说明:最近在弄华为的mindspore的框架迁移,这个项目融合和很多MOT的前沿知识,主要关联方法很优秀。
多目标跟踪(MOT)的目的:是估计视频中物体的边界框和身份。
一、以前方法怎么做的(提出的问题):
通过关联分数高于一个设定的阈值的检测框来得到身份特征,但是检测分数较低的,或者被遮挡的,运动模糊的,都会被简单的剔除,这样就会导致问题:真实物体的缺失,碎片轨迹化。
二、本文论文如何解决这个问题的:
提出了一种简单、有效、通用的关联方法,通过将几乎每个检测框关联起来,而不是只将高分的检测框进行跟踪。
解决问题流程:
对于低分数的检测框,利用与轨迹的相似性来恢复真实的图像,并且过滤掉背景。
本文应用了9个不同的最先进的跟踪器来验证关联方法的有效性。
本文的跟踪器,也是创新点(ByteTrack)。
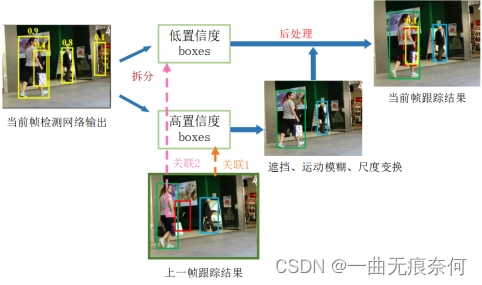
三、提出的问题如图所示:

下面这幅图,显示了以前的方法只是把得分高的关联起来,相同颜色的框代表相同的身份。

下面这幅图展示了本文的方法,虚线框用卡尔曼滤波器进行与先前预测的轨迹框进行IOU的轨迹匹配。

充分利用检测框从高分到低分的匹配过程,本文的关联方法,我们首先根据运动相似度或外观相似度将高分检测盒与轨迹进行匹配。
采用卡尔曼滤波器来实现预测新轨迹框的位置。相似度可以通过预测框和检测框的IOU或者行人身份特征距离来计算,上面的b图就是第一次匹配的结果。
我们在不匹配的轨迹之间进行第二次匹配,即在红框中的轨迹,以及在使用相同运动相似度的低分数检测盒之间进行第二次匹配。
图C显示了第二次匹配后的结果。检测分数较低的被遮挡者与之前的轨迹正确匹配,并去除背景(在图像的右侧)。
四、关联方法--Byte的创新:
第一次关联:
假设上图表示的是当前帧的关联策略,那么该操作的输入分别是前一帧的所有跟踪框的信息的卡尔曼滤波预测结果和当前帧的检测网络检测得到的置信度高于阈值的检测框,即上图中的粉红色的框框取的部分。(为了方便画图,我将KF操作包括在了关联1里面)
后续操作便是经典的IoU匹配和匈牙利算法寻优,得到当前帧的跟踪结果。关联1结束以后,为得到匹配的跟踪框和检测框将保留(图中的D_remain和T_remain),用于后续操作。
第二次关联:
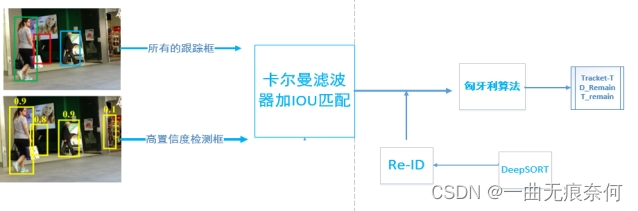
对于低置信度的检测框,由于目标往往处于严重遮挡和严重运动模糊的状态,所以外观相似度特征(比如ReID)非常不可靠,而相比较而言IoU匹配是更佳的选择,鉴于此,在关联2中,作者仅仅只使用了IoU,而并未引入外观相似度。
BYTE的创新在于检测和关联的连接区域,低分数的检测框是促进两者发展的桥梁。
我们采用了最近的高性能检测器YOLOX来获得检测框,并将它们与我们提出的Byte相关联。
在MOT挑战中,ByteTrack在MOT17[44]和MOT20[17]上排名第一,在MOT17和77.3MOTA,77.3IDF1和63.1HOTA。
相比 deep sort,ByteTrack 在遮挡情况下的提升非常明显。但是需要注意的是,由于ByteTrack 没有采用外表特征进行匹配,所以跟踪的效果非常依赖检测的效果,也就是说如果检测器的效果很好,跟踪也会取得不错的效果,但是如果检测的效果不好,那么会严重影响跟踪的效果。
- BYTE的工作原理:
如果有遮挡的检测,都是从高分到低分,例如被遮挡的物体在之前可能是可视物体,检测的分数也比较高,这个时候建立轨迹。但是当物体被遮挡时候,通过检测框与轨迹的的位置的重合度也就是IOU就能把被遮挡的物体从低分框中挖掘出来,保持了轨迹的连贯性。
(卡尔曼滤波)用于在变化的动态系统中,由当前状态和观测值相融合估计下一个状态。这是一个迭代的过程,也是一个数据融合的过程。
- Byte的输入是一个视屏序列,以及一个对象检测器Det。我们还设置了一个检测评分阈值(τ)BYTE的输出是视屏的轨迹T,每个轨迹包含每一帧中对象的边界框和特征。(Byte算法的3到13行)
- 在分离了高分检测框和低分检测框时候,我们采用卡尔曼滤波器来预测T中的每个轨道的当前帧。(14到16行)
- 第一次关联是在高分检测框Dhigh和所有轨迹 T(包括丢失的Tloss的轨迹))之间执行的。
- 相似度#1可以通过IoU或检测盒Dhigh与预测的轨迹T之间的Re-ID特征距离来计算。然后,我们采用匈牙利算法来完成基于相似度的匹配。我们把不匹配的检测框保留Dremain中以及不匹配的轨迹保留在Tremain中(算法1中的第17到19行)。
- Byte是高度灵活的,并可以兼容其他不同的关联方法。并且我们将Byte应用于9种不同的最先进的跟踪器,并在几乎所有的指标上都取得了显著的改进。
- 第二次关联在低分数检测框Dlow和第一次关联后的轨迹仍然保留在Tremain之间执行。
- 我们保留了Tremain−中不匹配的轨道,并且只需删除所有不匹配的低分数检测框,因为我们把它们视为背景。(BYTE算法的第20行至第21行)。
- 因为低分数检测框包含严重的遮挡和运动模糊,而外观特征不可取,所以单独使用IOU作为相似度很重要,并且在第二次关联中不采用外观相似性。
- 在关联完成后,从轨迹T中删除掉未匹配的轨迹Tremain,这里为了实现更长范围的联系,将Tremain放到了Tloss中,这时候当Tlost中出现的次数超过了30帧时候,从将它轨迹从T中删除,否则我们仍然保留在Tlost中(算法22行)
- 在第一次关联后从不匹配的高分检测框Dremain中初始化新的轨迹(算法23行到27行),每个单独帧的输出是当前帧中轨迹T的边界框和标识,但是不会输出Tloss的方框和标识。
- Byte的输入是一个视屏序列,以及一个对象检测器Det。我们还设置了一个检测评分阈值(τ)BYTE的输出是视屏的轨迹T,每个轨迹包含每一帧中对象的边界框和特征。(Byte算法的3到13行)
- 在分离了高分检测框和低分检测框时候,我们采用卡尔曼滤波器来预测T中的每个轨道的当前帧。(14到16行)
- 第一次关联是在高分检测框Dhigh和所有轨迹 T(包括丢失的Tloss的轨迹))之间执行的。
- 相似度#1可以通过IoU或检测盒Dhigh与预测的轨迹T之间的Re-ID特征距离来计算。然后,我们采用匈牙利算法来完成基于相似度的匹配。我们把不匹配的检测框保留Dremain中以及不匹配的轨迹保留在Tremain中(算法1中的第17到19行)。
- Byte是高度灵活的,并可以兼容其他不同的关联方法。并且我们将Byte应用于9种不同的最先进的跟踪器,并在几乎所有的指标上都取得了显著的改进。
- 第二次关联在低分数检测框Dlow和第一次关联后的轨迹仍然保留在Tremain之间执行。
- 我们保留了Tremain−中不匹配的轨道,并且只需删除所有不匹配的低分数检测框,因为我们把它们视为背景。(BYTE算法的第20行至第21行)。
- 因为低分数检测框包含严重的遮挡和运动模糊,而外观特征不可取,所以单独使用IOU作为相似度很重要,并且在第二次关联中不采用外观相似性。
- 在关联完成后,从轨迹T中删除掉未匹配的轨迹Tremain,这里为了实现更长范围的联系,将Tremain放到了Tloss中,这时候当Tlost中出现的次数超过了30帧时候,从将它轨迹从T中删除,否则我们仍然保留在Tlost中(算法22行)
- 在第一次关联后从不匹配的高分检测框Dremain中初始化新的轨迹(算法23行到27行),每个单独帧的输出是当前帧中轨迹T的边界框和标识,但是不会输出Tloss的方框和标识。
通过Det获得detection boxes和scores,同时基于Thing和Tlow将所有的检测框分成两部分Dhigh和Dlow,将分数值超过Thigh的检测框归到Dhigh中,将分数低于阈值的Tlow的检测框放入Dlow中。
到对于所有轨迹中的每一个track构建kalman滤波器。
在高分检测框和所有轨迹间进行关联。(相似性计算是通过IoU,匹配是同过匈牙利算法实现。对于IoU小于0.2的拒绝匹配)。并得到没有能够匹配上轨迹的检测框以及没有和检测框匹配上的轨迹,注意在这边匹配中也可以加入Re-ID特征。
第二次关联是在和之间进行关联,对于未匹配上的detection boxes看作是背景直接删除,对于未匹配上的轨迹记作,使用IoU作为相似度量,并没有使用appearance(低置信度的appearance不可靠)
在关联完成之后,从轨迹中删除掉unmatched tracks,这里为了实现long-range association,是将放到了中,只有当他出现在中的次数超过30帧时,才将轨迹从中删除
在第一次关联之后,从没有匹配上的高置信度检测框中初始化新的轨迹。对于中的每一个检测框,如果检测分数超过,并且在连续的两帧中出现了,我们初始化一个新的track(轨迹)。
ByteTrack框架:
模型基于high-performance detector YOLOX以及本文提出的association 方法BYTE。 YOLOX是将YOLO系列detectors切换到anchor-free模式,并且采用了Mosaic,Mixup,SimOTA等来取得SOTA的性能。
- 骨干网络同YOLOv5相同,采用CSPNet以及附加的PAN头。
- 在骨干网络之后有两个decouple头,一个用于分类,另一个head用于回归。同时增加了一个IoU-aware branch来预测predicted boxes和gt boxes之间的IoU。
- 回归部分通过GIoU loss约束;类别以及IoU heads通过binary cross entropy loss 约束。
六、实验的细节:
对于BYTE,默认的检测分数阈值为0.6,。对于MOT17、MOT20、HiEve的基础评估,我们只使用IOU作为相似度指标。在线性分配中如果检测框和轨迹框之间的IOU小于0.2,则拒绝匹配,对于丢失的轨迹,我们保留了30帧,防止再次出现。
对于BDD100K,我们使用UniTrack[68]作为Re-ID模型。在消融研究中,我们使用FastReID[27]提取MOT17的Re-ID特征。
对于ByteTrack,检测器为YOLOX,以yolox-x为骨干,以coco预训练的模型为初始化权值。训练策略为在MOT17,CrowdHuman,Cityperson以及ETHZ上训练80格epoch
输入图像尺寸为.1440*800。在多尺度训练中,最短的边的范围从576到1024.数据集的增强包括Mosaic和Mixup。在8块tesla V100上使用batch size大小为48训练,使用SGD 0.001学习率,0.0005权重衰减以及0.9的动量,在第一个epcoh使用warm up,同时采用余弦退火策略。FPS在单个GPU上使用fp16精度和batch size1。
Warm up lr策略就是在网络训练初期用比较小的学习率,线性增长到初始设定的学习率。训练时间为12小时
SORT可以看作是我们的基线方法,因为这两种方法都只采用卡尔曼滤波来预测物体的运动。我们可以发现,BYTE将SORT的MOTA度量从74.6提高到76.6,IDF1从76.9提高到79.3,并将ID从291降低到159。这突出了低分数检测框的重要性
主要是在遮挡和运动模糊上有了改善。
-
- 我们注意到在MOT17中有一些完全被遮挡的行人,它们在地面真实注释中的可见比为0。
- 由于几乎不可能通过视觉线索来检测它们,所以我们通过轨迹插值来获得这些对象。
ByteTrack 的检测器部分采用 YOLOX。
一、在数据关键的部分,和 SORT 一样,只使用卡尔曼滤波来预测当前帧的跟踪轨迹在下一帧的位置,预测的框和实际的检测框之间的 IoU 作为两次匹配时的相似度,通过匈牙利算法完成匹配。这里值得注意的是 ByteTrack 没有使用 ReID 特征来计算外观相似度,也就是说仅仅使用了运动模型。
二、为什么没有使用ReID 特征?
作者解释:第一点是为了尽可能做到简单高速,第二点是我们发现在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高,能够代替 ReID 进行物体间的长时刻关联。实验中也发现加入 ReID 对跟踪结果没有提升。
问题:因为跟踪模型强依赖于提取物体的外观特征,那如果追踪物体的外观基本一致时,现有模型的的表现如何?当前主流多目标跟踪数据集中物体的运动模式非常简单,近乎匀速直线运动,如果物体的运动模式非常复杂,多个物体互相来回穿梭,现有模型的的表现如何?