文章目录
一、U-Net
U-Net 是一种语义分割架构。 它由收缩路径和扩张路径组成。 收缩路径遵循卷积网络的典型架构。 它由两个 3x3 卷积(未填充卷积)的重复应用组成,每个卷积后跟一个修正线性单元 (ReLU) 和一个步长为 2 的 2x2 最大池化操作,用于下采样。 在每个下采样步骤中,我们将特征通道的数量加倍。 扩展路径中的每一步都包含对特征图进行上采样,然后进行 2x2 卷积(“上卷积”),将特征通道数量减半,与收缩路径中相应裁剪的特征图进行串联,以及两个 3x3 卷积,每个卷积后跟一个 ReLU。 由于每次卷积都会丢失边界像素,因此需要进行裁剪。 在最后一层,使用 1x1 卷积将每个 64 分量特征向量映射到所需数量的类。 该网络总共有 23 个卷积层。

二、Fully Convolutional Network
全卷积网络(FCN)是一种主要用于语义分割的架构。 它们仅采用局部连接层,例如卷积、池化和上采样。 避免使用密集层意味着更少的参数(使网络训练速度更快)。 这也意味着 FCN 可以处理可变的图像尺寸,因为所有连接都是本地的。
该网络由用于提取和解释上下文的下采样路径和允许本地化的上采样路径组成。
FCN 还采用跳跃连接来恢复在下采样路径中丢失的细粒度空间信息。
三、SegNet
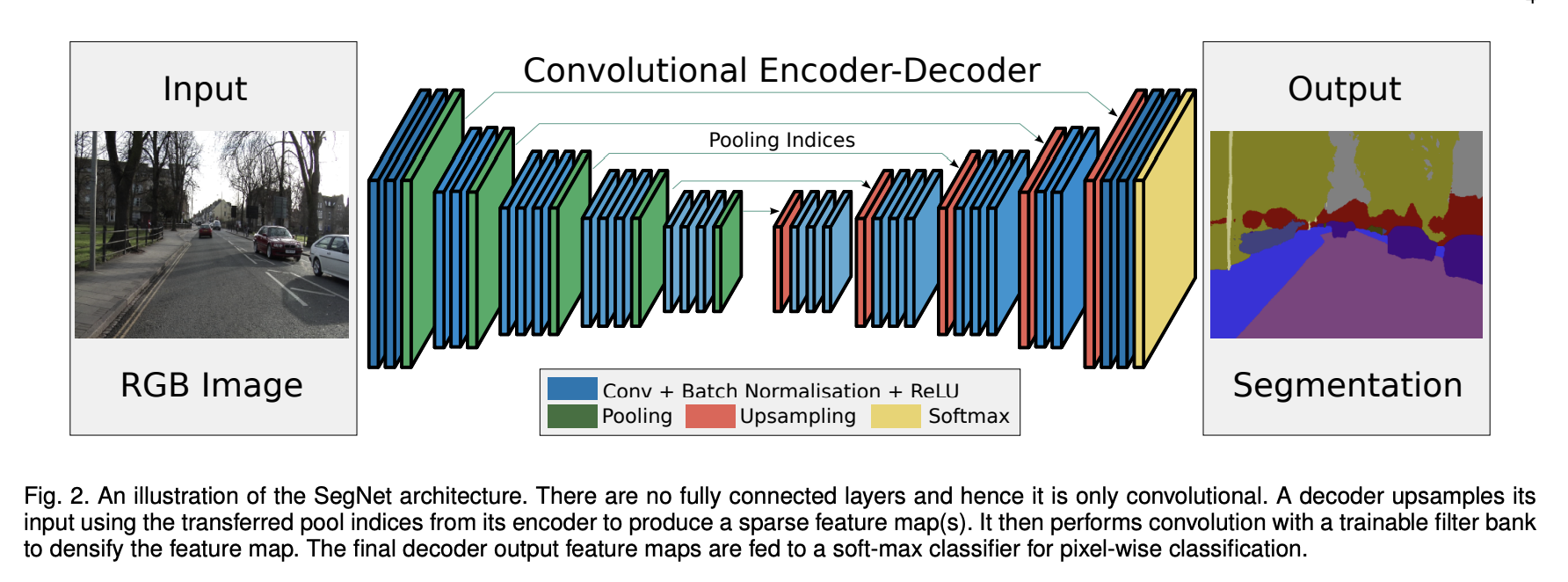
SegNet 是一种语义分割模型。 该核心可训练分割架构由编码器网络、相应的解码器网络和像素级分类层组成。 编码器网络的架构在拓扑上与 VGG16 网络中的 13 个卷积层相同。 解码器网络的作用是将低分辨率编码器特征图映射到全输入分辨率特征图以进行像素级分类。 SegNet 的新颖之处在于解码器对其较低分辨率输入特征图进行上采样的方式。 具体来说,解码器使用在相应编码器的最大池步骤中计算的池索引来执行非线性上采样。
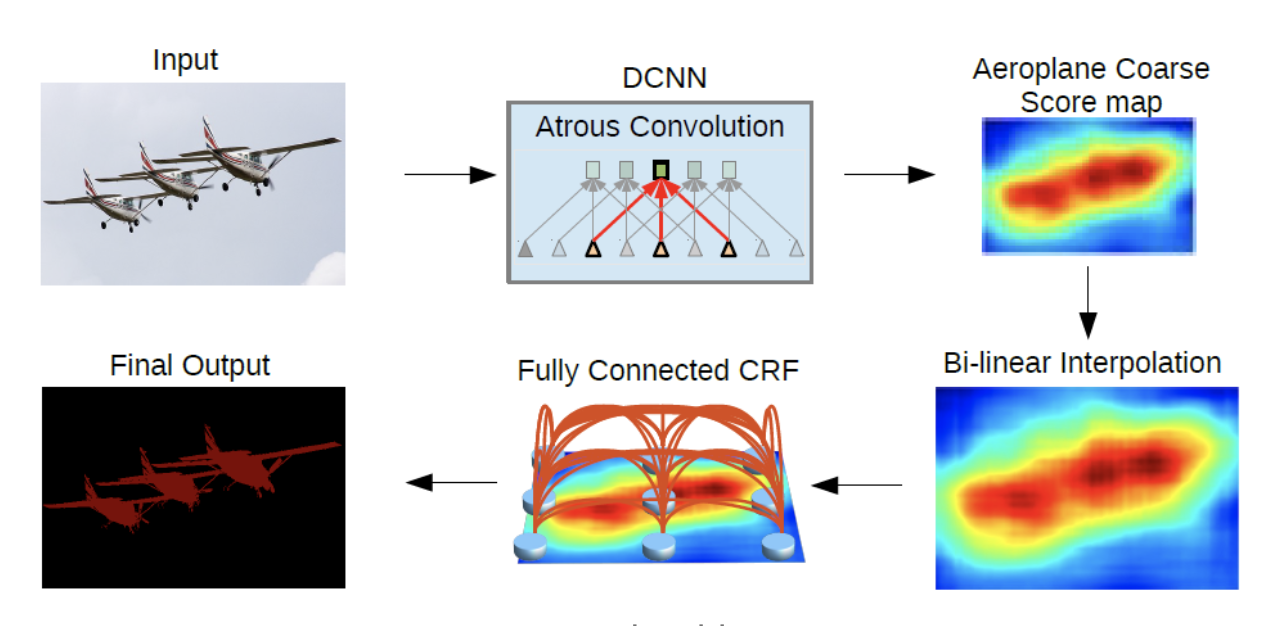
四、DeepLab
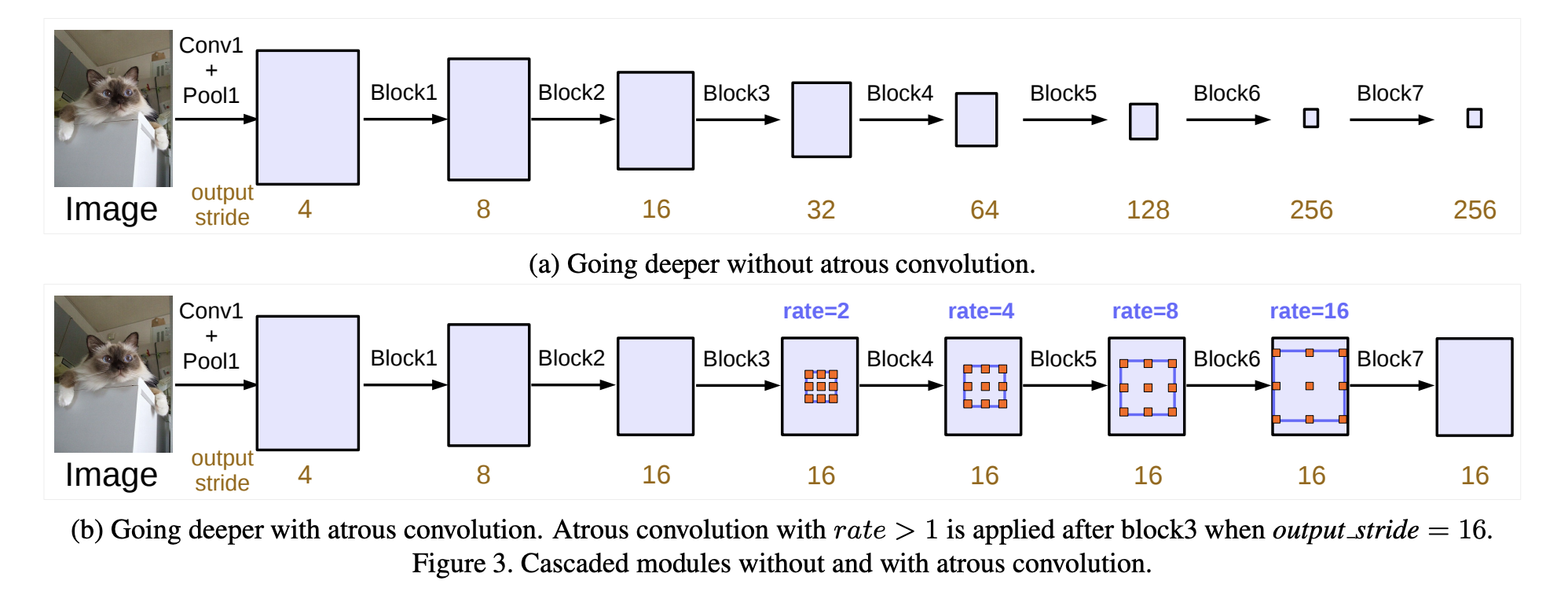
DeepLab 是一种语义分割架构。 首先,输入图像使用扩张卷积通过网络。 然后对网络的输出进行双线性插值,并通过全连接的CRF对结果进行微调,得到最终的预测。

五、DeepLabv3
DeepLabv3 是一种语义分割架构,它在 DeepLabv2 的基础上进行了一些修改。 为了处理多尺度的对象分割问题,设计了采用级联或并行的空洞卷积的模块,通过采用多种空洞率来捕获多尺度上下文。 此外,DeepLabv2 的 Atrous Spatial Pyramid Pooling 模块增强了编码全局上下文的图像级特征,并进一步提高了性能。
ASSP 模块的变化是,作者在模型的最后一个特征图上应用全局平均池化,将生成的图像级特征输入到具有 256 个滤波器(和批量归一化)的 1 × 1 卷积,然后对 特征到所需的空间维度。 最后,改进的 ASPP 由 (a) 一个 1×1 卷积和三个 3 × 3 卷积组成,当输出步长 = 16 时,速率 = (6, 12, 18)(全部具有 256 个滤波器和批量归一化),以及 ( b) 图像级特征。
另一个有趣的区别是不再需要 DeepLabv2 的 DenseCRF 后处理。
六、UNet++
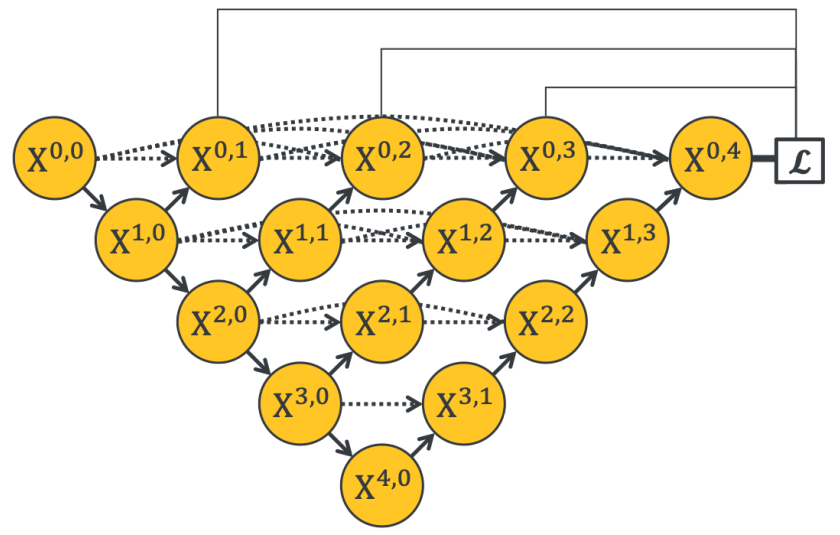
UNet++是一种基于U-Net的语义分割架构。 通过使用密集连接的嵌套解码器子网络,它增强了提取的特征处理,据作者报道,它在电子显微镜 (EM)、细胞、细胞核、脑肿瘤、肝脏和肺结节医学图像分割方面优于 U-Net 任务。
七、PSPNet
PSPNet(即金字塔场景解析网络)是一种语义分割模型,它利用金字塔解析模块,通过基于不同区域的上下文聚合来利用全局上下文信息。 局部和全局线索共同使最终的预测更加可靠。 我们还提出了一个优化方案
给定输入图像,PSPNet 使用预训练的 CNN 和扩张网络策略来提取特征图。 最终的特征图大小为
1/8 输入图像的。 在地图顶部,我们使用金字塔池模块来收集上下文信息。 使用我们的 4 级金字塔,池化内核覆盖图像的整个、一半和一小部分。 它们被融合为全局先验。 然后我们在最后部分将先验与原始特征图连接起来。 接下来是卷积层以生成最终的预测图。
八、EfficientDet
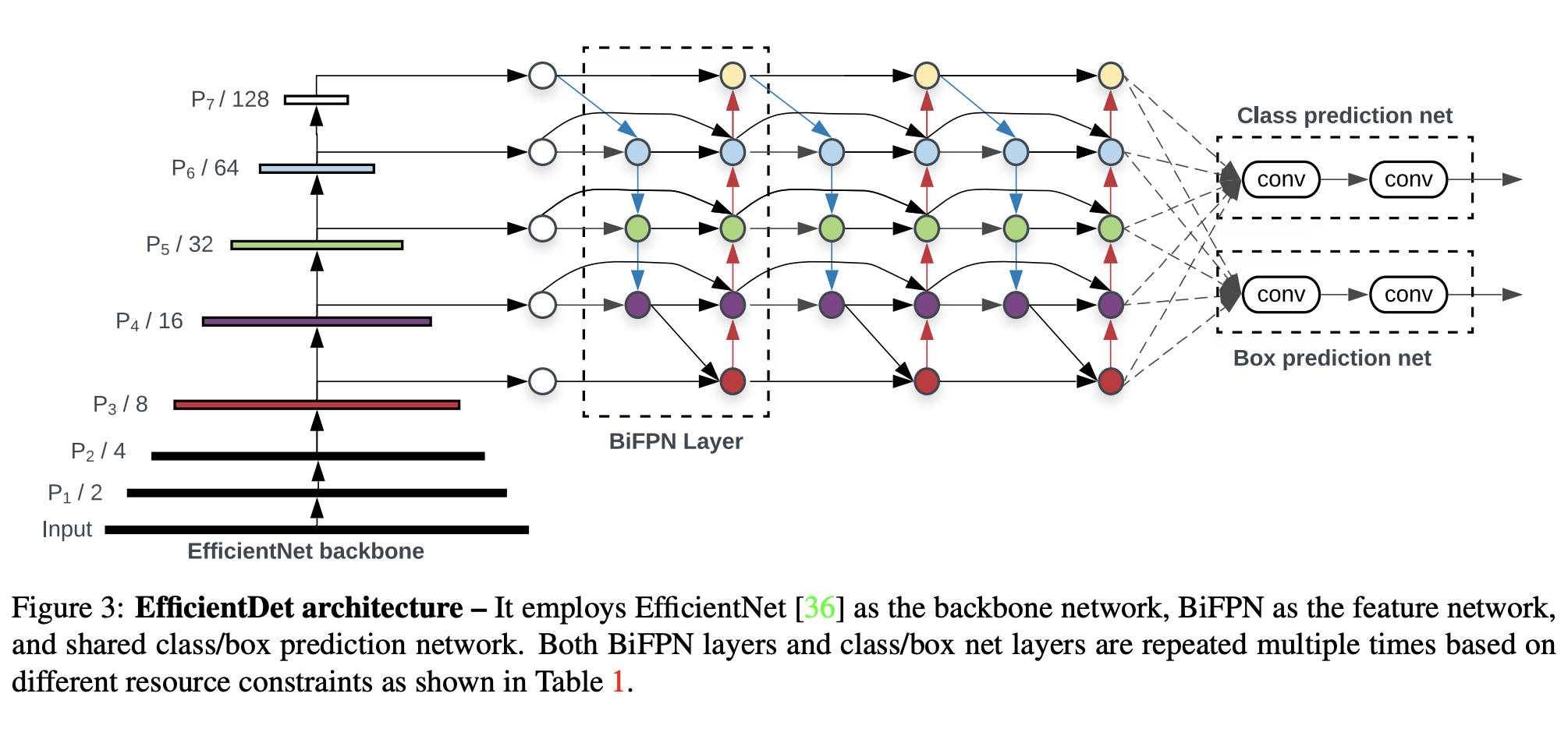
EfficientDet 是一种对象检测模型,它利用多种优化和主干调整,例如使用 BiFPN,以及统一缩放所有主干、特征网络和框/类预测的分辨率、深度和宽度的复合缩放方法 同时网络。
九、SegFormer
SegFormer 是一个基于 Transformer 的语义分割框架,它将 Transformer 与轻量级多层感知器 (MLP) 解码器结合在一起。 SegFormer 有两个吸引人的功能:1)SegFormer 包含一个新颖的分层结构 Transformer 编码器,可输出多尺度特征。 它不需要位置编码,从而避免了位置代码的插值,当测试分辨率与训练分辨率不同时,位置代码的插值会导致性能下降。 2)SegFormer避免了复杂的解码器。 所提出的 MLP 解码器聚合来自不同层的信息,从而结合局部注意力和全局注意力来呈现强大的表示。
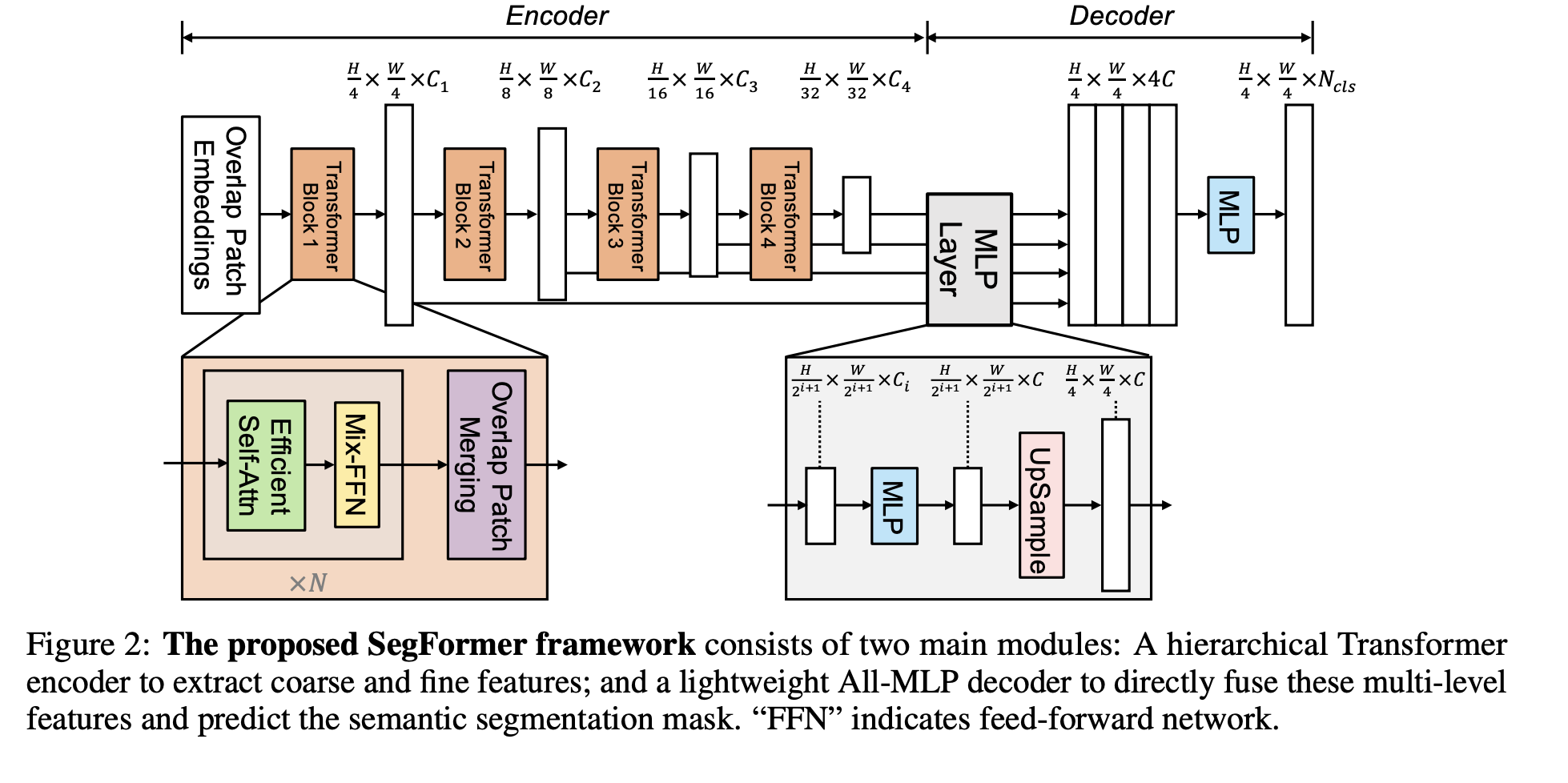
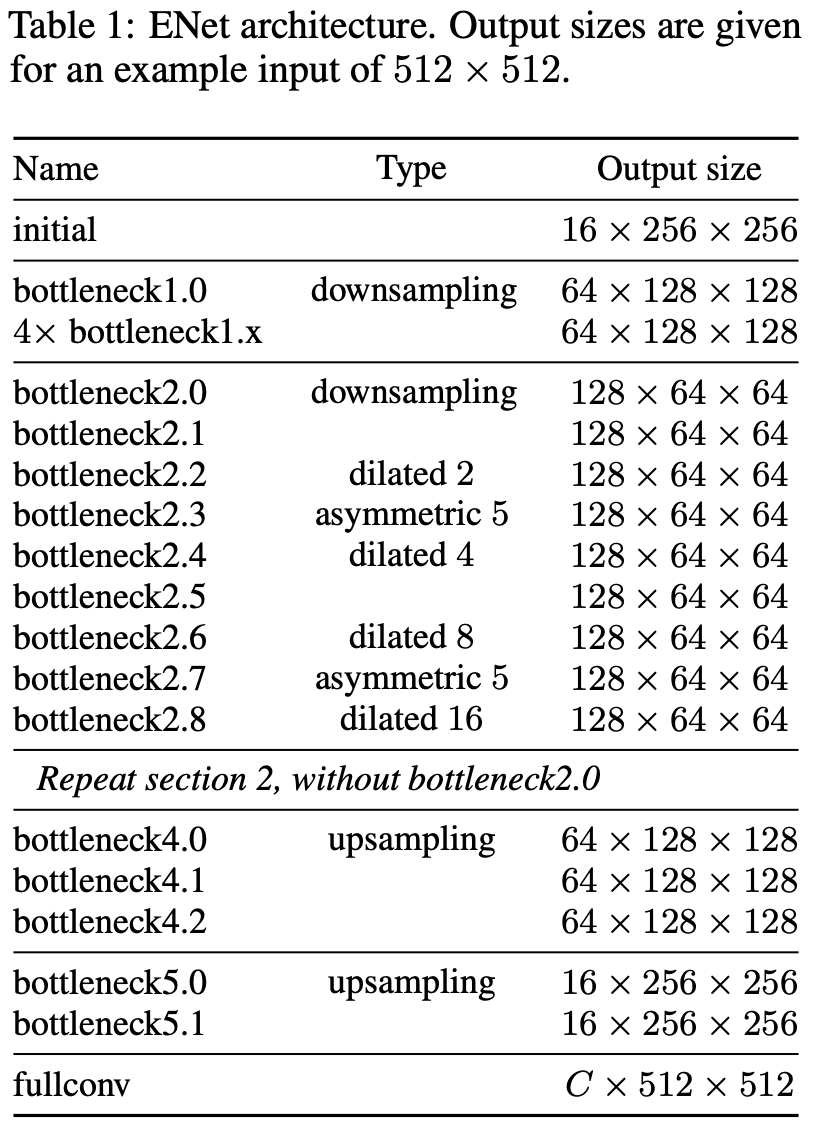
十、ENet
ENet 是一种语义分割架构,采用紧凑的编码器-解码器架构。 一些设计选择包括:
使用 SegNet 方法对 y 进行下采样,保存最大池化层中选择的元素索引,并使用它们在解码器中生成稀疏上采样映射。
早期下采样可优化网络的早期阶段并降低处理大型输入帧的成本。 ENet 的前两个块大大减少了输入大小,并且仅使用一小组特征图。
使用 PReLU 作为激活函数
使用扩张卷积
使用空间丢失