摘要:
数据关联是很多计算机视觉应用的重要组成部分,多目标跟踪就是其中的一个例子。典型的数据跟踪方法是找到一个图匹配方式或者一个网络流使得配对连接的代价最小,然而经常使用的是手工设计特征或者固定特征的线性函数。本文指出通过将优化问题表示为可微的函数反向传播学习数据关联的特征是必要。本文用上述思路解决多目标跟踪问题,所有的代价函数均可学习统一到一个end-to-end的框架中,达到比手工设定更好的水平,同时可以集成各种不同的输入。
- 引言:
多目标跟踪的任务是预测整个视频中所有实例的运动轨迹,他的主要挑战有遮挡、物体的快速运动、相机平台的运动等。是行为识别、视频监控和自动驾驶的基本模块。目前主要的解决思路为track-by-detection[7(粒子滤波),[15]嵌入式端的多目标跟踪]。第一步使用目标检测器用bounding box的形式提供可能的位置。然后将多目标跟踪问题形式化为数据关联问题给这些bounding box指定一个轨迹,描述每个实例随时间轨迹的变化。
二分图匹配[25(匈牙利算法)]经常被用于一种在线的方式指定当前帧的bounding box到当前的轨迹中[38(粒子滤波用于多目标检测与跟踪) 52(多目标跟踪ICCV2015)],离线的方式可以形式化为一种网络流去解决关联问题,包括关联轨迹的产生和死亡[27(孪生CNN跟踪),54(用网络解决多目标跟踪问题)]。第二部分给出了更多的例子,所有的关联问题可以在一个Linear Programming框架中解决。在LP框架中,所有变量的相互影响产生不同的代价,最终决定什么是成功的配对。所以设计一个很好的代价函数非常重要。虽然之前的工作大部分代价函数都是手工设计的,但是仍有一部分是通过数据学习得到的,但是他们并没有将问题当成一个整体来解决,只是学习一部分或者受线性函数的限制。
本文提出的范式可以学习所有变量任意参数的代价函数end-to-end去解决。通过平滑LP,双层优化的方法将代价函数所有参数的学习当成最小化预先定义的关联损失。这种凡是的好处在于灵活性通用性避免手工设计。我们的方法并没有限制到log-linear 模型这使得我们可以充分利用各种参数化的函数比如神经网络去预测戴佳佳。事实上,本文范式可以结合到任意网络的框架中,作为一个特殊的层。
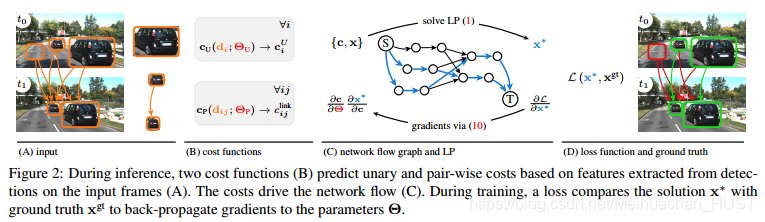
我们的方法是通用的可以用于多种关联问题。有以下优点,end-to-end训练;可以集成多种输入比如bounding box信息、时间信息、外观特征、运动特征等,这些参数可以一起训练,相比手工设计要好很多; - 相关工作:
多目标跟踪中的关联:在线的方法将当前帧的检测指定到现有的轨迹上[8,11,15,41]。轨迹被视为状态空间的建模,比如卡尔曼滤波和粒子滤波。将当前的检测指定到估计上的算法一般是匈牙利算法。离线的方法考虑整个视频序列。解决轨迹和检测配对问题的比较好的方法有网络的方法[54],所有的关联方法可以认为是线性规划
代价函数:[29,33,41]中的代价函数进依赖与检测置信度、时空距离。[54]和[53]通过颜色直方图引入了表观特征。其他工作还显式得学习一个相似度矩阵,然后用于跟踪。[31]分级关联,将轨迹片段合成一个轨迹。[27]学习一个孪生神经网络去比较两个检测框的外观特征,然后结合时空差别输入一个网络中。这些成对的代价被用于一个网络中。
将推断集成到学习中去:相比本文方法,最近已经有一些工作考虑训练阶段进行全推断。和本文工作类似的[49]提出通过一个结构化的SVM框架学习全部的损失。他指出,简单模型通过合适地学习代价函数,可以堪比复杂的跟踪方法。但是SVM限制了代价函数只能是线性的,相比之下,本文的双层优化更灵活,适用于非线性的情况。双层优化也被用于最近的优化图模型的损失,比兔分割和深度图重建。 - 跟踪深度网络
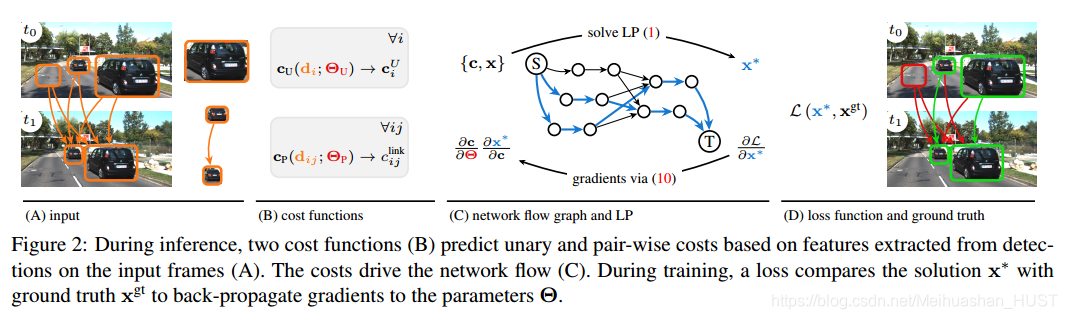
本文用多目标跟踪问题阐述end-to-end的关联方法。特别的,本文考虑tracking-by-detection的框架,记视频t帧的检测结果为d,b(d)表示空间位置,p(d)表示检测概率,t(d)表示帧号。对于每个检测结果,跟踪算法需要确定他属于哪个目标轨迹,或者认为他是虚警。轨迹由属于同一个实例的检测结果集构成Tk={d1k,d2k,d3k…dnk},这里的nk是第k个目标的轨迹的长度。k的个数也是未知的,需要推断。二分图匹配经常在在线跟踪中使用,也可以形式化为网络,使得本文的学习方法也是适用的。
3.1 网络流范式
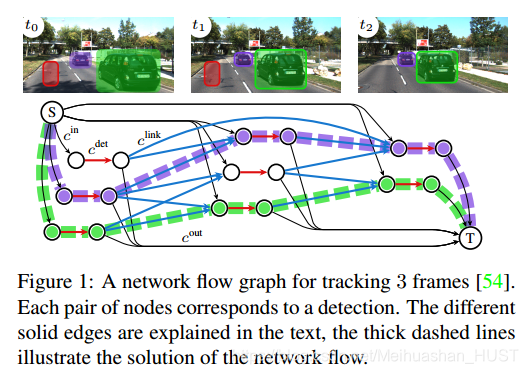
单帧图像每个检测结果被表示为具有两个节点的边(图中红色),与这个边相关的变量记为x(i)det,为了确定临近帧的检测结果是不是属于同一个轨迹,所以对满足t(di)<t(dj)和|t(di)-t(dj)|<Tt的检测进行全连接(蓝色),与这些连接相关的变量记为x(i,j)link。之所以跨帧连接是为了解决遮挡和漏检测的问题,同时为了减少图的规模,将两个检测空间位置差距较大的连接删掉。为了解决轨迹产生和死亡的问题,加入两个特别的节点源节点,与每帧检测的第一个节点连接(黑色)与之相关的变量为x(i)in。第二个结点与汇节点项连,与之相关的变量为x(i)out。
图中的每个变量和一个代价相关。四种变量定义四种代价cin,cout,cdet和clink,其中定点代价记为cU(cin,cout,cdet),配对代价cP(clink)。寻找全局最优解,可以形式化为一个线性规划问题
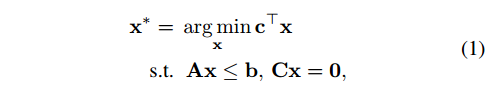
寻找一个x,使得cTx最小。其中x为所有的流变量,c为代价,M是问题的维度。其中0<=x<=1,这通过A=I,-I,b=1,0实现

这里的限制可以认为x只能是刚出现、与其他检测结果相关联、或者下一帧消失,但是为什么不是xin+xlink+xout=xdet呢,个人认为有可能出现单个的噪声,只和xin和xout连接,这样就不满足上式,但是满足文中的限制。只是不明白为什么C那样写就能表达这种限制呢
figure1中的虚线给出了最优的x。
这个范式最重要的部分是找到合适的代价c,去建模产生、消失和关联。最终的跟踪结果取决于c的选择。
3.2 end-to-end代价函数学习
本文的主要贡献在于提出一个灵活的框架可以用一个网络预测所有变量的损失。为了实现以上想法,本文用参数化的代价函数c(f,theta)代替固定的代价c。这里theta是需要学习的参数,f是输入数据。对于MOT任务来讲,输入数据可以是bounding box、检测分数、图像特征或者更专业的特征。
给定一段视跟踪序列的ground truth x(gt)和输入数据f,本文通过学习参数theta使得网络解的损失函数最小,这可以形式化为一个双层优化问题
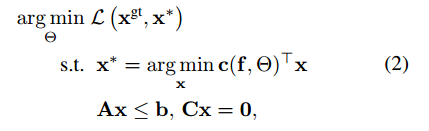
其中c和x都是变量,上层是一个损失函数,寻找theta也就是c使得损失函数最小,同时他的下层是一个跟踪网络。为了计算损失的梯度本文希望底层的优化问题是光滑的,但是box限制使得他并不光滑。
3.2.1 光滑底层优化问题
box限制可以通过log-barrier近似,问题可转化为
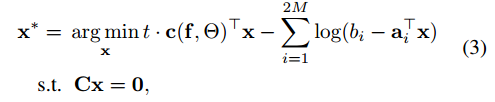
t是温度参数,控制近似的精度。aiT是A的行。线性等式限制可以通过分解x实现。x=x(z)=x0+Bz,这里引入z变量,Cx0=0,B=N©。这样转换之后,z就没有了限制

平滑之后的底层的优化问题如下
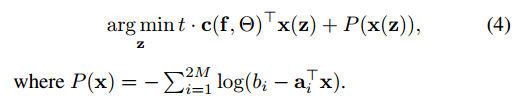
3.2.2 代价的梯度表示
给定一个底层优化问题,本文定义最终的学习目标为
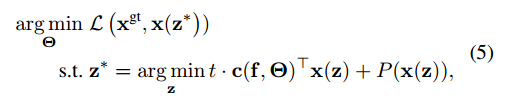
本文感兴趣的是计算损失L的梯度。我们可以写出L对c的梯度,根据链式法则,再饿到对theta的梯度,这里认为c(:,theta)是可微的。首先计算L对c的梯度
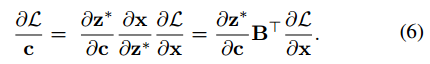
因为x(z)=x0+Bz
考虑z对c的偏导,首先求z,即
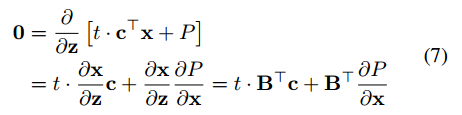
这里奇怪的是求导之后没有z了,上面都是c的一阶项,让x去保证等于0吗然后上式两边同时对c求导
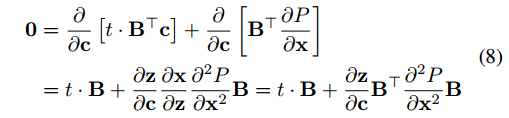
然后得到结果
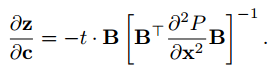
结合6式得
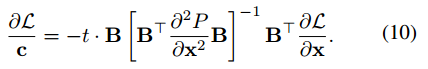
P对x的二阶导在4式中也容易写出
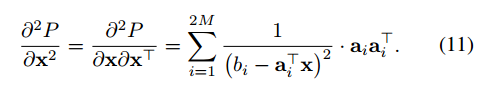
在补充的材料中,我们会显示10式与36(SVM中为平滑的底层优化问题)中得到的通解是等价的
3.2.3 讨论
训练需要解决(4)中的线性规划问题,这个通过任何凸优化器就可以求解。t建议取M/e其中e是超参数,决定了log barrier近似的精度,幸运的是一般结果对e的选取并不敏感,本文选取e=0.1。需要指出的是本文并不局限于解决MOT问题,他适用于需要学习代价函数和数据关联的问题。4的平滑和10求解梯度可以作为神经网络中的一个层。网络的前向和反向传播如下
3.3 定义ground truth和损失函数
为了学习参数theta,需要在损失函数中比较最优解x*和xgt。xgt定义了图的边取1还是取0.本文首先在单帧中将检测结果与bounding box的gt匹配。和目标检测器的评估类似,将最高分的检测与每个gt计算IoU,然后选0,5为门限。然后逐帧连接检测框,认为帧间距离最近的框应该连起来,属于同一个实例。其他的都认为是无效的。进而可以确定xin与xout的gt。
[50]指出的是不同类型的连接应该在损失函数中区分对待。本文中分为这么几种情况,FP-FP,TP-FP,TP-TP+,TP-TP-,TP-TP+far,他们具有不同的损失权重
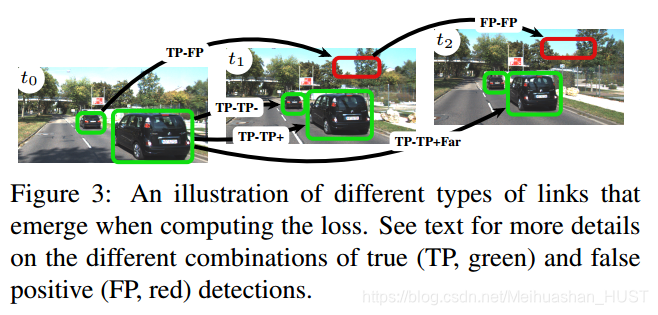
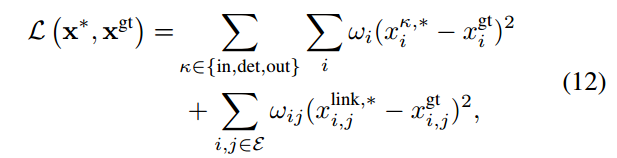
这里虽然每个结果都可以设置一个权重,不过一般默认都是1.有几种情况可以适当调整权重。1)模糊不清的边 FP-FP的连接虽然是错的但是保持了一致性,TP-TP+far也是类似的,所以惩罚太多不利于预测。建议w<1。2)为了影响精度和召回率,可以在所有的正例上添加权重wpr,增加wpr会增加召回率3)为了加强连接可以在xlink变量中添加权重wlink。最终我们使用了不同的权重方案和L1损失,具体的定义在4.3中。
3.4 跟踪模型
批量的选择,定义一个窗口大小W,以一定的步长step<W来滑动这个窗口,解决这个窗口中的LP问题。窗口和窗口之间用二分图匹配连接轨迹,不匹配的轨迹认为是新的实例。实际中,本文选取step=1,在每个窗口中输出W/2帧的结果,因为他既能利用之前也能利用之后的信息。 - 实验
在KITTI、MOT15和MOT16数据集上评估了本算法
4.1 学习特征VS手工特征
本文的主要贡献在于学习参数话的代价。为了比较学习参数的效果,本文采用了两个典型的手工设计代价
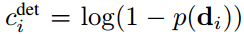
p(di)为检测分数
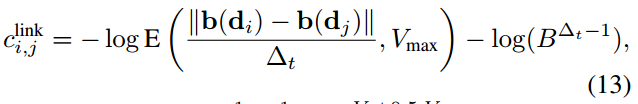
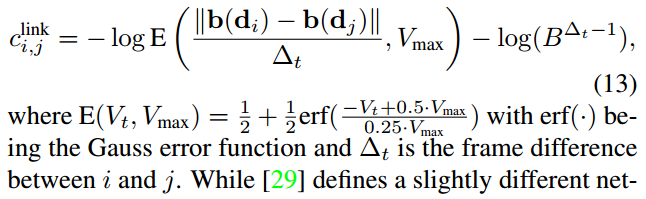
第二种
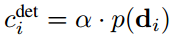
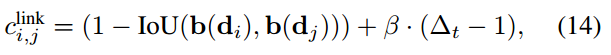
这里的cin=cout=C,还有Vmax,alpha、beta都网格搜索最大化。
另外对于节点的代价,本文还是使用相同的手工设计的代价函数,对于连接代价,本文分别使用线性模型(64节点的MLP)和2层32节点的MLP。输入的特征是两个box之间的差异,检测置信度、归一化的时间差和IoU.
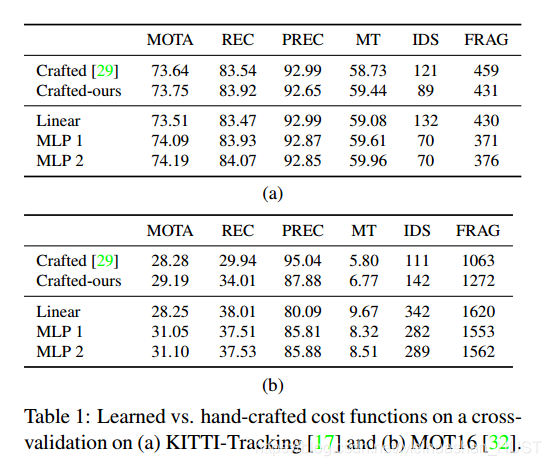
网络学习的结果要稍微好一些
最近一些工作显示,时间和外观特征有助于MOT。[10]提出时空特征ALFD比较两个检测结果,从特征点中得到统计特征组成一个288维的直方图。[27]使用RGB特征和孪生网络比较两个跟踪的行人的相似性。要想做到这样,需要1)独立的测度学习阶段,2)代价与相似度结合。下面本文使用了运动特征和外观特征。
运动特征(ALFD)
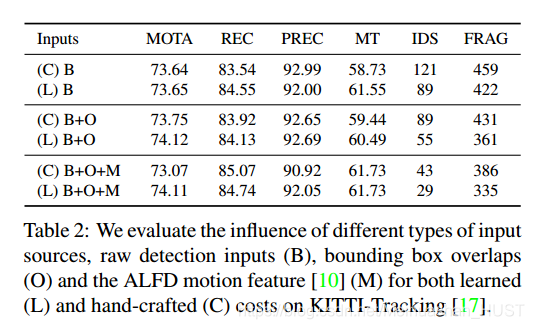
外观特征
将检测结果resize到128*64,然后提取深度特征Res-50和检测分数一起构成检测代价
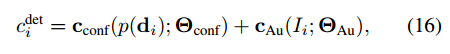
然后使用孪生网络得到两个检测结果的差异。2层的MLP(B+O)特征输入的,接在孪生网络差分层后面,最后一层预测clink。
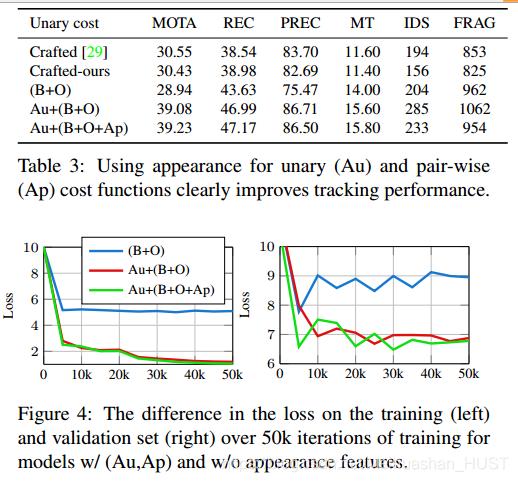
这里受限的是他的检测器用的ACF而不是基于深度网络的检测器
4.3 损失函数中的不同损失
4.4 结果 - 结论