文章目录
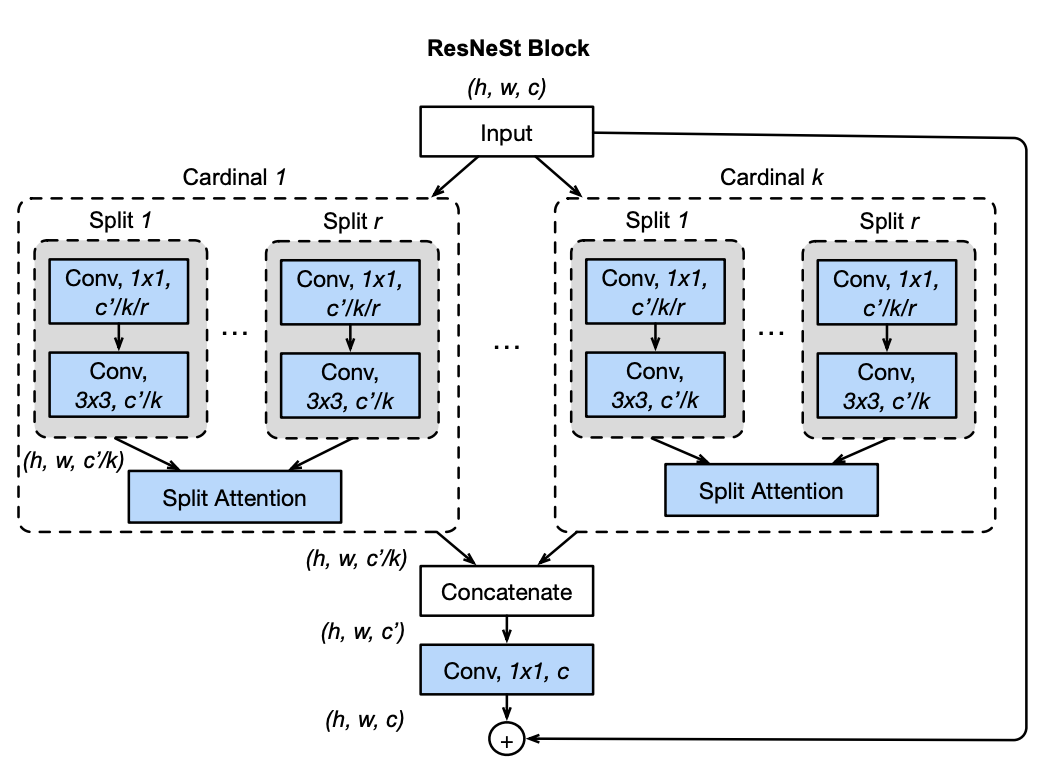
一、ResNeSt

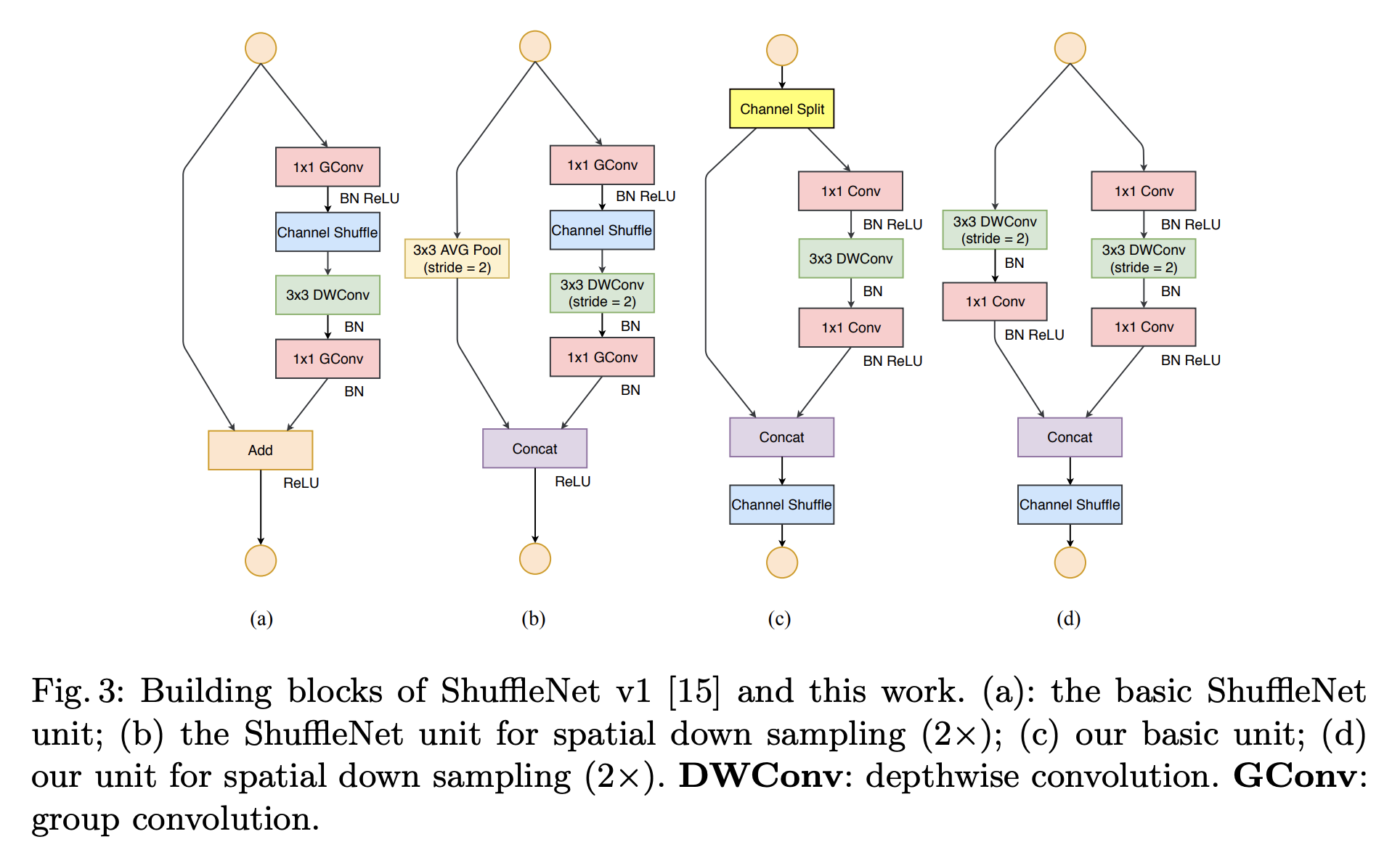
二、ShuffleNet v2
ShuffleNet v2 是一种针对直接指标(速度)而非间接指标(如 FLOP)进行优化的卷积神经网络。 它建立在 ShuffleNet v1 的基础上,它利用了逐点组卷积、类似瓶颈的结构和通道洗牌操作。 差异如右图所示,包括新的通道分割操作以及将通道洗牌操作进一步移至块下方。
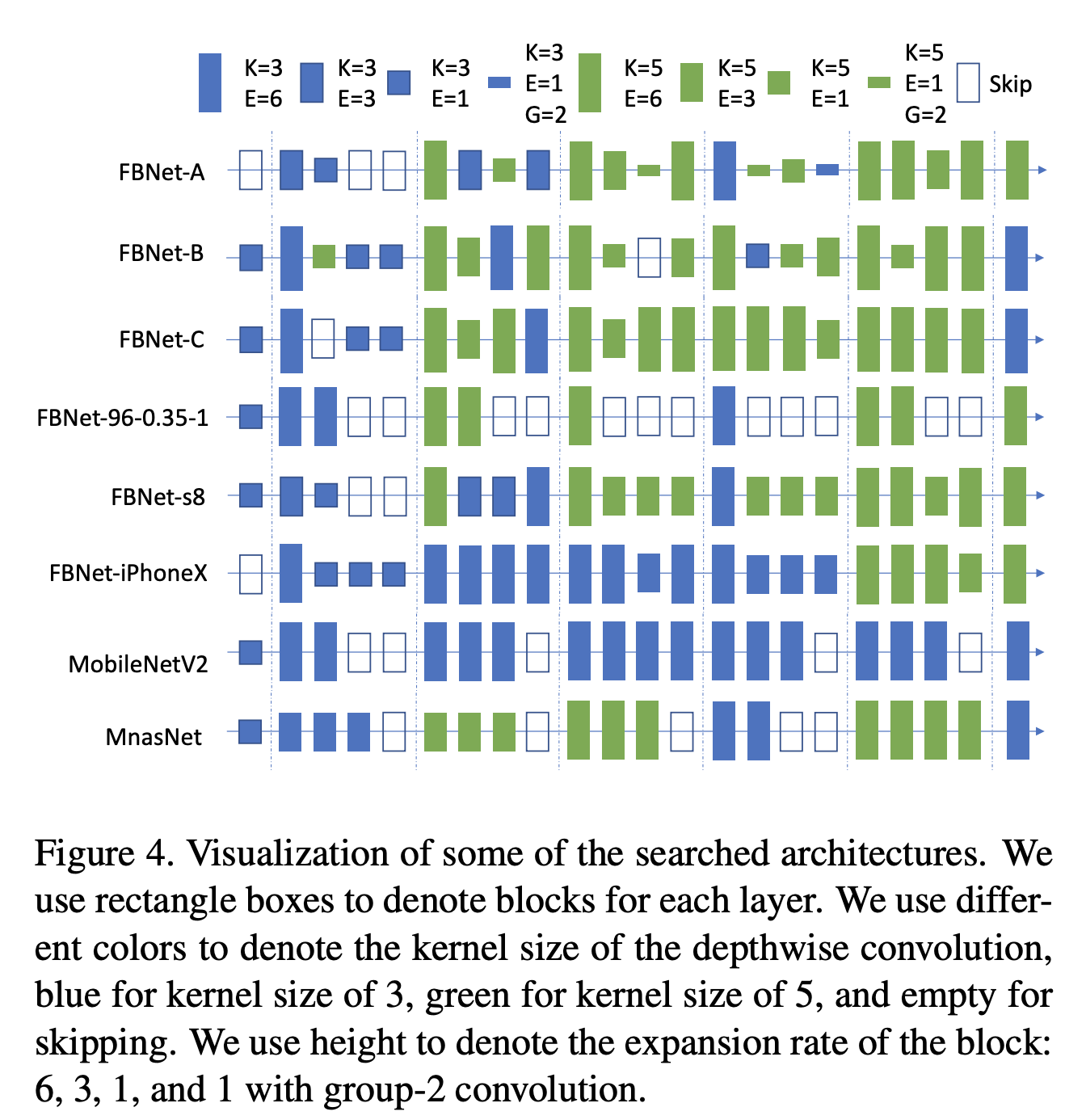
三、FBNet
FBNet 是通过 DNAS 神经架构搜索发现的一种卷积神经架构。 它采用受 MobileNetv2 启发的基本类型图像模型块,该模型利用深度卷积和反向残差结构(请参阅组件)。
四、Inception-v4
Inception-v4 是一种卷积神经网络架构,它建立在 Inception 系列之前的迭代基础上,通过简化架构并使用比 Inception-v3 更多的 inception 模块。

五、ResNet-D
ResNet-D 是对 ResNet 架构的修改,它利用平均池调整进行下采样。 动机是在未修改的 ResNet 中,下采样块的 1 × 1 卷积忽略了 3/4 的输入特征图,因此对此进行了修改,因此不会忽略任何信息。

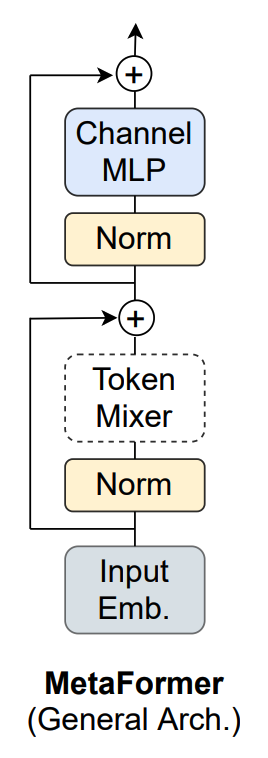
六、MetaFormer
MetaFormer 是一个从 Transformer 中抽象出来的通用架构,没有指定令牌混合器。
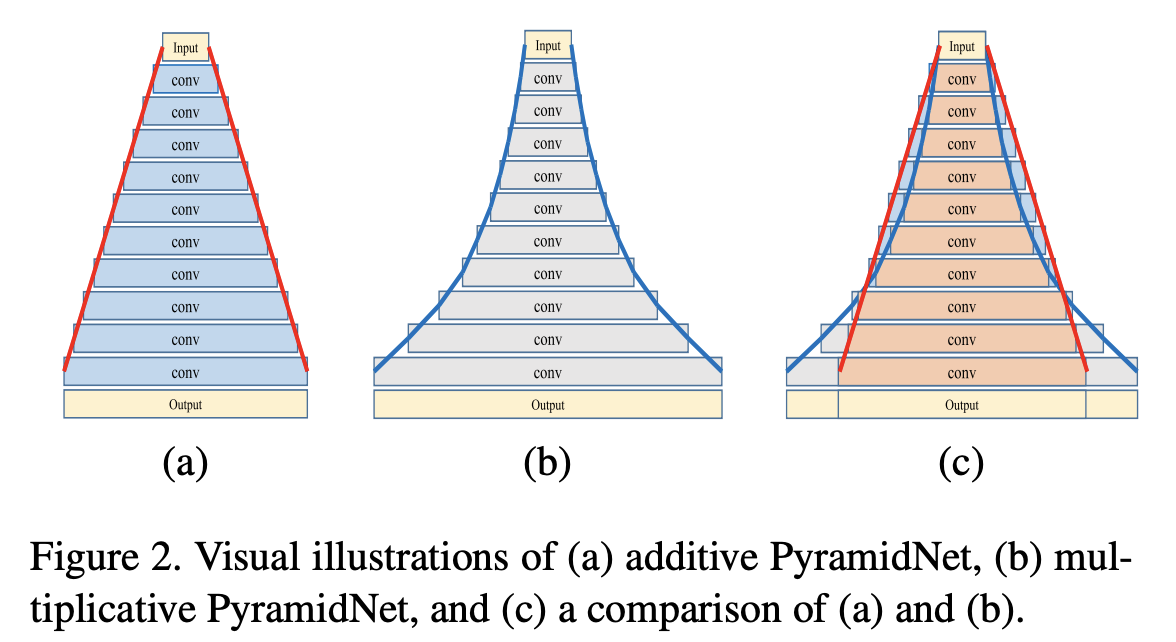
七、PyramidNet
PyramidNet 是一种卷积网络,其关键思想是通过逐渐增加特征图维度来集中注意力,而不是通过下采样在每个残差单元处急剧增加特征图维度。 此外,在增加特征图维度时,网络架构通过使用零填充身份映射快捷连接,作为普通网络和残差网络的混合体。
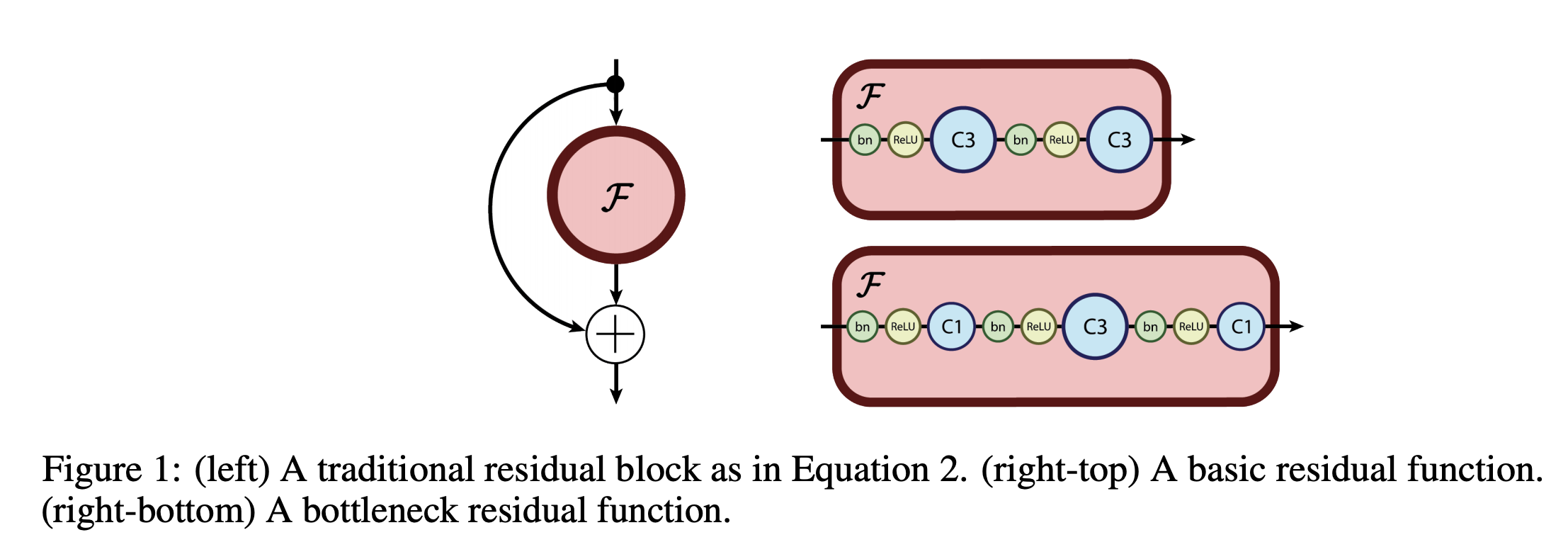
八、RevNet
可逆残差网络(或 RevNet)是 ResNet 的变体,其中每一层的激活都可以根据下一层的激活精确重建。 因此,在反向传播期间,大多数层的激活不需要存储在内存中。 结果是网络架构的激活存储需求与深度无关,并且通常比同等大小的 ResNet 小至少一个数量级。

请注意,与残差块不同,可逆块的步长必须为 1,否则该层会丢弃信息,因此无法可逆。 标准 ResNet 架构通常具有少数几个步幅较大的层。 如果我们类似地定义 RevNet 架构,则必须显式存储所有不可逆层的激活。
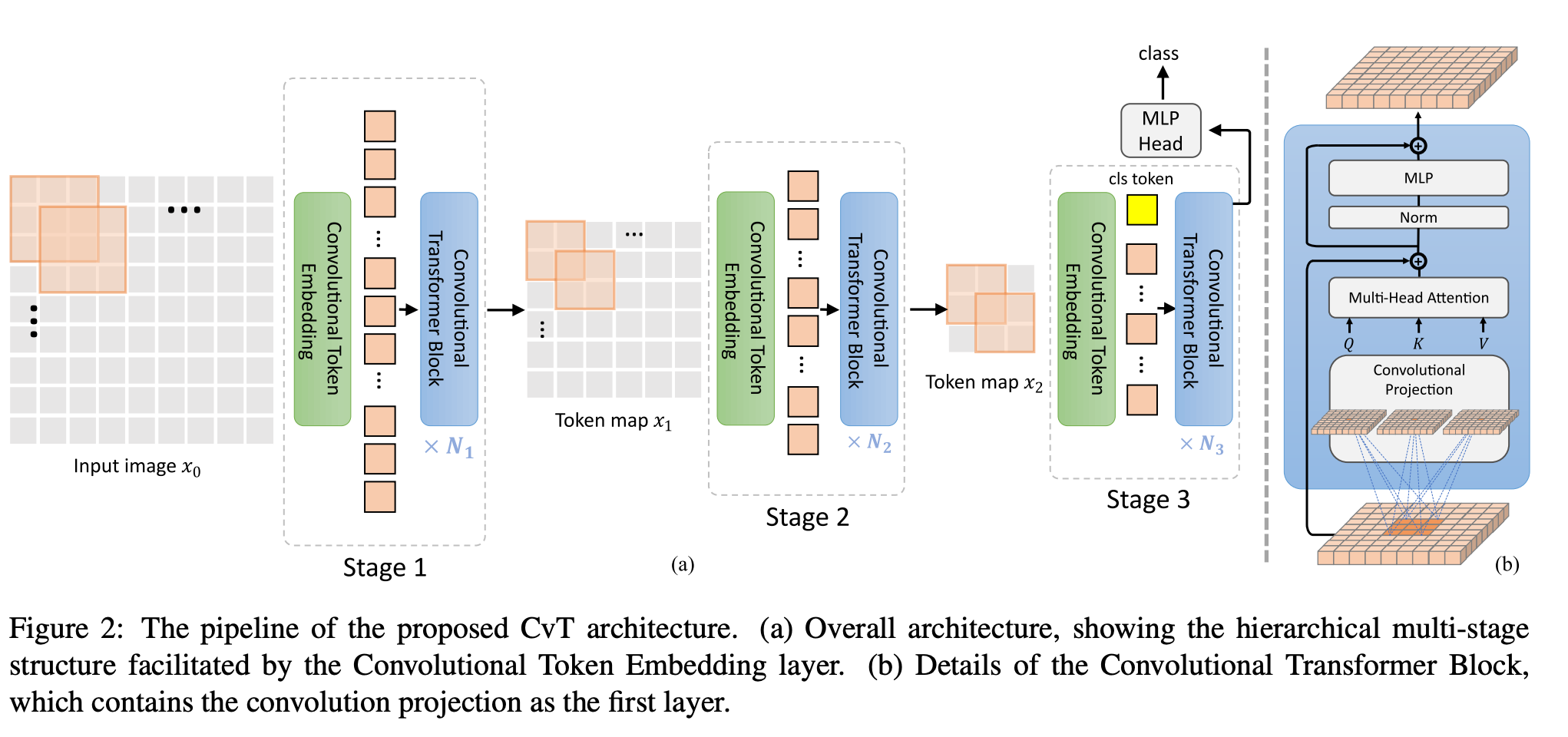
九、Convolutional Vision Transformer(CVT)
卷积视觉 Transformer (CvT) 是一种将卷积合并到 Transformer 中的架构。 CvT 设计将卷积引入到 ViT 架构的两个核心部分。
首先,Transformers 被划分为多个阶段,形成 Transformers 的层次结构。 每个阶段的开始由一个卷积令牌嵌入组成,该嵌入在 2D 重塑令牌图上执行重叠卷积操作(即,将扁平令牌序列重塑回空间网格),然后进行层归一化。 这使得模型不仅可以捕获局部信息,还可以逐步减少序列长度,同时增加跨阶段标记特征的维度,实现空间下采样,同时增加特征图的数量,就像 CNN 中执行的那样。
其次,Transformer 模块中每个自注意力块之前的线性投影被替换为提出的卷积投影,该投影在 2D 重塑令牌图上采用 s × s 深度可分离卷积运算。 这使得模型能够进一步捕获局部空间上下文并减少注意力机制中的语义歧义。 它还允许管理计算复杂性,因为卷积的步长可用于对键和值矩阵进行二次采样,以将效率提高 4 倍或更多,同时将性能下降降至最低。
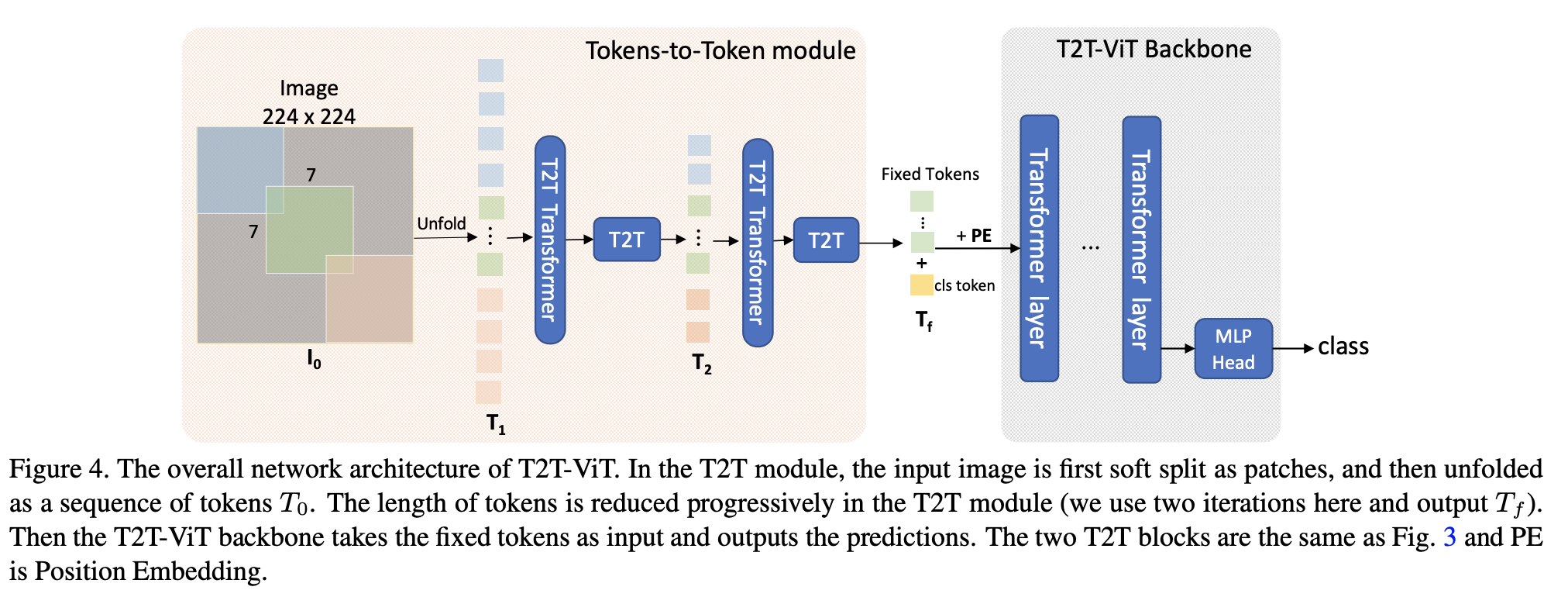
十、Tokens-To-Token Vision Transformer
T2T-ViT(Tokens-To-Token Vision Transformer)是一种 Vision Transformer,它结合了 1)分层的 Tokens-to-Token (T2T) 转换,通过递归地将相邻的 Tokens 聚合成一个 Token(Tokens)来逐步将图像结构化为 tokens。 -to-Token),这样可以对周围令牌表示的局部结构进行建模,并可以减少令牌长度; 2)经过实证研究后,受 CNN 架构设计启发,为视觉变换器提供了具有深窄结构的高效主干。
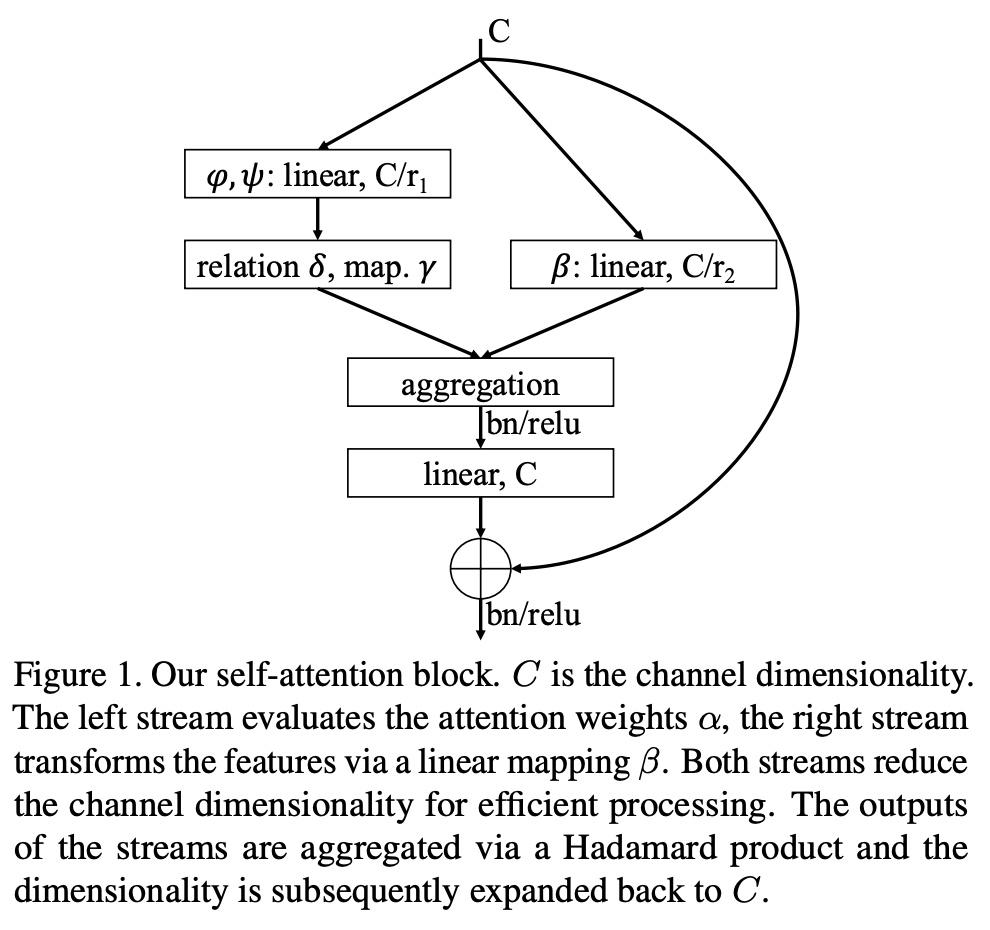
十一、Self-Attention Network
自注意力网络(SANet)提出了用于图像识别的自注意力的两种变体:1)成对自注意力,它概括了标准点积注意力,本质上是一个集合运算符;2)补丁自注意力,它严格地更多 比卷积强大。
十二、MixNet
MixNet 是一种通过 AutoML 发现的卷积神经网络,它使用 MixConv,而不是常规的深度卷积。

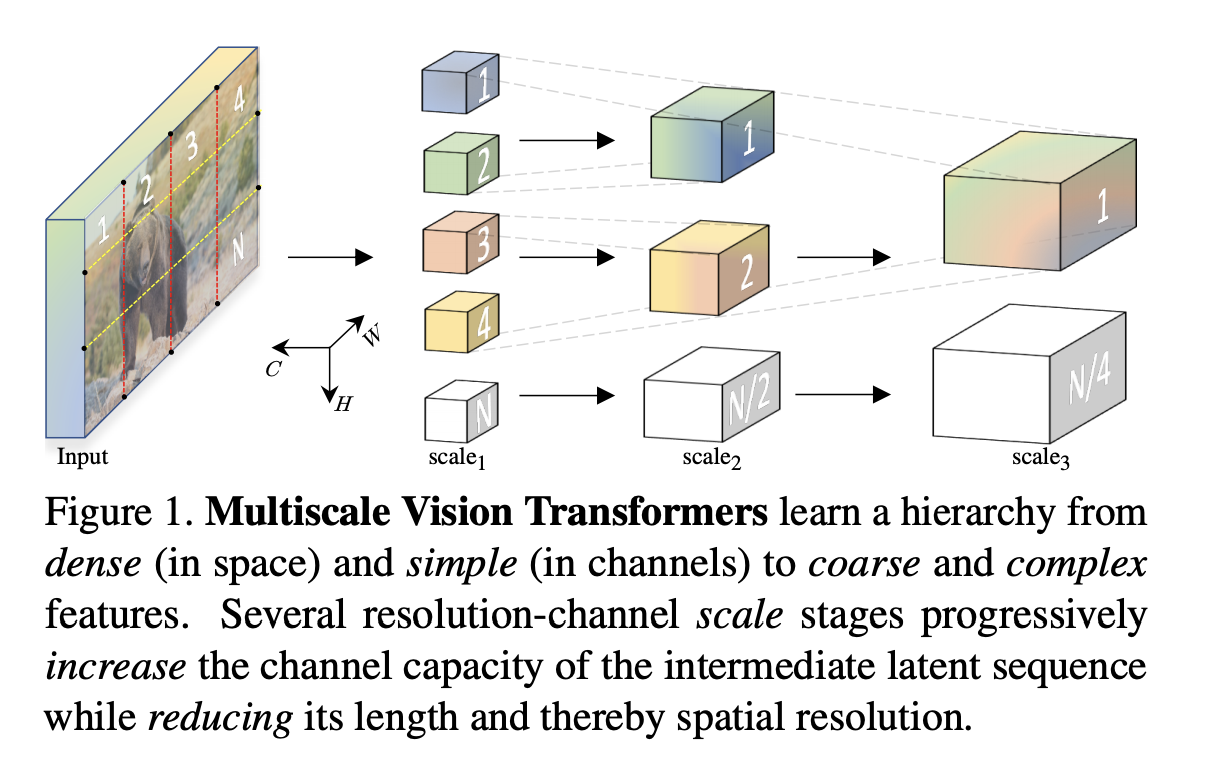
十三、Multiscale Vision Transformer
多尺度视觉变压器(MViT)是一种用于对图像和视频等视觉数据进行建模的变压器架构。 与在整个网络中保持恒定通道容量和分辨率的传统 Transformer 不同,多尺度 Transformer 具有多个通道分辨率缩放阶段。 从输入分辨率和小通道尺寸开始,各阶段分层扩展通道容量,同时降低空间分辨率。 这创建了一个多尺度的特征金字塔,早期层以高空间分辨率运行,以模拟简单的低级视觉信息,而更深层则以空间粗糙但复杂的高维特征运行。
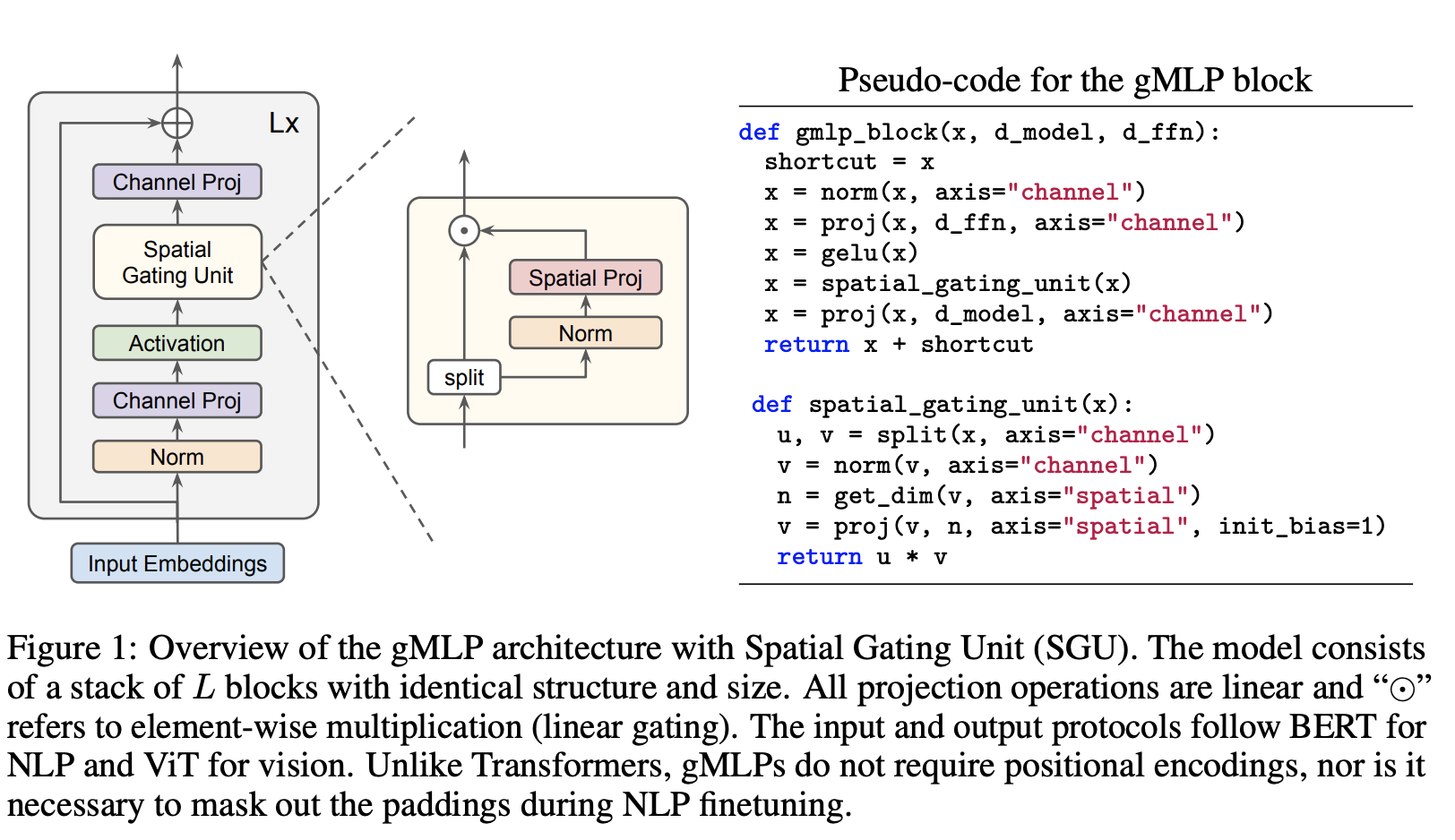
十四、gMLP

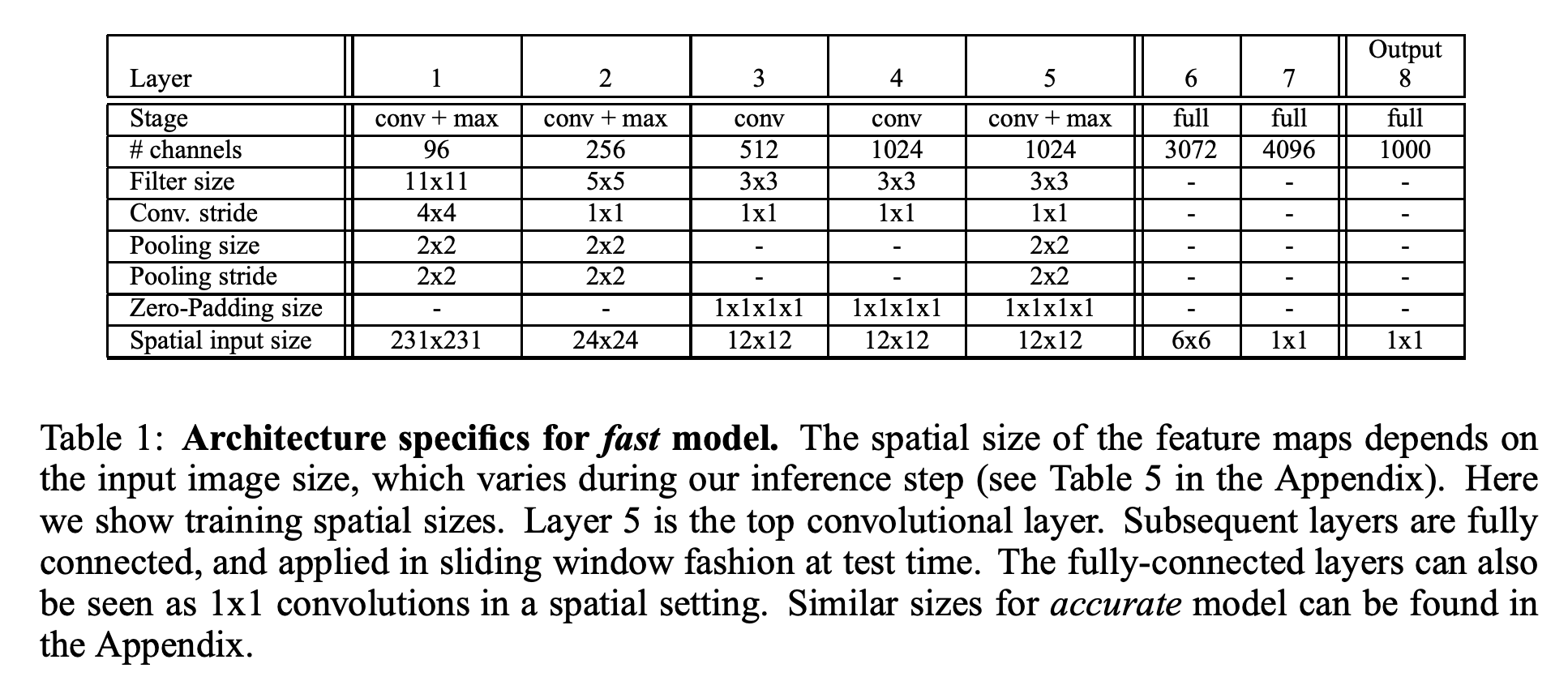
十五、OverFeat
OverFeat 是一种经典的卷积神经网络架构,采用卷积、池化和全连接层。 右图显示了架构细节。