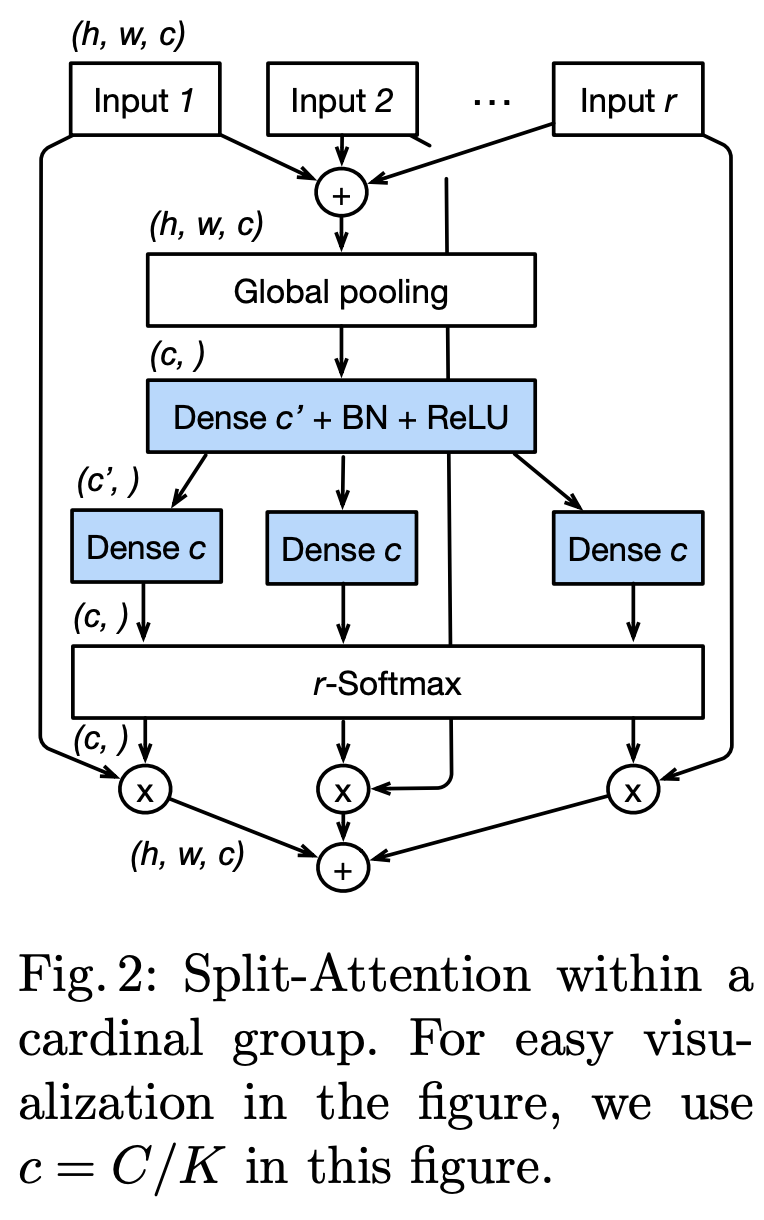
十三、Split Attention


十四、Selective Kernel
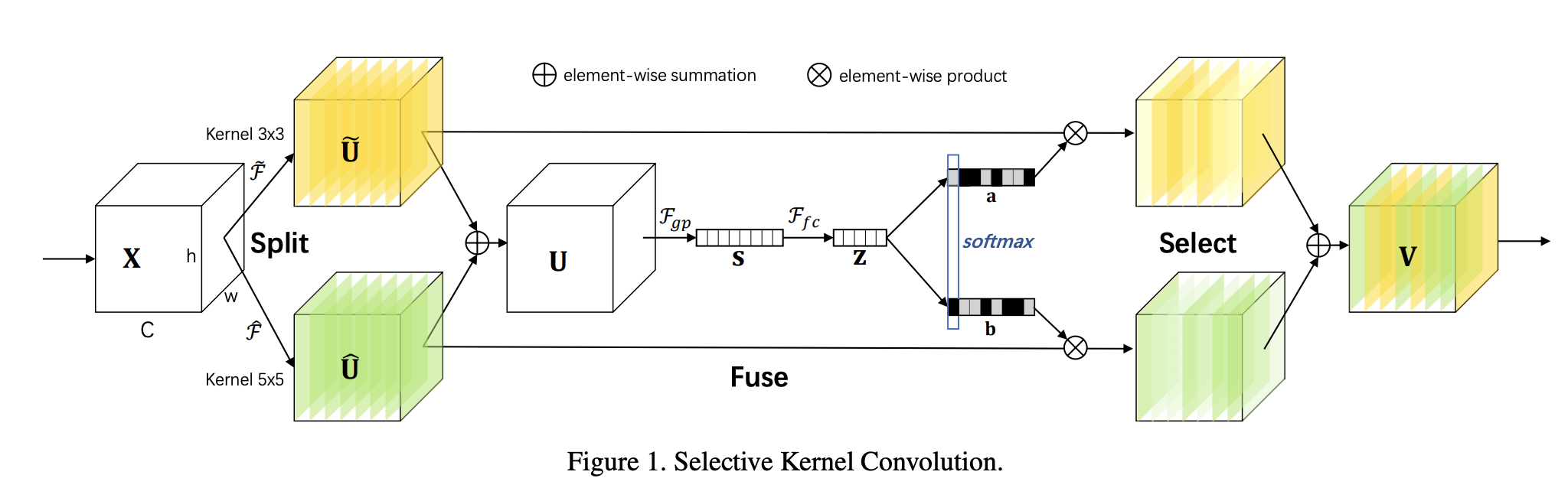
Selective Kernel单元是由一系列1×1卷积、SK卷积和1×1卷积组成的瓶颈块。 它被提议作为 SKNet CNN 架构的一部分。 一般来说,ResNeXt 中原始瓶颈块中的所有大内核卷积都被所提出的 SK 卷积取代,使网络能够以自适应方式选择合适的感受野大小。

十五、DPN Block
双路径网络块是卷积神经网络中使用的图像模型块。 该模块的想法是实现公共功能的共享,同时保持通过双路径架构探索新功能的灵活性。 从这个意义上说,它结合了 ResNets 和 DenseNets 的优点。 它被提议作为 DPN CNN 架构的一部分。
我们制定这样的双路径架构如下:

