论文题目:A Simple Baseline for Multi-Object Tracking
论文链接:https://github.com/ifzhang/FairMOT
以往的MOT大多是基于tracking-by-detection的,首先对每一个frame做检测,再用re-Id,各种匹配关联算法进行data association,这两个步骤都是独立的。这篇文章提出了一个网络,可以将上述步骤进行结合,通过一个网络,同时得到检测结果(bbox,score)和re-Id feature,作者称之为one-shot方法。
随着multi-task learning的成熟,这种one-shot的方法开始流行。虽然能够大大减少inference time,但其accuracy仍然远低于two-shot方法。于是作者对此进行了几点讨论:

(1)Anchor不适用于re-Id
Anchor可能出现不同image patch预测同一个目标的情况,并且8倍的下采样对re-Id feature来说太粗糙。作者采用heatmap来检测物体的关键点,即一种pixel-wise的算法,而且identity classification也是在分辨率较高的特征图上进行的,消除anchor比较coarse的缺点;
(2)多层特征融合
针对不同大小的目标,需要融合不同尺度的feature map,作者采用了一种基于FPN的网络,即DLA34,具体backbone可参照下图中的Encoder-Decoder网络;
(3)ReID dimension
ReID的维度不应设置过大,低维度的特征效果更好,因为在数据较少的情况下,可以避免过拟合并提升tracking鲁棒性。

Architecture如上:
- backbone:DLA34,得到input宽高各四分之一的融合feature map( C ∗ H ∗ W C*H*W C∗H∗W);
- Detection:从特征图接入Detection head,得到三组输出heatmap( 1 ∗ H ∗ W 1*H*W 1∗H∗W),box size( 2 ∗ H ∗ W 2*H*W 2∗H∗W),center offset( 2 ∗ H ∗ W 2*H*W 2∗H∗W);
- Re-ID:得到Re-Id feature( 128 ∗ H ∗ W 128*H*W 128∗H∗W)。
Loss
(1)Heatmap是按照pixel-wise计算每个点是key point的可能性,某个点假如离obj越近,其值越大,接近于1,计算公式如下:
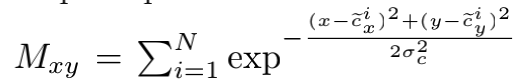
c这里就是每个obj除以缩放尺度4再向下取整后,对应特征图上的obj中心,xy表示feature map上的pixel位置。
为了平衡正负样本,这里采用focal loss:
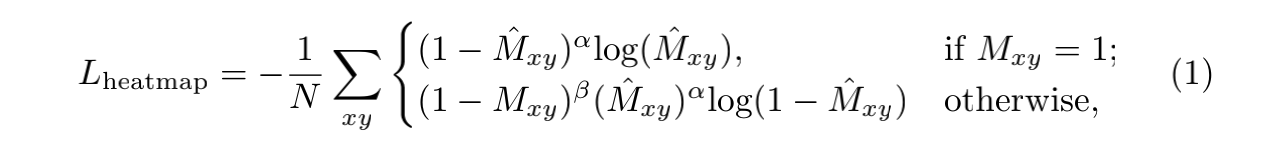
(2)offset和size的loss都采用简单的L1 loss:
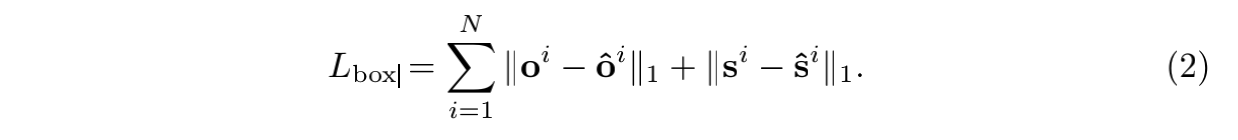
(3)id embedding采用的是softmax loss:
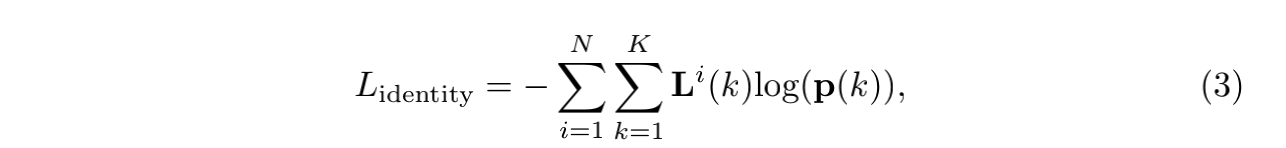
Inference
Inference阶段用在heatmap上做NMS筛掉非peak keypoints,linking的时候同时考虑Re-ID feature和IOU两个因素的distance,并采用了卡尔曼滤波这个motion model进行下一帧的推测。
Experiment
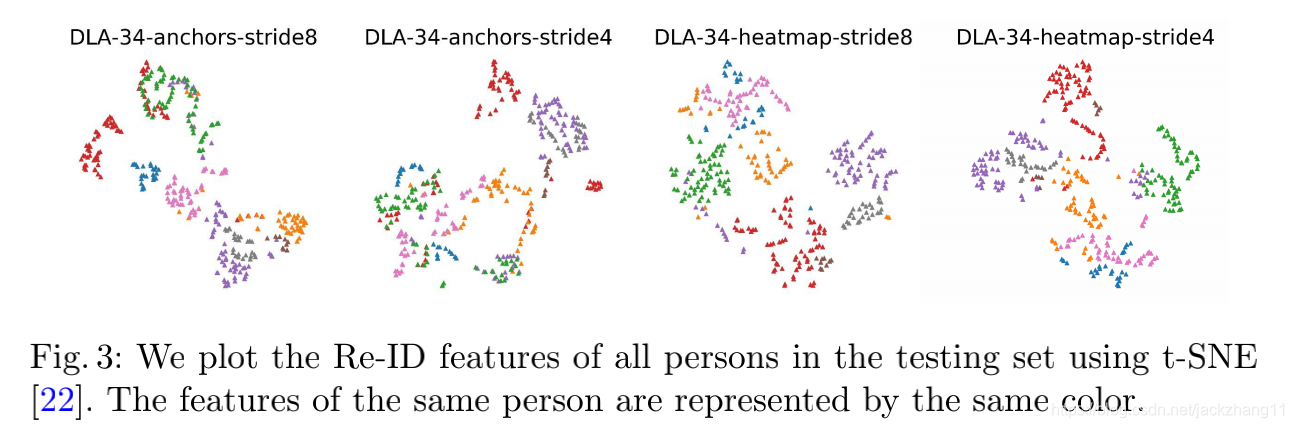
这种采用了heatmap的anchor free方法,不同类物体之间的特征分的比较开;而anchor-based方法的feature部分杂糅。
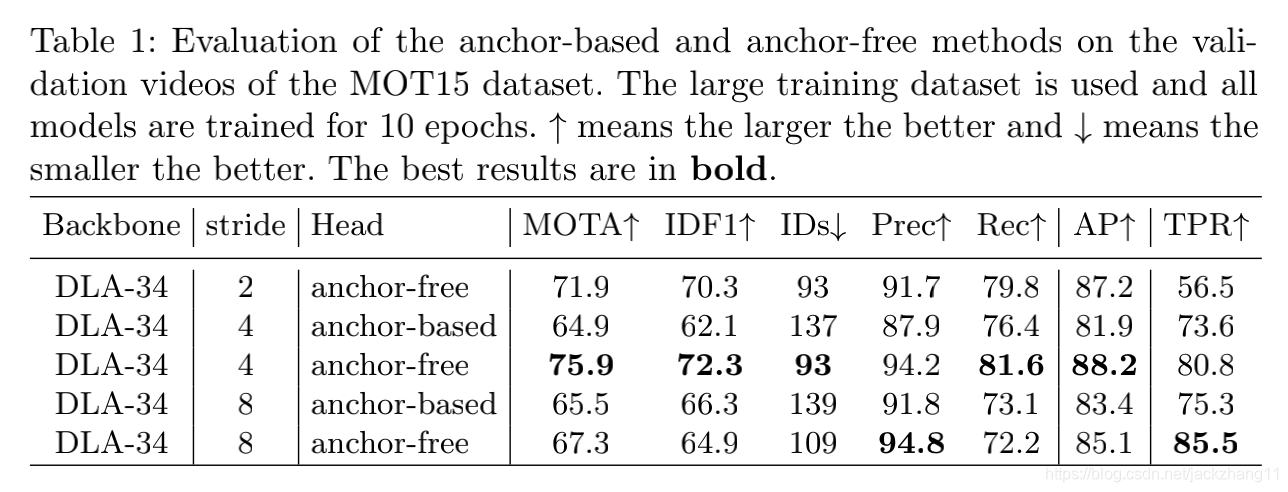
数据上验证anchor-free方法效果好,stride为8的时候比较coarse,stride为2对内存要求极高,因此stride为4是比较好且普适的。
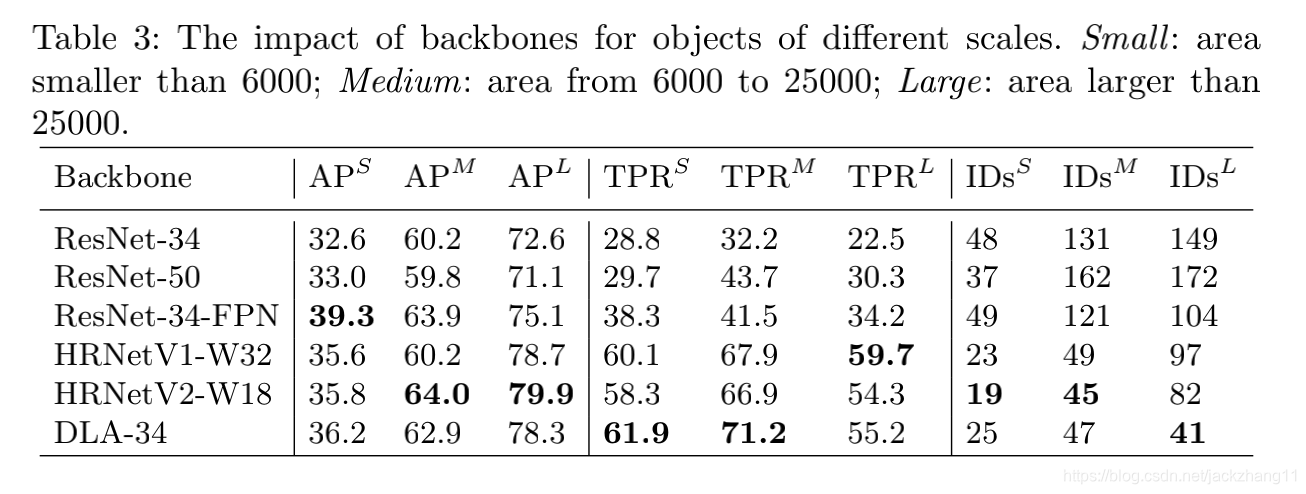
不同backbone的检测结果,这种基于FPN的架构明显优于传统的单尺度feature输出的网络。
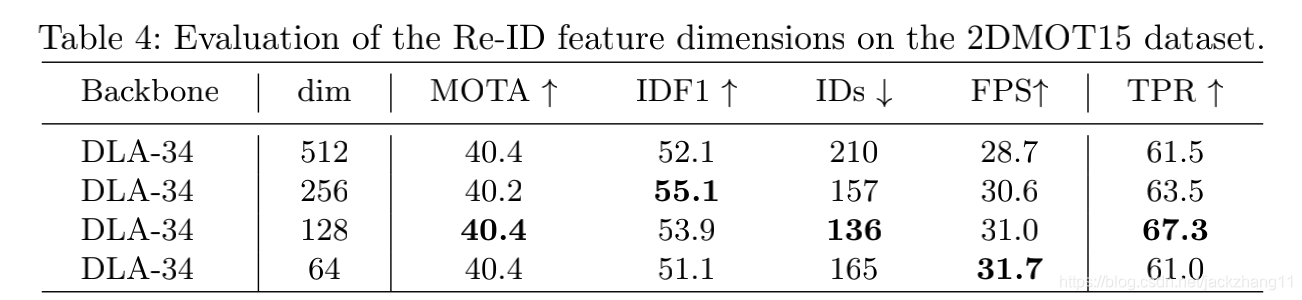
ReID feature的dimension讨论,低维度的特征相对较好一些。
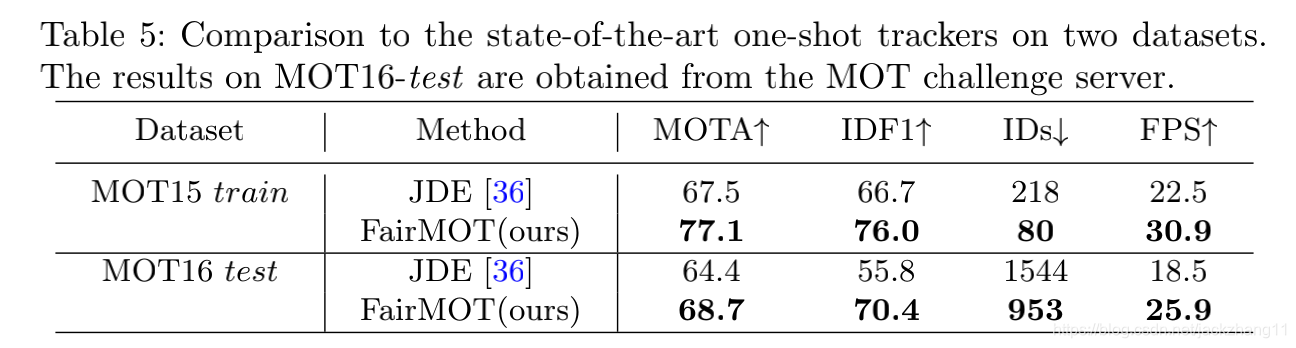
与SOTA的one-shot方法的对比,FairMOT效果更好。
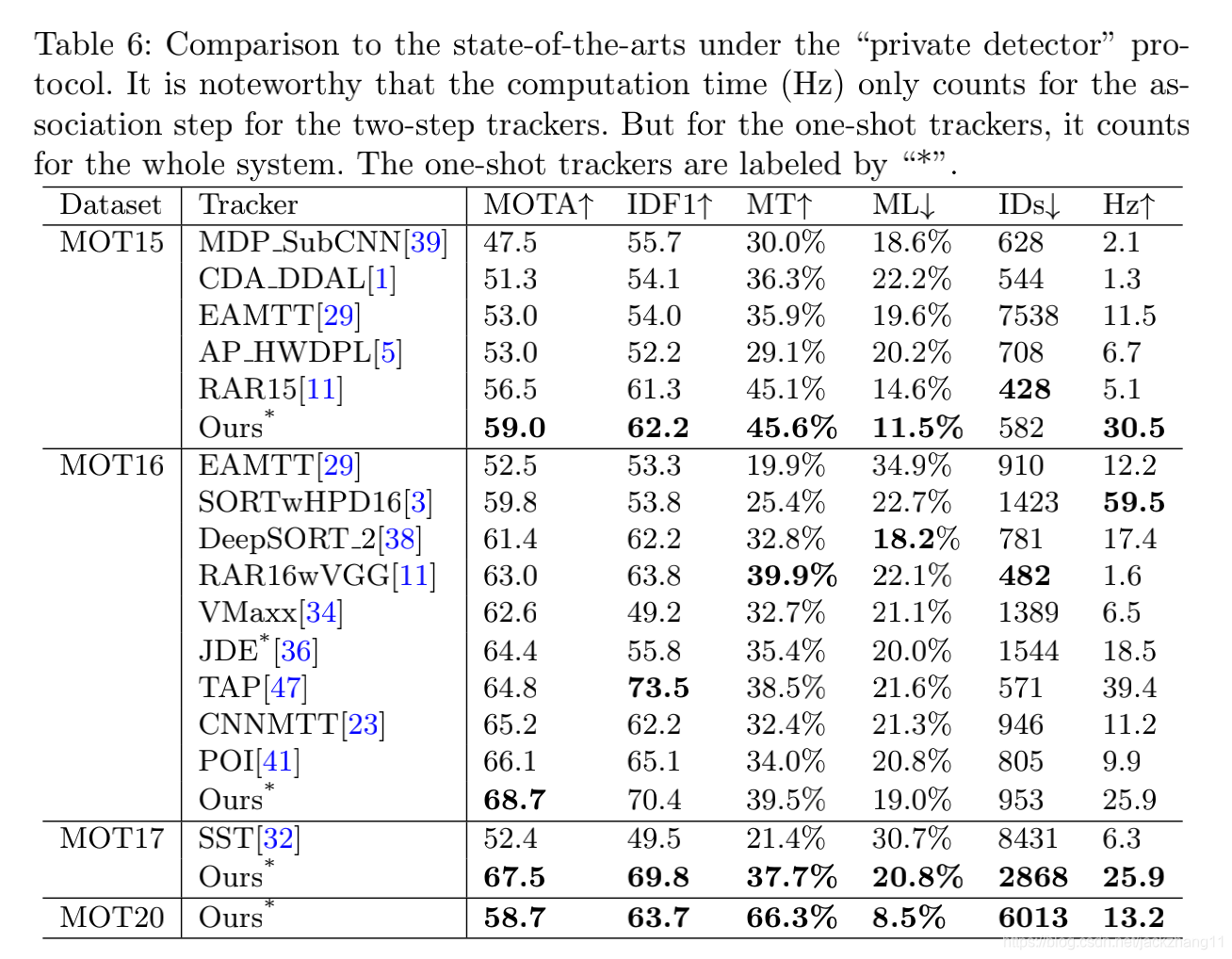
与一些two-shot方法对比,FairMOT不仅仅在速度上领先,在精度方面也不逊色于SOTA的two-shot方法。