论文地址:Towards Real-Time Multi-Object Tracking
Towards Real-Time Multi-Object Tracking
一、 摘要
传统的DBT范式下的MOT都是要经过两步骤:1.监测模型进行目标位置检测;2.外貌嵌入模型进行数据关联。两部分独立运作,不共享一些结构,会导致效率问题。并且现在实时MOT上的研究主要集中于关联阶段,但是本质上这只是关联的实时,但是MOT模型却无法实时。
本论文提出了一个目标检测和外貌嵌入可以共享学习的模型。方法上是将外貌嵌入模型整合进一个单阶段的检测,让模型可以在检测出目标的同时,输出相应的目标外貌嵌入。在此基础上,进一步提出了一种与联合模型相结合的简单、快速的关联方法。与之前的两阶段相比,计算量大大降低,更加快速,接近实时。
主要创新点:引入JDE联合检测和Embedding学习。接近实时,并且准确率堪比SDE(检测嵌入分离)模式。
二、 介绍
传统的DBT范式,将MOT分为两步:
- 检测阶段,用于检测目标在单一视频帧中的位置;
- 关联阶段,将检测的目标关联到之前的轨迹。
这意味着MOT存在两个密集型计算部分,一个检测网络,一个嵌入(Re-ID)网络。作者将这种检测和嵌入分开进行的命名为SDE。由于SDE的计算量比较大,所以实时很困难。
为了解决计算问题,简单思路是将检测和嵌入整合入同一个model中,共享低级特征,避免了重复的计算量。作者首先想到使用改版的双阶段检测器Faster-RCNN:
第一步,使用不变RPN网络,输出检测的边界框;
第二步,修改Fast-RCNN,将其改变为一个嵌入模型,将分类监督改变为参数学习监督。
但是尽管节省了计算量,但是速度还是不够实时。
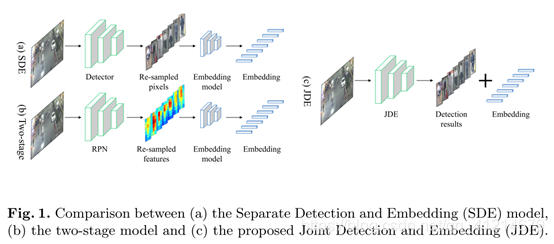
为了提升效果,在single-shot深度网络中引入JDE(联合学习检测和嵌入)。JDE即在检测出目标的同时输出相应检测框的外貌embedding。
对比下,SDE方法和双阶段方法分别重采样像素(边界框)和特征图进行特征表示, 边界框和特征图被单独喂到一个独立的Re-ID网络中进行外貌特征提取(图1)。该论文提到的JDE方法不仅接近实时,且精度堪比SDE方法。
论文中建立的JDE方法过程:
- 首先,数据集方面,他选择了带有行人检测和人物搜索的6个公开数据集组合成一个统一的大规模的多标签数据集。数据集中所有行人边界框都被标注,部分行人存在身份标签。
- 其次,网络模型方面,选择了FPN作为基础结构,探讨选择能够最好的学习嵌入信息的损失函数。
- 然后,我们将训练过程建模为一个多任务学习问题,包括锚分类、边界框回归和嵌入学习。为了平衡每个任务的重要性,我们使用独立任务的不确定性来动态地衡量性损失。提出一个简单的关联算法提升效率
- 最后,使用各种参数评估模型。
三、 检测和嵌入的联合学习(JDE)
1. 问题设置
假设训练数据集 { I , B , y } i = 1 N \{I,B,y\}_{i=1}^N { I,B,y}i=1N, I ∈ R c × h × w I∈R^{c×h×w} I∈Rc×h×w表示视频图像帧, B ∈ R k × 4 B∈R^{k×4} B∈Rk×4当前帧中k个目标的边界框注释。 y ∈ Z k y∈Z^k y∈Zk表示部分注释的身份标签, − 1 -1 −1表示没有身份标签。JDE的目的是输出预测的边界框 B ^ ∈ R k ^ × 4 \hat B∈R^{\hat k×4} B^∈Rk^×4以及外貌嵌入 F ^ ∈ R k ^ × D \hat F∈R^{\hat k×D} F^∈Rk^×D, D D D表示嵌入特征的维度.
再输出预测的同时并且要满足不同帧的带相同身份标签目标的嵌入特征距离应当足够近,不同身份标签的目标的特征嵌入差距足够大,这个距离可以是欧式距离或者余弦距离。
如果检测器足够准,并且满足上面提到的要求,那么即使是基础的匈牙利也可以很好的进行追踪。
2.结构
使用了FPN的结构,保证不同尺度目标的检测(本文生成了三种不同尺度的特征)。不同尺度的特征图送入多卷积层的预测头,输出一个 ( 6 A + D ) × H × W (6A+D) ×H×W (6A+D)×H×W的预测, A A A是分配给这个尺度的锚模板的数量, D D D是特征嵌入维度。
具体将输出分为三个部分送入是三个任务:
- 边界框分类分支:2A×H×W
- 边界框回归分支:4A×H×W
- 密集嵌入特征图分支:D×H×W

3.检测学习
检测分支类似于RPN,进行了两点修改:
- 我们重新设计了锚的数量、比例和纵横比,以便能够适应目标;
- 对于前后景的分类使用双阈值,设置IoU>0.5的为前景,IoU<0.4的为背景(并非传统的0.3,实验证明本实验0.4效果更好)。
检测学习产生两个损失,一个前后景分类损失L_α(交叉熵损失),一个边界框回归损失L_β(smooth L1损失)。
4.外貌嵌入学习
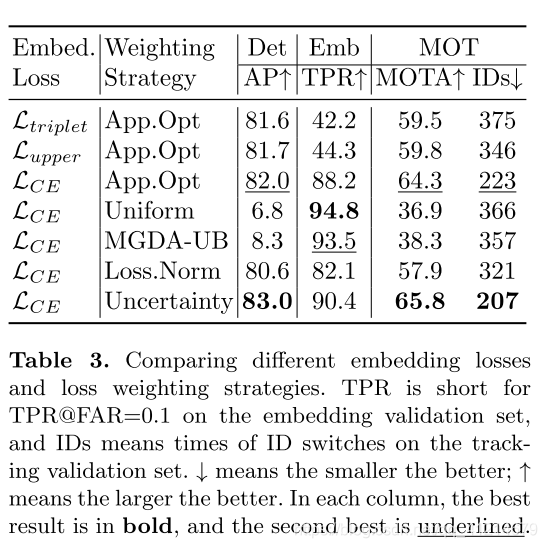
作者经过推测,认为交叉熵损失比三元组损失、改进三元组损失进行外貌嵌入学习要更加适合本模型:
L C E = − log exp ( f ⊤ g + ) exp ( f ⊤ g + ) + ∑ i exp ( f ⊤ g i − ) \mathcal{L}_{C E}=-\log \frac{\exp \left(f^{\top} g^{+}\right)}{\exp \left(f^{\top} g^{+}\right)+\sum_{i} \exp \left(f^{\top} g_{i}^{-}\right)} LCE=−logexp(f⊤g+)+∑iexp(f⊤gi−)exp(f⊤g+)
f ⊤ f^⊤ f⊤是一个mini-batch中被选为锚的实例,在这里,我们把正类(锚实例所属的类)的权值表示为 g + g^+ g+,把负类的权值表示为 g i − g_i^- gi−
具体的,如果一个锚框标记为前景,就会从密集嵌入图中提取他相应的嵌入,提取的嵌入喂入一个共享参数的全连接层,生成类级得分,对得分使用交叉熵损失。通过这种方式,来自多个尺度的嵌入共享同一空间,跨尺度的关联是可行的。如果嵌入的标签 y y y为 − 1 -1 −1即没有身份标签,则直接忽略这个嵌入的损失。
5.自动损失平衡
JDE的每个预测头可以认为是一个多任务学习问题,损失函数可以定义为如下:
L total = ∑ i M ∑ j = α , β , γ w j i L j i \mathcal{L}_{\text {total}}=\sum_{i}^{M} \sum_{j=\alpha, \beta, \gamma} w_{j}^{i} \mathcal{L}_{j}^{i} Ltotal=i∑Mj=α,β,γ∑wjiLji
M M M代表预测头数, w j i ( i = 1 … M , j = α , β , γ ) w_j^i (i=1…M,j=α,β,γ) wji(i=1…M,j=α,β,γ)代表损失权重。
如果采用枚举搜索的权重可能并不会产生最优解,这样的结果甚至会远离优化。因此选择一种使用独立任务不确定性进行自动搜索办法选择权重:
L total = ∑ i M ∑ j = α , β , γ 1 2 ( 1 e s j i L j i + s j i ) \mathcal{L}_{\text {total}}=\sum_{i}^{M} \sum_{j=\alpha, \beta, \gamma} \frac{1}{2}\left(\frac{1}{e^{s_{j}^{i}}} \mathcal{L}_{j}^{i}+s_{j}^{i}\right) Ltotal=i∑Mj=α,β,γ∑21(esji1Lji+sji)
s j i s_j^i sji表示每个体损失的独立任务不确定性,定义为可学习的参数。
6.在线关联
提出一种简单的关联方法,一个轨迹被描述为一个外貌状态 e i e_i ei和一个运动状态 m i = ( x , y , γ , h , x ˙ , y ˙ , γ ˙ , h ˙ ) m_i = (x,y,γ,h,\dot x,\dot y,\dot γ , \dot h) mi=(x,y,γ,h,x˙,y˙,γ˙,h˙)。其中 x , y x,y x,y表示边界框中心位置, h h h表示边界框的高, γ γ γ表示宽高比, x ˙ \dot x x˙表示沿着 x x x方向的速度。轨迹外貌特征 e i e_i ei初始化为第一次检测该目标的外貌嵌入。
所有可能参与匹配的轨迹集中存放于轨迹池。对于一个输入的帧,我们计算所有观测j检测值与池中轨迹之间的成对运动关联矩阵 A m A_m Am和外观关联矩阵 A e A_e Ae。利用余弦相似度计算外观亲和力,运动亲和力的计算使用马氏距离,利用这两个矩阵计算代价矩阵 C = λ A e + ( 1 − λ ) A m C=λA_e+(1-λ)A_m C=λAe+(1−λ)Am,利用匈牙利算法进行匹配。所有匹配的轨迹的运动状态 m i m_i mi使用卡尔曼滤波更新,外貌状态 e i e_i ei如下更新:
e i t = α e i t − 1 + ( 1 − α ) f i t e_{i}^{t}=\alpha e_{i}^{t-1}+(1-\alpha) f_{i}^{t} eit=αeit−1+(1−α)fit
α = 0.9 α = 0.9 α=0.9为动量, f i t f_i^t fit为当前帧匹配的检测的外貌嵌入。最后,如果连续出现在2帧中,未分配给任何轨迹的检测将被初始化为新的轨迹。如果轨迹没有在当前的30帧中更新,它将被终止。
对比SORT的根据时间的级联关联方法:
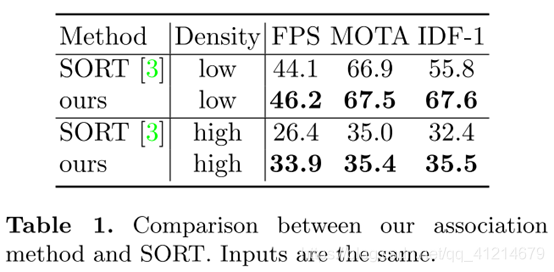
四、实验
1.对比不同损失函数之间的差距:
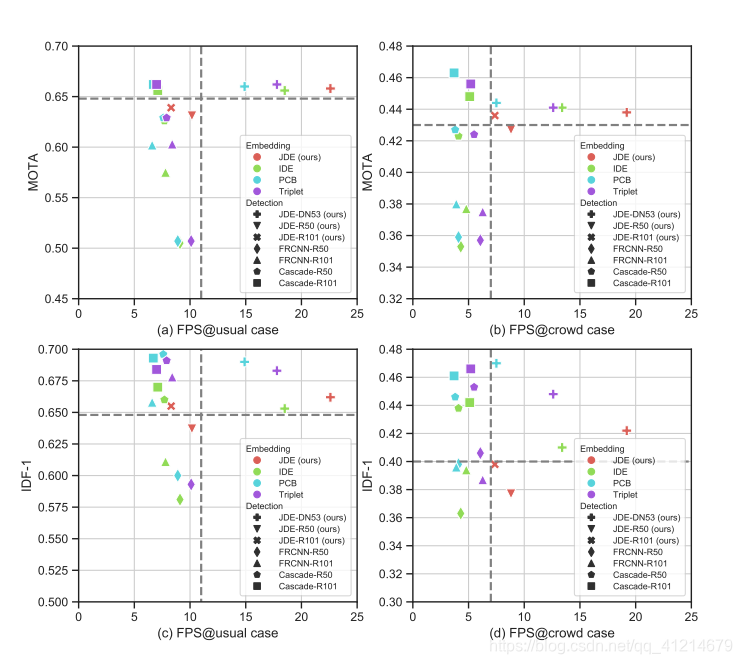
2.对比其他SDE模型:
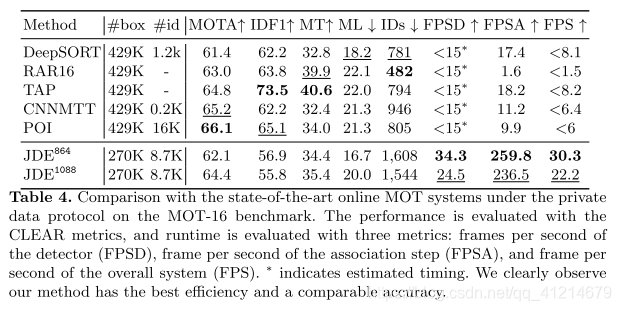
3.在MOT-16基准测试中与采用私有数据的SOTA在线MOT模型进行比较:
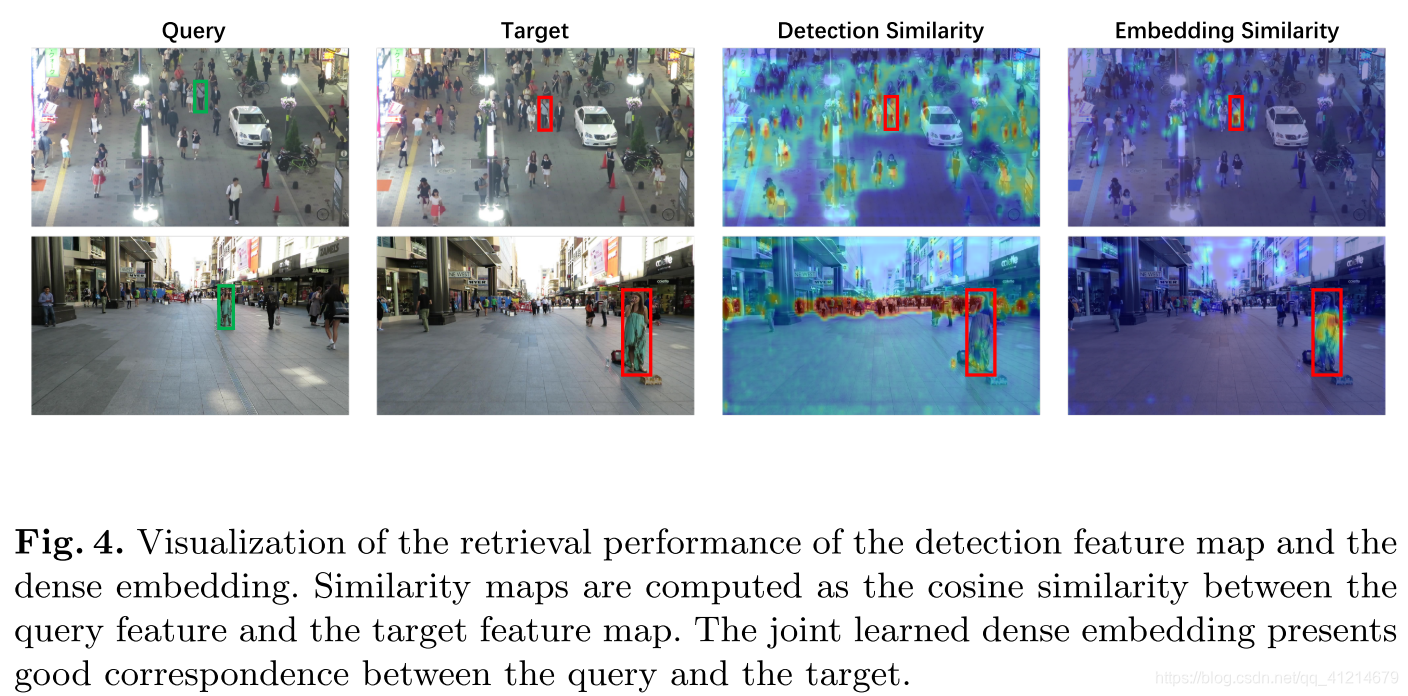
4.可视化
五、 思考与总结
该方法拥有一个低的IDF1得分却存在一个很高的IDSW,主要原因是由于当多个行人重叠的不精准的检测造成的,大多发生在轨迹路线的中间时刻,因此IDF1很低。
论文引入JDE,联合目标检测和外貌嵌入进一个共享模型,极大减少了MOT模型的运行时间,使他接近实时。同时,追踪的准确率也达到了当时的SOTA。