文章目录
-
- 十六、EfficientDet
- 十七、Deformable DETR
- 十八、YOLOX
- 十九、Sparse R-CNN
- 二十、Contour Proposal Network
- 二十一、VarifocalNet
- 二十二、Libra R-CNN
- 二十三、Stand-Alone Self Attention
- 二十四、ThunderNet
- 二十五、Hierarchical Transferability Calibration Network
- 二十六、PP-YOLO
- 二十七、YOLOv1
- 二十八、Grid R-CNN
- 二十九、RTMDet: An Empirical Study of Designing Real-Time Object Detectors
- 三十、TridentNet
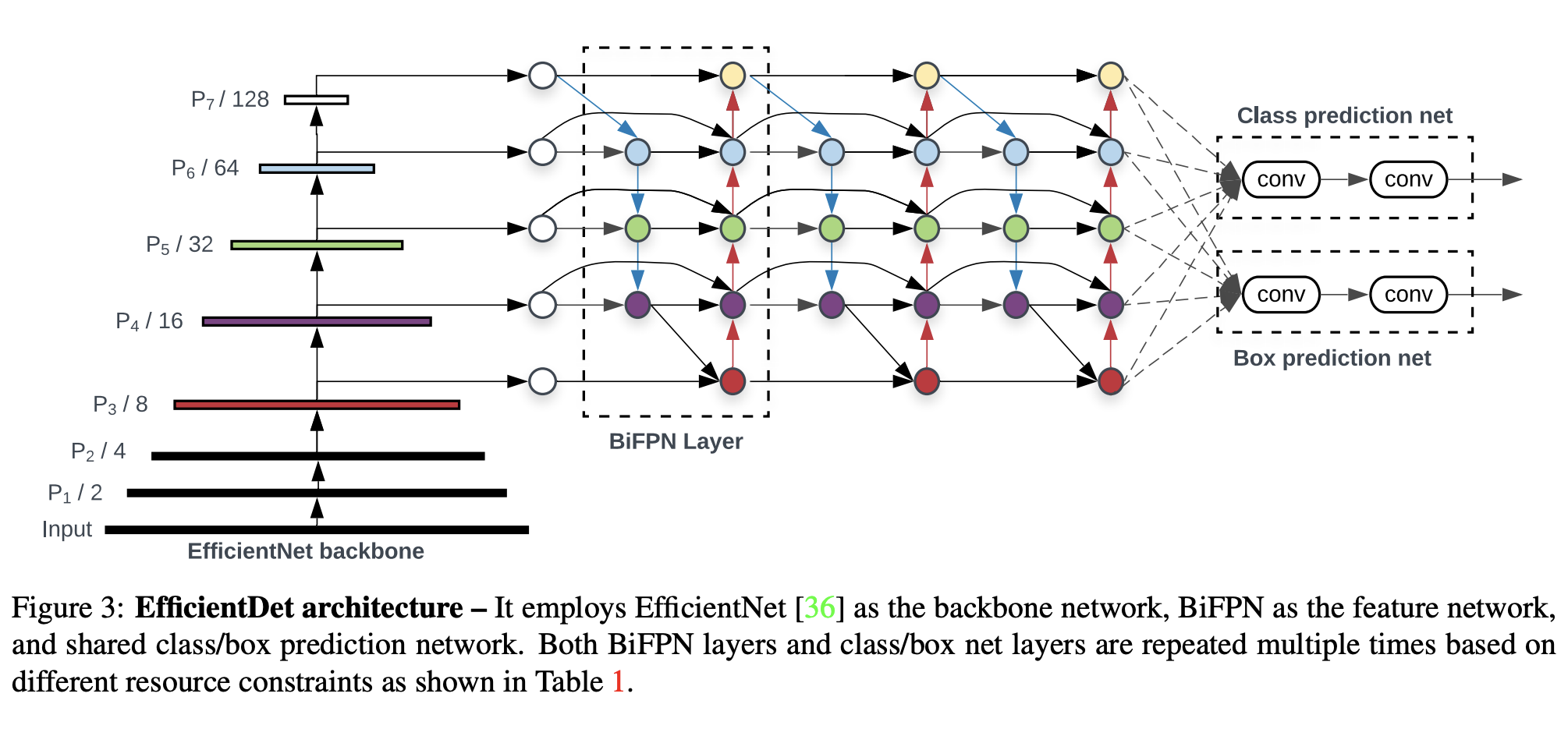
十六、EfficientDet
EfficientDet 是一种对象检测模型,它利用多种优化和主干调整,例如使用 BiFPN,以及统一缩放所有主干、特征网络和框/类预测的分辨率、深度和宽度的复合缩放方法 同时网络。
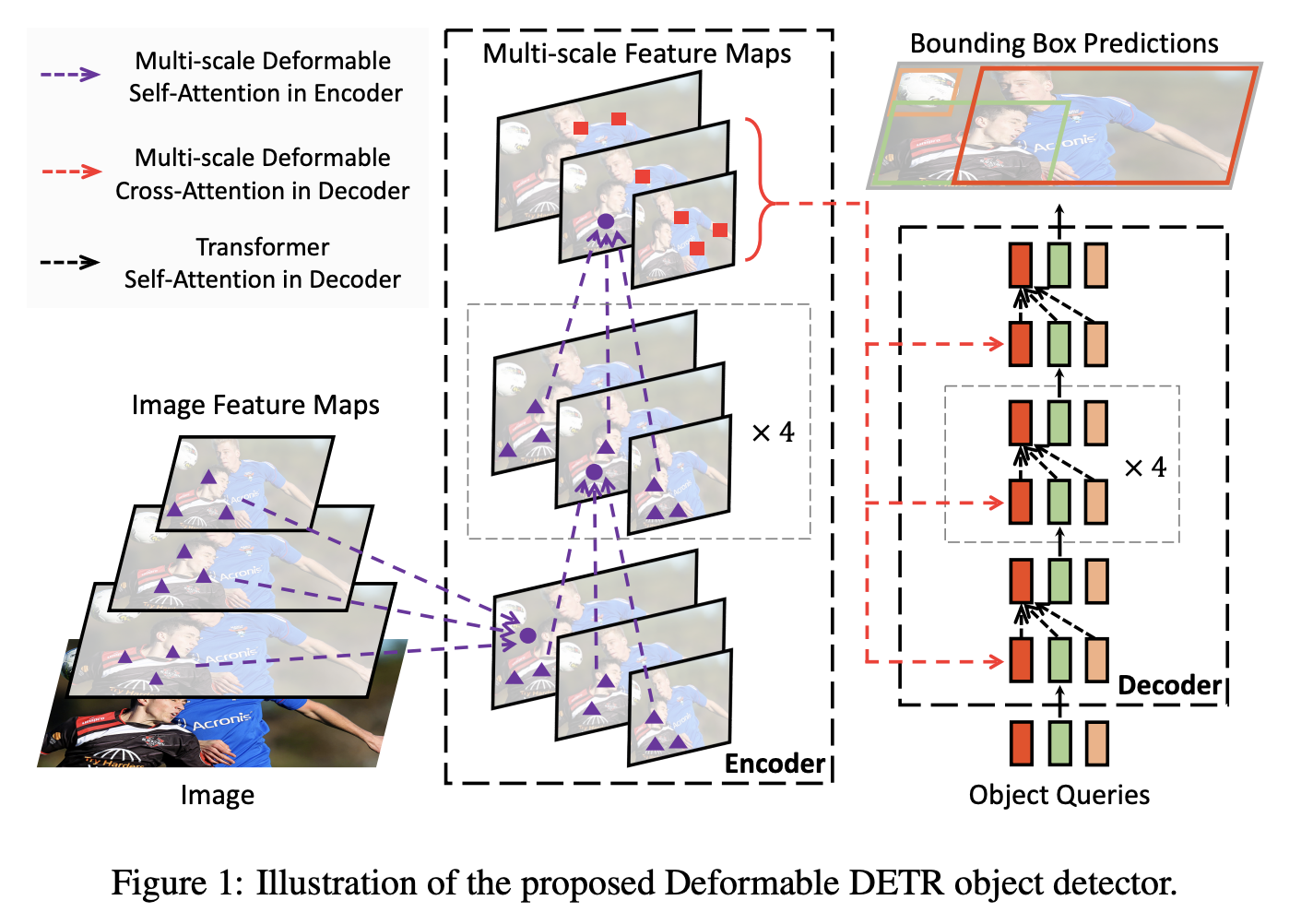
十七、Deformable DETR
可变形 DETR 是一种目标检测方法,旨在缓解 DETR 收敛速度慢和复杂度高的问题。 它结合了可变形卷积的稀疏空间采样和 Transformers 的关系建模功能的最佳性能。 具体来说,它引入了一个可变形注意模块,该模块关注一小组采样位置,作为所有特征图像素中突出关键元素的预过滤器。 该模块可以自然地扩展到聚合多尺度特征,而无需借助 FPN。
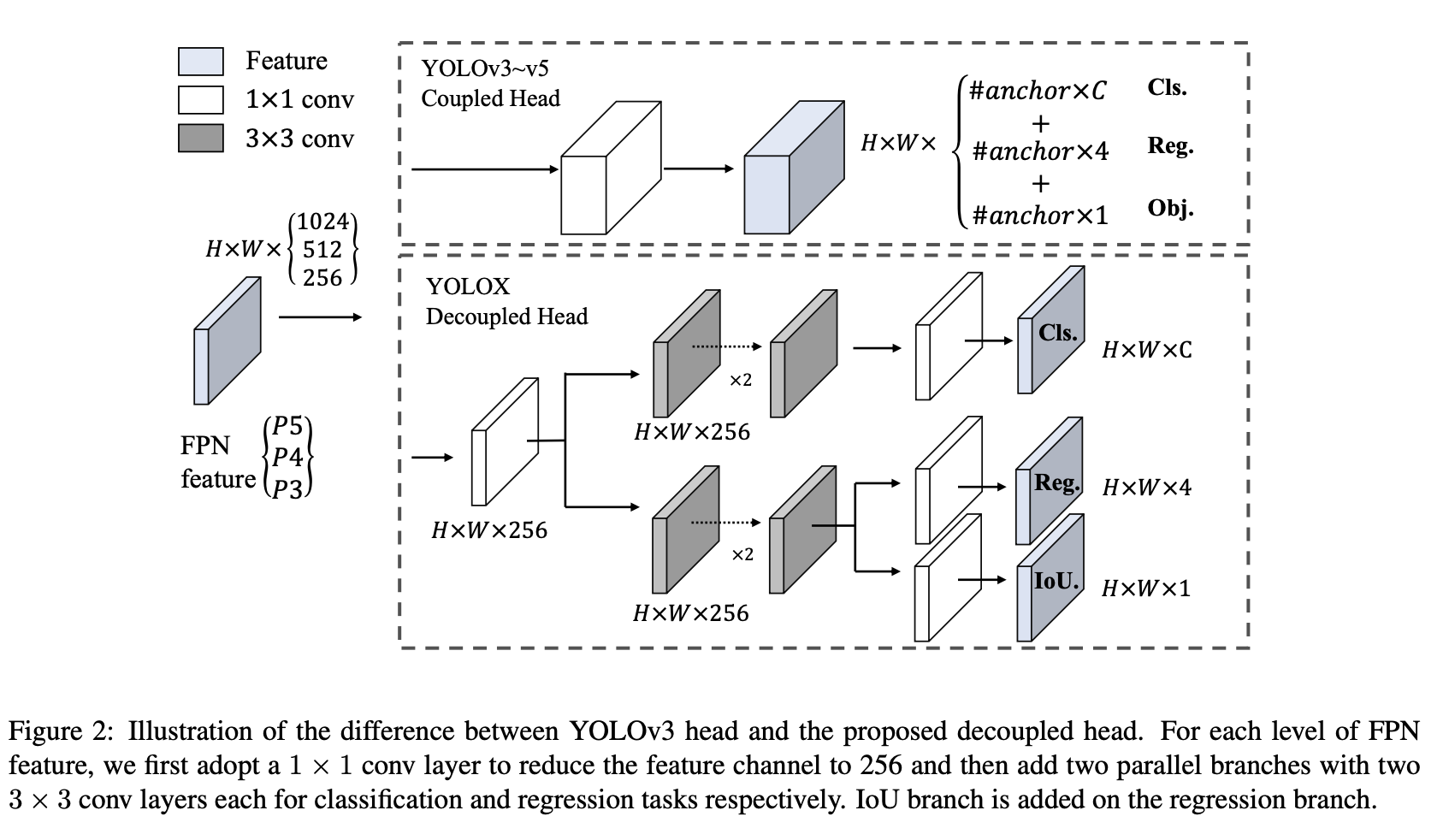
十八、YOLOX
YOLOX 是一种单级目标检测器,它对具有 DarkNet53 主干的 YOLOv3 进行了多项修改。 具体来说,YOLO的头部被替换为解耦的头部。 对于每个级别的 FPN 特征,我们首先采用 1 × 1 卷积层将特征通道减少到 256,然后添加两个并行分支,每个分支具有两个 3 × 3 卷积层,分别用于分类和回归任务。
其他变化包括将 Mosaic 和 MixUp 添加到增强策略中以提高 YOLOX 的性能。 锚定机制也被移除,因此 YOLOX 是无锚定的。 最后,用于标签分配的 SimOTA——其中标签分配通过 top-k 策略被表述为最优传输问题。
十九、Sparse R-CNN
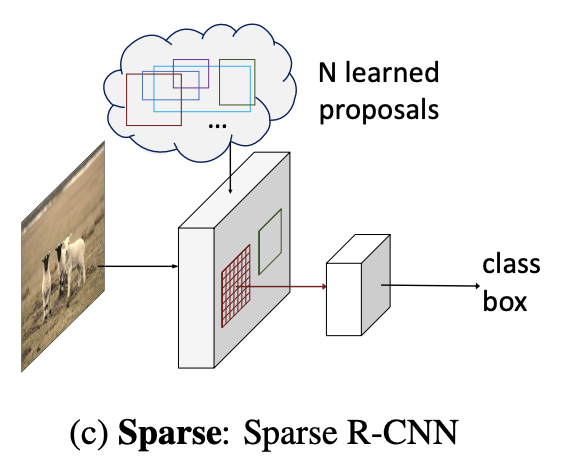
稀疏 R-CNN 是一种用于图像中对象检测的纯粹稀疏方法,无需在所有(密集)图像网格上枚举对象位置候选,也无需与全局(密集)图像特征交互的对象查询。
如图所示,候选对象由一小组固定的可学习边界框(由 4 维坐标表示)给出。 以 COCO 数据集为例,总共需要 100 个框和 400 个参数,而不是从区域提议网络(RPN)中数十万个候选者中预测的参数。 这些稀疏候选被用作建议框,通过 RoIPool 或 RoIAlign 提取感兴趣区域(RoI)的特征。
二十、Contour Proposal Network
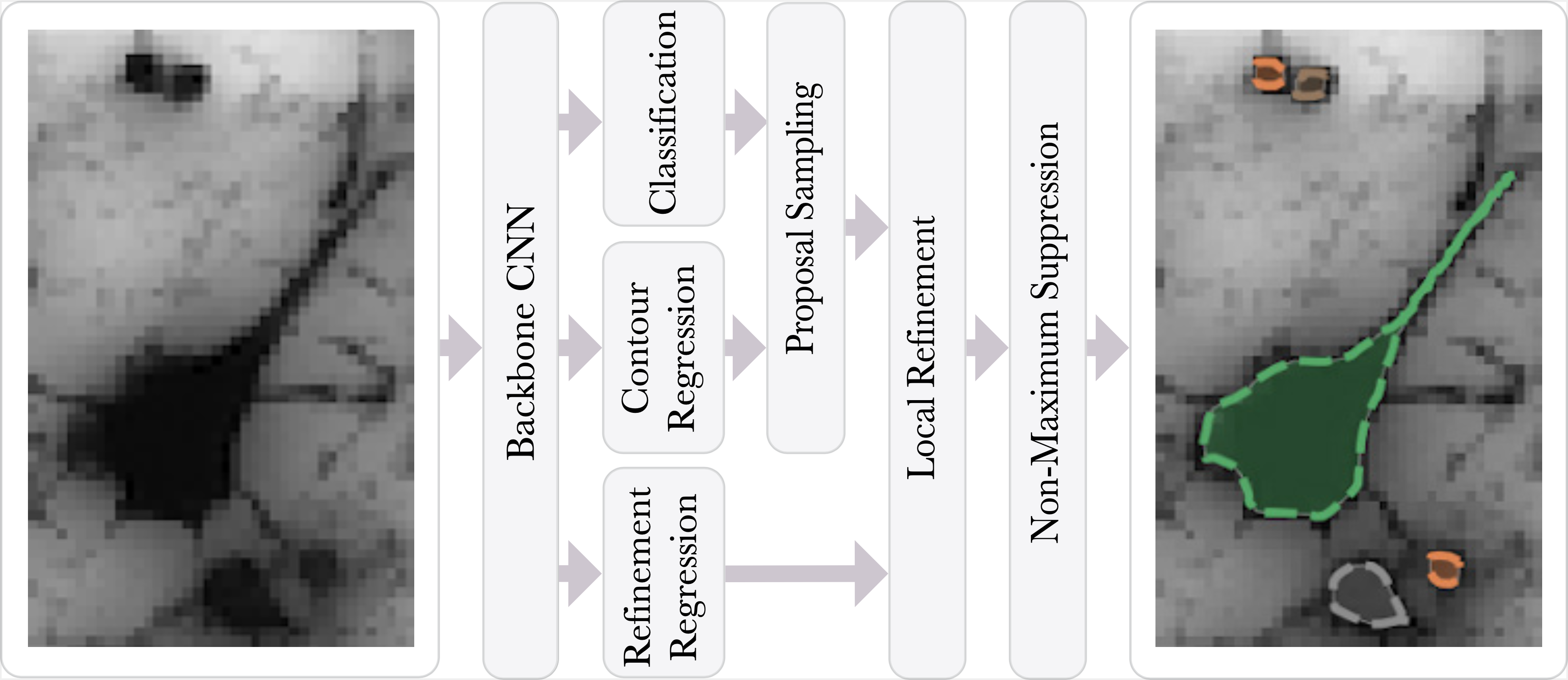
轮廓提议网络 (CPN) 检测图像中可能重叠的对象,同时拟合像素精确的闭合对象轮廓。 CPN 可以将最先进的对象检测架构作为骨干网络合并到可以进行端到端训练的快速单阶段实例分割模型中。
二十一、VarifocalNet
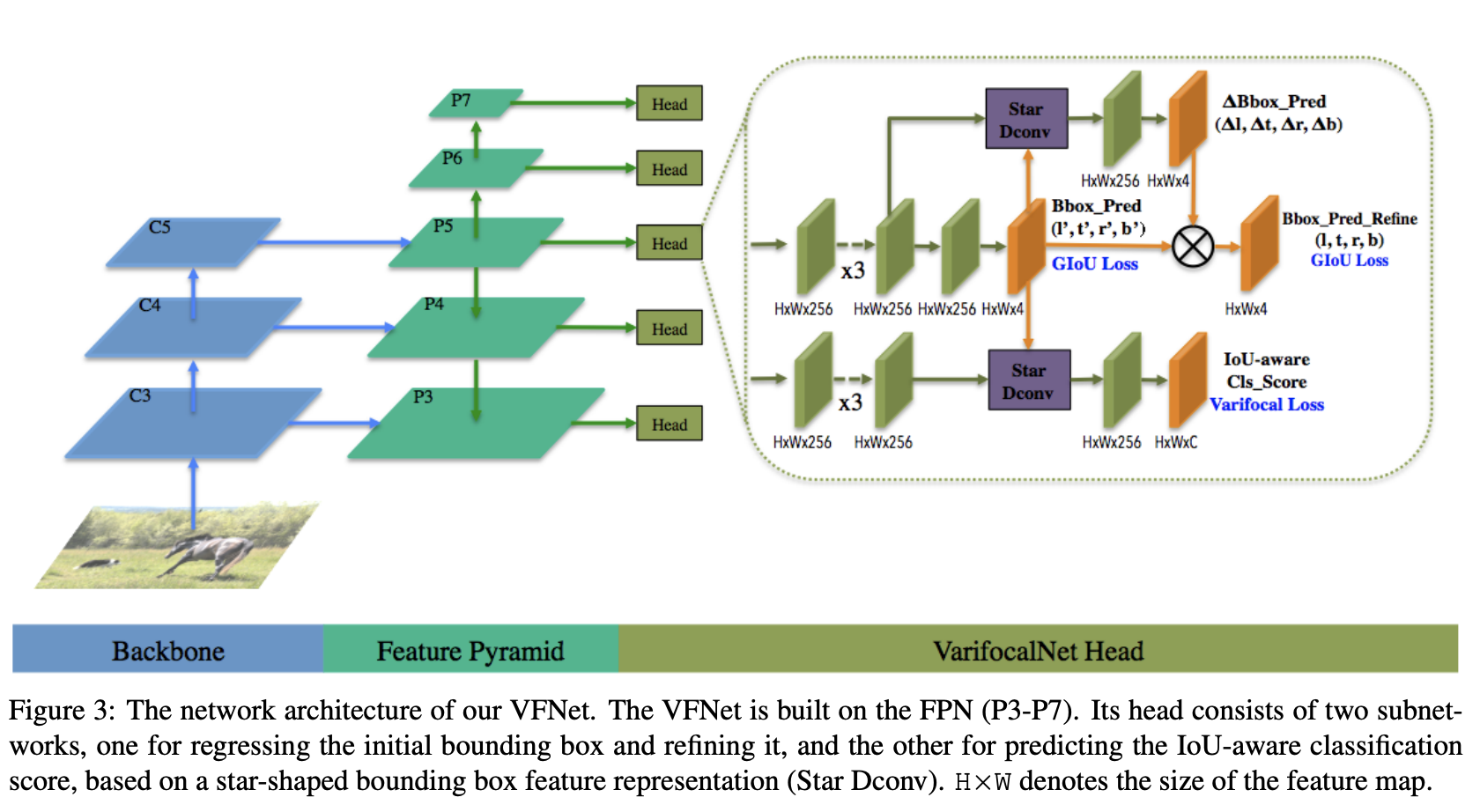
VarifocalNet 是一种旨在对目标检测中的大量候选检测进行准确排名的方法。 它由一个名为 Varifocal Loss 的新损失函数组成,用于训练密集目标检测器来预测 IACS,以及一个用于估计 IACS 和细化粗边界框的新高效星形边界框特征表示。 将这两个新组件和边界框细化分支相结合,在 FCOS 架构上产生密集目标检测器,作者将其简称为 VarifocalNet 或 VFNet。
二十二、Libra R-CNN
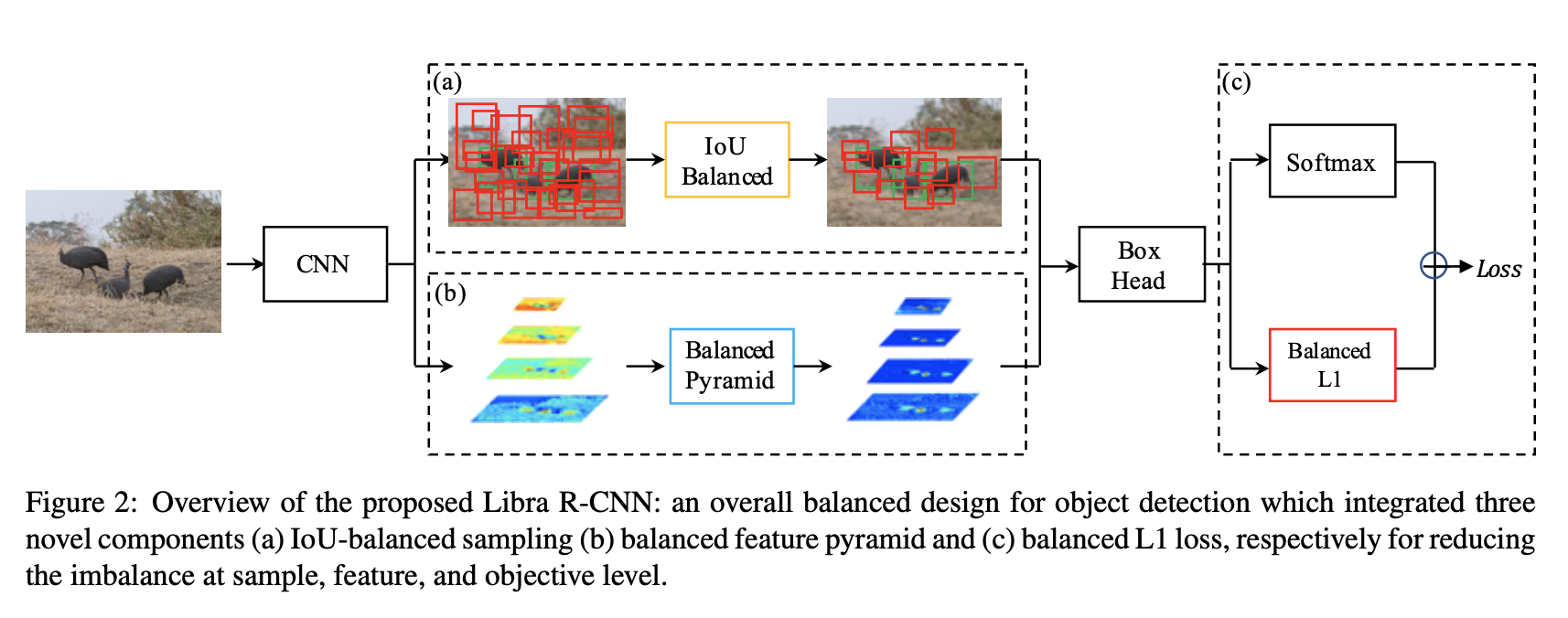
Libra R-CNN 是一种目标检测模型,旨在实现平衡的训练过程。 作者的动机是,过去的检测器的训练在训练过程中存在不平衡,一般分为三个级别:样本级别、特征级别和目标级别。 为了减轻不利影响,Libra R-CNN 集成了三个新颖的组件:IoU 平衡采样、平衡特征金字塔和平衡 L1 损失,分别用于减少样本、特征和目标级别的不平衡。
二十三、Stand-Alone Self Attention
独立自注意力 (SASA) 将所有空间卷积实例替换为应用于 ResNet 的自注意力形式,从而生成完全独立的自注意力模型。
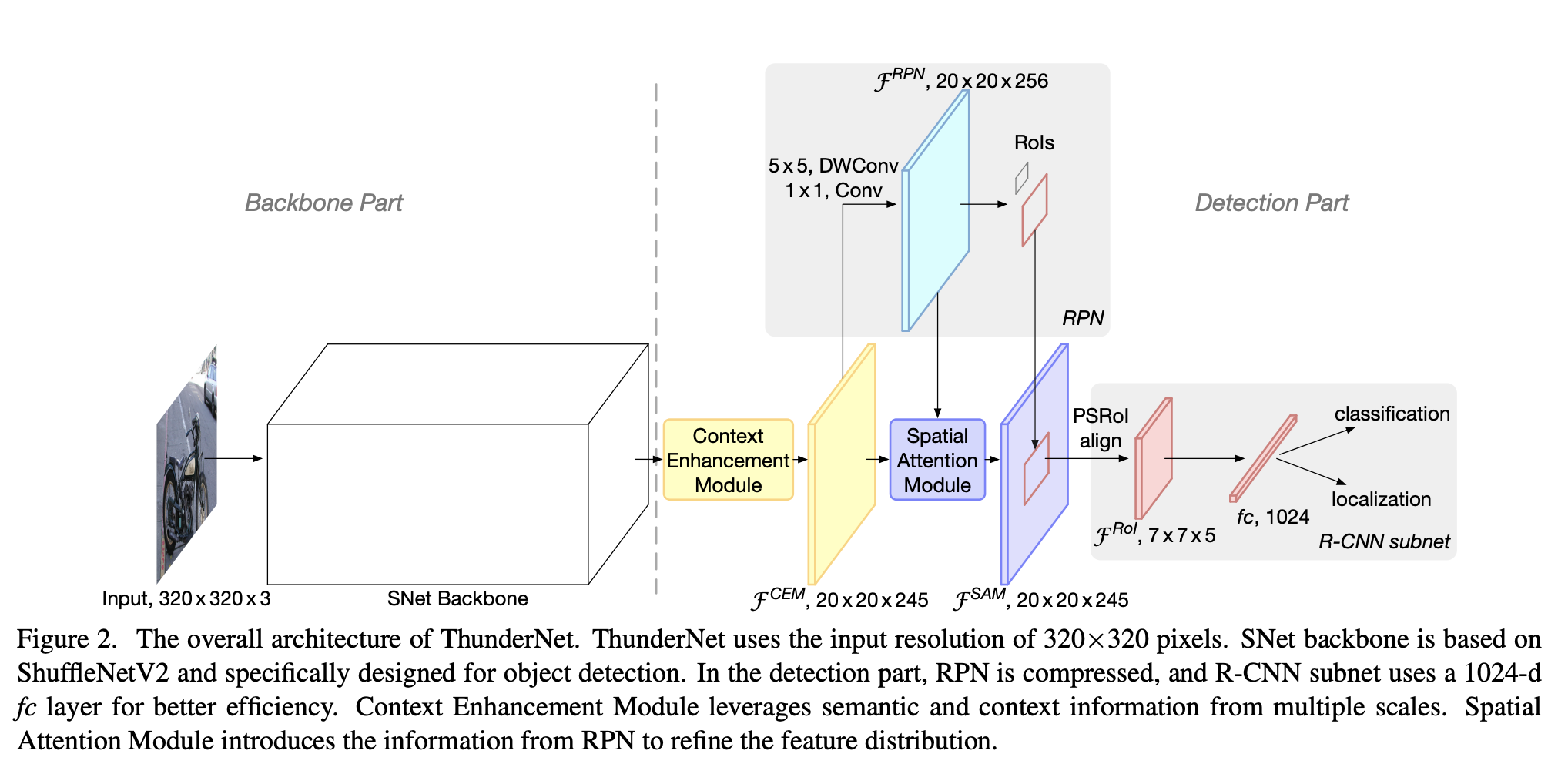
二十四、ThunderNet
ThunderNet 是一个两阶段目标检测模型。 ThunderNet 的设计针对的是最先进的两级探测器中计算量大的结构。 主干网络采用了受 ShuffleNetV2 启发的网络(称为 SNet),专为目标检测而设计。 在检测部分,ThunderNet沿用了Light-Head R-CNN中的检测头设计,并进一步压缩了RPN和R-CNN子网。 为了消除小主干和小特征图引起的性能下降,ThunderNet 使用了两个新的高效架构模块:上下文增强模块(CEM)和空间注意力模块(SAM)。 CEM 结合了多个尺度的特征图以利用局部和全局上下文信息,而 SAM 使用 RPN 中学到的信息来细化 RoI 扭曲中的特征分布。
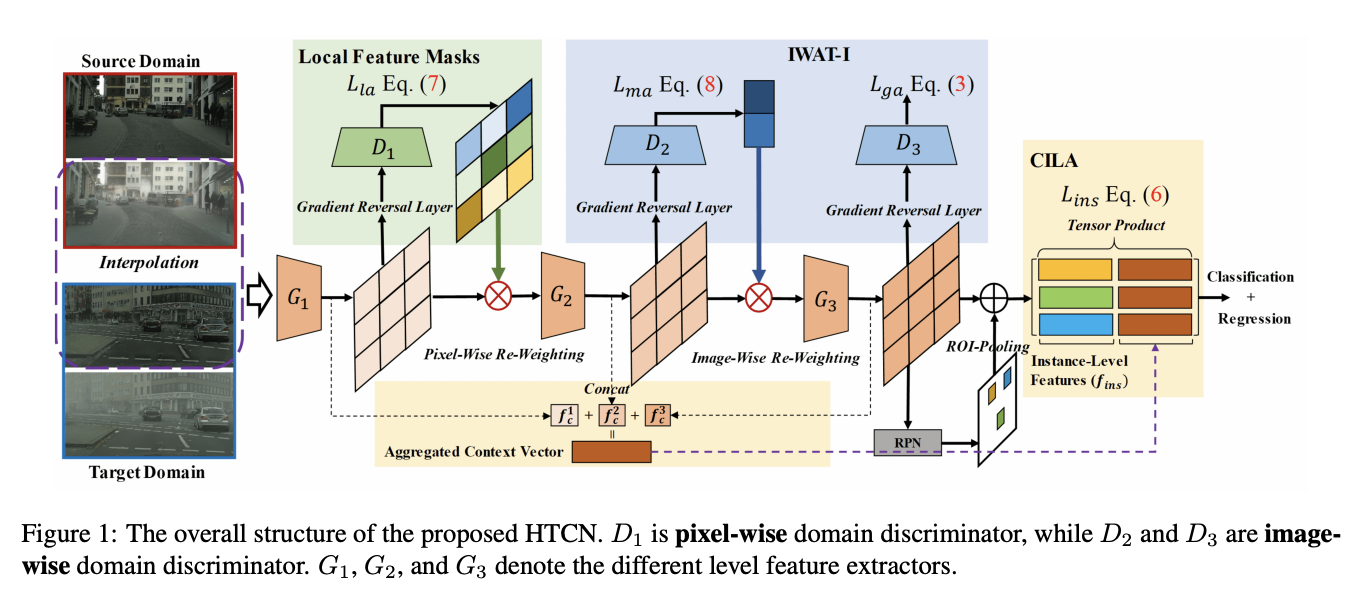
二十五、Hierarchical Transferability Calibration Network
分层可转移性校准网络(HTCN)是一种自适应目标检测器,可分层(局部区域/图像/实例)校准特征表示的可转移性,以协调可转移性和可辨别性。 所提出的模型由三个部分组成:(1)具有输入插值的重要性加权对抗训练(IWAT-I),它通过重新加权插值图像级特征来增强全局可辨别性; (2)上下文感知实例级对齐(CILA)模块,通过捕获实例级特征与全局上下文信息之间的互补效果进行实例级特征对齐,从而增强局部可辨别性; (3)局部特征掩模,用于校准局部可转移性,为以下判别模式对齐提供语义指导。
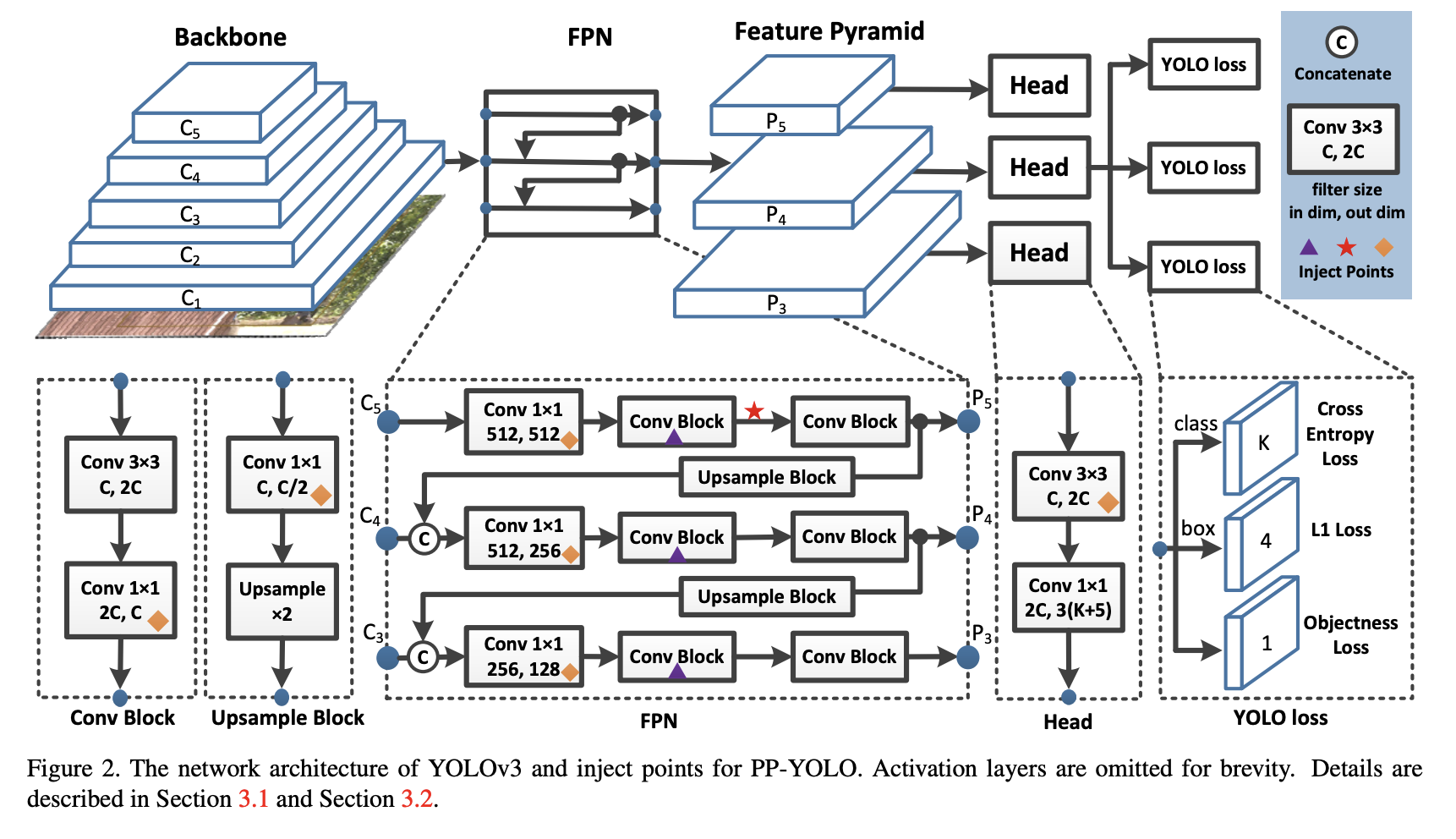
二十六、PP-YOLO
PP-YOLO是基于YOLOv3的目标检测器。 它主要尝试结合现有的各种几乎不增加模型参数数量和FLOPs的trick,以达到在保证速度几乎不变的情况下尽可能提高检测器精度的目标。 其中一些变化包括:
使用 ResNet50-vd 更改 DarkNet-53 主干网。 ResNet50-vd中的一些卷积层也被替换为可变形卷积层。
使用更大的批量大小 - 从 64 更改为 192。
参数使用指数移动平均值。
DropBlock 应用于 FPN。
使用 IoU 损失。
添加 IoU 预测分支来测量定位的准确性。
使用Grid Sensitive,与YOLOv4类似。
使用矩阵NMS。
CoordConv用于FPN,取代了1x1卷积层,也是检测头中的第一个卷积层。
空间金字塔池用于顶部特征图。
二十七、YOLOv1
YOLOv1 是一个单阶段目标检测模型。 对象检测被视为空间分离的边界框和相关类概率的回归问题。 单个神经网络在一次评估中直接从完整图像预测边界框和类别概率。 由于整个检测管道是单个网络,因此可以直接在检测性能上进行端到端优化。
该网络使用整个图像的特征来预测每个边界框。 它还同时预测图像所有类别的所有边界框。 这意味着网络对完整图像和图像中的所有对象进行全局推理。

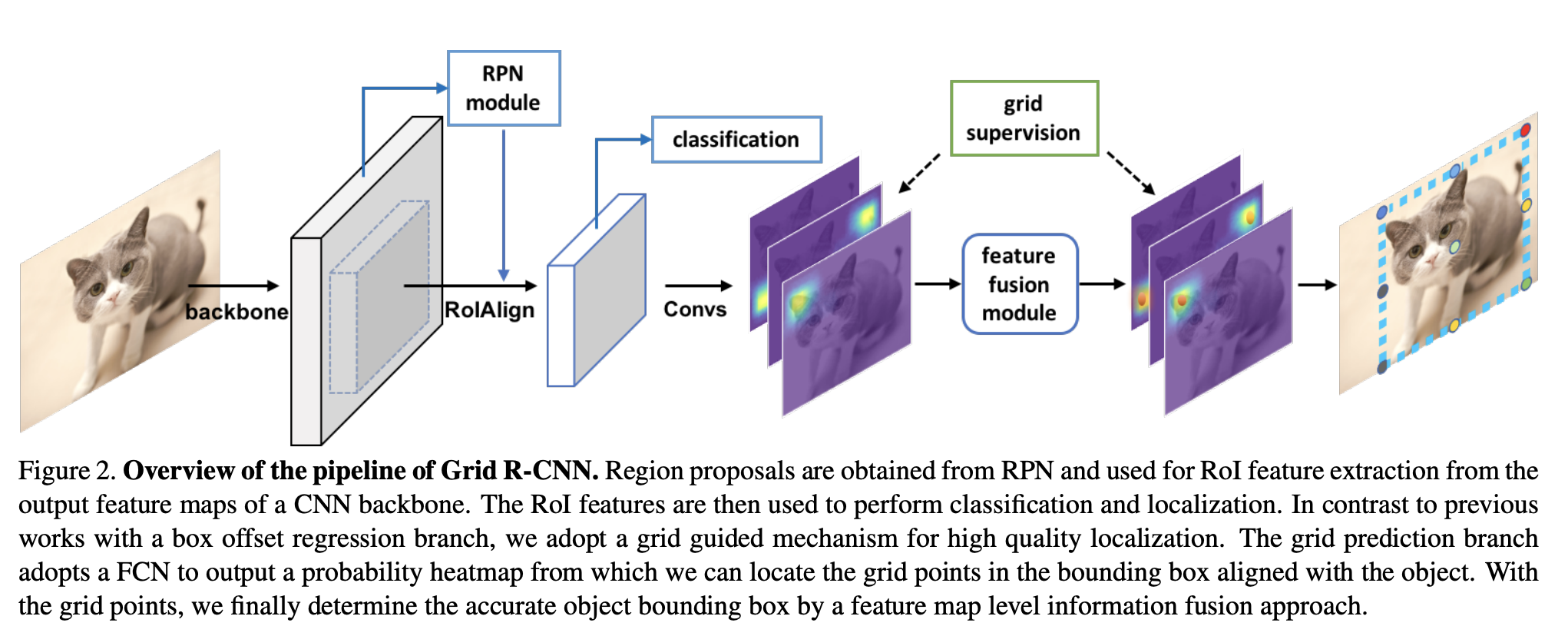
二十八、Grid R-CNN
Grid R-CNN 是一个目标检测框架,其中传统的回归公式被网格点引导的定位机制取代。
Grid R-CNN 将对象边界框区域划分为网格,并采用全卷积网络(FCN)来预测网格点的位置。 由于全卷积架构的位置敏感特性,Grid R-CNN 保持了明确的空间信息,并且可以在像素级获得网格点位置。 当指定位置上一定数量的网格点已知时,相应的边界框就确定了。 在网格点的引导下,Grid R-CNN 可以比缺乏显式空间信息引导的回归方法确定更准确的对象边界框。
二十九、RTMDet: An Empirical Study of Designing Real-Time Object Detectors
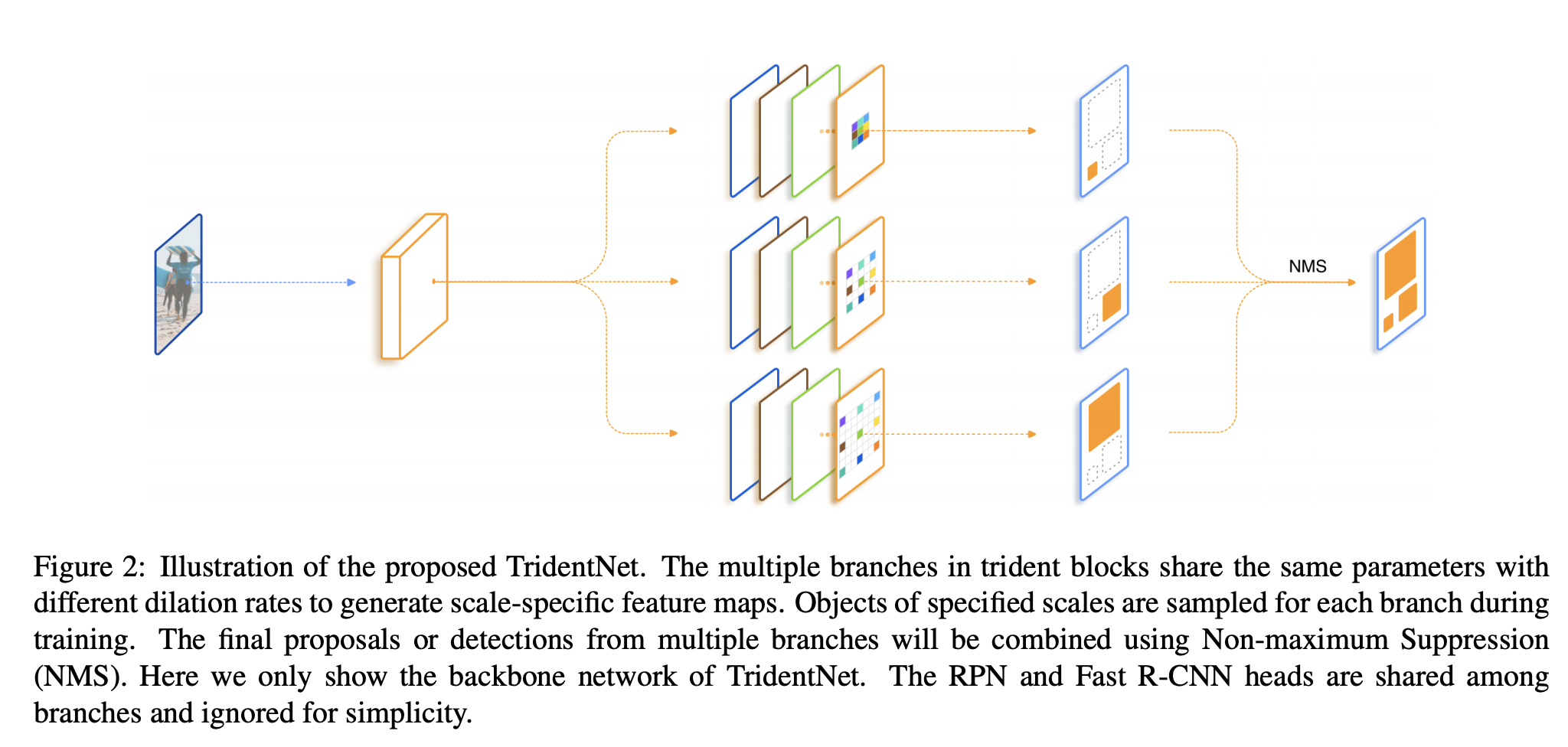
三十、TridentNet
TridentNet 是一种目标检测架构,旨在生成具有统一表示能力的特定比例特征图。 构建了并行多分支架构,其中每个分支共享相同的变换参数但具有不同的感受野。 尺度感知训练方案用于通过采样适当尺度的对象实例进行训练来专门化每个分支。