论文信息
题目:Multi-object navigation in real environments using hybrid policies
作者:Assem Sadek, Guillaume Bono
来源:CVPR
时间:2023
Abstract
机器人技术中的导航问题通常是通过 SLAM 和规划的结合来解决的。
最近,除了航路点规划之外,涉及(视觉)高级推理重要组成部分的问题也在模拟环境中得到了探索,这些问题大多通过大规模机器学习来解决,特别是强化学习、离线强化学习或模仿学习。
这些方法要求智能体学习各种技能,例如局部规划、绘制对象和查询所学习的空间表示。与航点规划(PointGoal)等更简单的任务相比,对于这些更复杂的任务,当前最先进的模型已经在模拟中进行了彻底的评估,但据我们所知,尚未在真实环境中进行评估。
在这项工作中,我们重点关注 sim2real 转变。
我们的目标是具有挑战性的多对象导航(Multi-ON)任务[41],并将其移植到包含原始虚拟 Multi-ON 对象的真实副本的物理环境。
我们引入了一种混合导航方法,它将问题分解为两种不同的技能:
(1) 路点导航通过经典 SLAM 与符号规划器相结合来解决,
(2) 探索、语义映射和目标检索则通过经过训练的深度神经网络来处理监督学习和强化学习的结合。
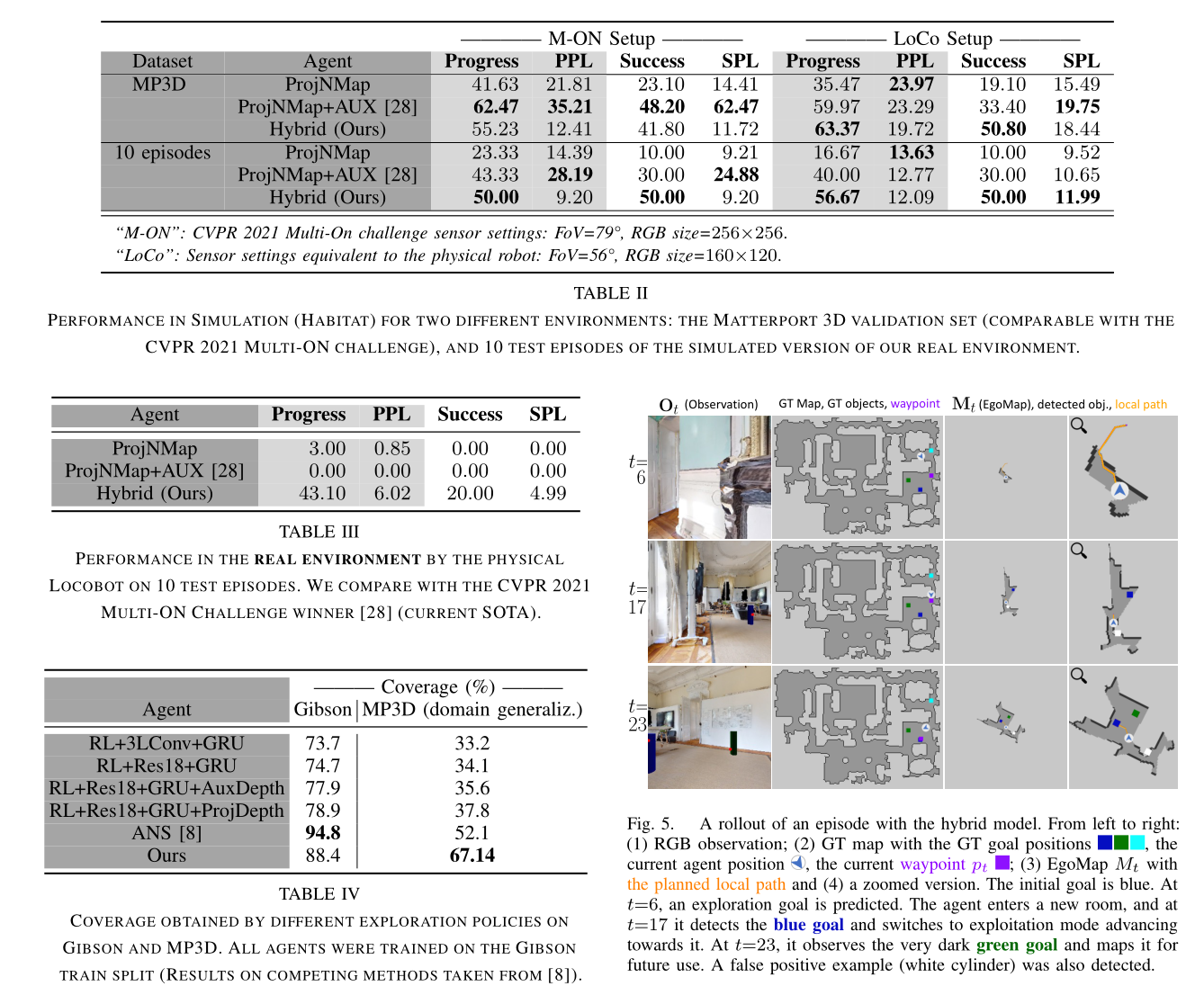
我们在模拟和真实环境中展示了这种方法与端到端方法相比的优势,并且在该任务上优于 SOTA [28]。
Introduction
机器人导航已经从准备充分的环境中的简单路径点导航问题发展到涉及视觉和语义概念的高级推理的复杂任务。当策略从模拟转移到物理机器人的真实环境时,它们会出现性能下降和缺乏鲁棒性的情况。这主要是由于模拟与现实之间的真实性差距**(“sim2real 差距”),以及难以探索导航问题中固有的大量变化因素**,例如房间布局、家具、纹理和其他房间细节、罕见的局部场景几何形状等。
最近有一种模块化方法的趋势,它将问题分解为分层部分 [8]、[4] 和混合方法,将最短路径规划器(符号或经过训练的)与经过训练的策略相结合。虽然这些方法已被证明具有更高的样本效率[32],但最先进的方法仍在模拟中进行评估,并且缺乏对真实机器人的彻底测试。
在这项工作中,我们解决了多对象导航 [41] 的挑战性问题,与 K 项物品场景 [5] 类似,需要代理按规定的顺序顺序导航一组对象。这个任务定义有利于代理能够学习在内部空间表示中映射所看到的对象,因为后面在情节中导航到它们可以增加奖励。这使得它在像 ObjectNav 这样的简单任务中脱颖而出,其中探索和当前观察的反应性局部规划的综合能力足以解决任务。
我们的目标是 sim2real 迁移,据我们所知,我们是第一个在真实物理环境中对多对象导航方法进行全面性能评估的人,请参见图 1。虽然更简单的任务(例如 PointGoal)已在在真实的机器人[23]、[34]中,对更复杂任务的训练模型的评估很少或不存在。我们提出了一种新的导航方法,其设计选择是由优化实际环境中的性能的目标驱动的。

我们提出了一种新的混合方法,将问题分解为两部分:
- “Good Old Fashioned Robotics”(GOFR),处理与语义无关的经典导航方面,例如可导航空间的检测和定位(几何 SLAM)与地图上的路点导航相结合。
- Semantics through Machine Learning, 即映射视觉推理所需的语义概念并利用它们;利用布局规律探索环境中最有前途的区域
在导航过程中,经典的 SLAM 算法 [24] 以张量/地图的形式创建并维护 2D 度量表示,并使用激光雷达输入在其上定位机器人。使用深度神经网络从视觉 RGB-D 观测中提取的高级特征形成空间和语义点云,其空间坐标与度量表示对齐,见图 2。
组合的混合表示满足相关子的需求。 -智能体所需的技能:
(i)确定过去是否观察到目标物体,
(ii)规划智能体和探索区域之间的最佳轨迹,以及
(iii)确定环境中未探索区域的边界以及下一个中间子目标,以防环境需要探索以找到下一个目标。所有这些子技能都是单独设计和训练的,这可以限制训练的样本复杂性。
这项工作的贡献如下:
(i)我们引入了一种多目标导航的混合方法,将经典的度量 SLAM 和路径规划与经过监督学习和 RL 训练的学习组件相结合;
(ii) 我们在真实环境中重现 Multi-ON 基准测试 [41],其中我们放置目标对象的制造复制品,用于最初模拟的目标环境;
(iii) 我们将所提出的方法与真实环境中的端到端训练方法进行比较,特别是与 CVPR 2021 MultiON 竞赛 [28] 的获奖作品进行比较,我们在真实和模拟环境中都表现出色。
Related Work
(这部分没太多有价值的)
Hybrid Planning and Navigation
我们的目标是 Wani 等人[41]引入的多对象导航(Multi-ON)任务,特别是 3 个对象变体:在每个情节中,智能体必须找到 3 个圆柱形对象 G n , n = 1 , 2 , 3 G_n,n = 1, 2, 3 Gn,n=1,2,3,按照预定义的顺序,其中 G n G_n Gn 是要查找的第 n 个对象,并且需要在每个目标处调用 Found 操作。剧集持续时间限制为 2,500 个环境步骤。在每个步骤 t,智能体接收一个以自我为中心的 RGB-D 观察 O t ∈ R h × w × 4 O_t ∈ R^{h×w×4} Ot∈Rh×w×4、一个激光雷达框架以及来自 8 个类别的当前目标对象的类别标签。
在导航过程中,代理根据激光雷达输入构建度量鸟瞰占用图,并使用度量 SLAM [39] 在其上进行自身定位。该二值图与重叠的语义点云相结合,其中包含关键对象的位置及其语义类别,这些是通过对象检测器从 RGB 输入中检测到的。检测和建图通过 SLAM 算法的定位模块进行协调。
Navigation
在两个不同的级别上分层执行。在较高级别(图 2 中的外环)上,生成 2D 航路点坐标 pt=(x, y) 并将其提供给较低级别控制器(内环),其任务是使用维护的占用地图导航到航路点。高级控制器在两种不同的策略之间切换:
➀ Exploration- 当目标物体尚未被观察到时,即机器人探索环境,最大化覆盖范围。这是通过 RL 训练的学习策略来完成的,见下文。
➁ Exploitation——当目标对象被观察到并因此成为语义点云的一部分时,其位置被视为新的路径点并提供给本地规划器。
Metric EgoMap
为了收集沿其路径的导航信息并更有效地重新访问之前看到的区域,代理构建了所谓的 EgoMap,这是一个以其当前位置为中心并与其前进方向对齐的固定空间分辨率的占用网格。
在真实的机器人上,该地图是使用 RTABMap [24] 库获得的。它使用基于图形的 SLAM 算法和闭环功能,这是一种利用 RGB-D、激光雷达和里程计传感器数据的灵活设计。激光雷达和/或深度用于创建 2D/3D 局部占用网格,与初始位置依赖于里程计积分的节点相关联。
然后从 RGB 帧中提取的关键点创建描述符,以便于节点比较和回环检测。 RTABMap 还包括短期和长期内存管理、全局映射压缩和多会话映射。
在模拟中,我们利用特权信息,通过 Habitat-Sim 中的 Recast&Detour [1] 库生成的 NavMesh 投影来检索场景导航性的完整自上而下视图。然后,通过使用完美定位,直接在该自上而下视图上的代理视野中进行光线追踪,构建战争迷雾掩模。
真实方法和模拟方法都会生成一个全局地图,我们在该地图上应用由代理当前姿势参数化的简单仿射变换来获取 EgoMap。
Exploration
是基于机器学习的主要模块。与最近的嵌入式 AI 工作相比 [4]、[8],该策略不采用第一人称 RGB 输入,而是采用度量 SLAM 算法生成的 EgoMap Mt。这大大简化了任务并提高了采样效率,并且由于避免了闪电、颜色和纹理的变化,因此最大限度地减少了 sim2real 差距。该策略是外循环的一部分,预测 2D 航路点坐标 pt。
由于多种原因,该问题是部分可观察到的:
(i) 并非场景的所有区域在任何时间点都已被观察到;
(ii) 出于效率原因,EgoMap Mt 并未覆盖整个场景,因此当智能体导航到距离观察区域足够远时,可能会忘记观察到的区域;
(iii) 在环境中存在不确定性的情况下,即使理论上完全可观察的问题(MDP)也可以转化为 POMDP(“认知 POMDP”),这是机器人技术的标准情况,正如最近在[18]中所显示的那样。
因此,我们为该策略注入了隐藏记忆 h t h_t ht 并使其循环出现。
策略 π 需要能够预测多模态分布,因为有多个有效轨迹可以有效地探索环境。我们通过归纳偏差将其纳入策略中,这迫使预测通过空间热图 Ht,从中对所选航路点位置进行采样。在采样之前,我们通过掩蔽将热图限制在未探索的区域。这种选择还导致了一个更可解释的模型,因为目标探索点的分布可以可视化(参见第四节)。
这可以形式化如下(另请参见图 3):

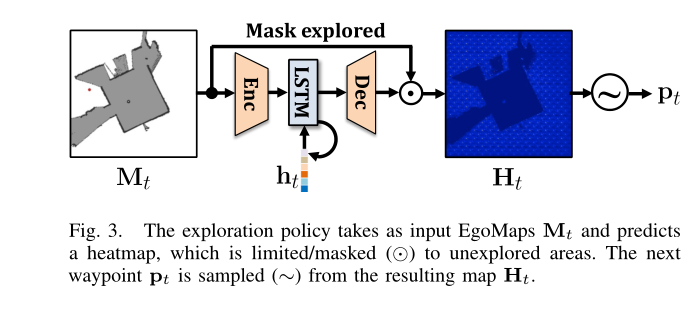
Local Navigation
本地导航 — 到航路点 p t p_t pt 由分析规划器执行,该规划器计算当前占用 EgoMap Mt 上的最短路径。这不一定是最佳路径,因为地图不等于(未观察到的)GT 地图和中间区域待穿越的区域(甚至路径点 p t p_t pt)可能未被探索。
我们采用动态规划器 D ∗ D^* D∗,它计算经典假设下的最短路径,并在新信息可用时重新规划。由于我们优化了我们的方法,使其在实际环境中稳健且高效,与最近的工作 [32]、[7] 不同,我们选择 D* 规划器而不是常用的快速行进方法 [37]。实际路径的可行性和规划的速度是这种设计选择背后的两个主要原因。
Stabilizing training
稳定训练——如上所述,在不确定条件下使用 D ∗ D^* D∗ 的局部规划产生的潜在失败和次优轨迹也会对勘探策略的训练过程产生负面影响。该策略是外循环的一部分,预测航路点 p t p_t pt,仅在完成完整的本地导航过程后才收到奖励。局部规划中的噪音会影响强化学习训练过程的稳定性并导致缺乏收敛。
我们通过训练与本地策略接口的探索策略来解决这个问题,并对其施加了长度限制。探索策略预测的从当前位置到下一个路点 pt 的完整轨迹被分成一系列距离为 0.3m 的小子目标,本地策略仅限于其中 5 个子目标。如果达到航路点 pt,或者达到 5 个子目标的限制,则将控制权交还给外循环。这种选择导致了稳定的训练,并且训练后的策略很好地转移到了有针对性的探索任务,而无需改变。对本地规划长度的相同限制也适用于部署时,这提高了实际条件下的鲁棒性,并使复杂的恢复行为变得过时。
Object Detection and Mapping
对象检测和映射 - 被构建为来自当前 RGB-D 帧 ot 的语义分割任务,我们通过根据模拟器中的特权信息计算出的 GT 掩码进行监督。预测器是 DeepLab v3 网络 [12],使用深度信息和情景里程计对掩模中检测到的对象进行反向投影并与 EgoMap 对齐。请注意,深度和里程计在真实机器人/真实环境评估设置中都是有噪声的。
High-level decisions
高层决策完全是手工制定的,因为这会带来稳健且可转移的决策过程,而可以说不需要学习。考虑到我们的决策选择,只需要一种类型的决策,是进行探索还是利用(即朝着目标导航)。这是根据当前目标对象是否已在映射时被观察到而采取的。如果已检测到同一类的多个对象,则选择最有可能检测到的位置(就分段对象像素而言)。要映射的对象需要最小数量的像素
Experimental
Conclusion
我们已将 Multi-ON 任务扩展到真实环境,据我们所知,我们在这些设置中对该任务进行了首次实验评估。
我们引入了一种混合模型,它解开了航点规划和语义,显着减小了 sim2real 差距,并且优于当前仿真中 SOTA 的 E2E 训练模型。
未来的工作将集中于增强手工制定的高级策略,该策略需要对误报检测具有鲁棒性,这也是其他导航任务(例如 ObjectNav)中的常见挑战。